
В видеокурсе из семи уроков описывается парсинг сайтов с различной структурой при помощи Python третьей версии, библиотек requests и BeautifulSoup.
В этом видеокурсе Олег Молчанов подробно, не торопясь, рассказывает про парсинг сайтов при помощи Python 3. Раскрываются особенности парсинга многостраничных ресурсов, использования прокси с различными User-Agent, сохранения изображений и распознавания простого текста, а также быстрый мультипроцессорный парсинг сайтов.
В ряде случаев предлагаемые автором программные решения несколько устарели из-за изменения структуры страниц, подвергаемых парсингу. Автор курса не преследует цели создать идеальный парсер, а лишь излагает определенные концепции и иллюстрирует их примерами. Для облегчения вашей работы, мы привели исходные коды программ, набранные нами во время прохождения курса, с некоторыми поправками.
1. Мультипроцессорный парсинг страницы сайта с экспортом данных в csv
https://www.youtube.com/watch?v=IGPUs49a1Zo
В уроке рассматривается мультипроцессорный парсинг на примере сайта CoinMarketCap.com. Сначала приводится пример однопоточного парсинга. Затем рассматривается, как модифицировать программу для реализации мультипроцессорного подхода при помощи библиотеки multiprocessing. Сравниваются временные интервалы, необходимые для парсинга в один и несколько потоков. Попутно рассказывается об экспорте данных в csv-файл.
Обратите внимание: для установки BeautifulSoup для Python 3 в видео указана неправильная команда. Правильный вариант: pip install beautifulsoup4 (либо для систем с двумя версиями Python: pip3 install beautifulsoup4).
Программный код при однопоточном парсинге:
import csv
from datetime import datetime
import requests
from bs4 import BeautifulSoup
def get_html(url):
response = requests.get(url)
return response.text
def get_all_links(html):
soup = BeautifulSoup(html, 'lxml')
tds = soup.find('table', id='currencies-all').find_all('td', class_='currency-name')
links = []
for td in tds:
a = td.find('a', class_='currency-name-container').get('href')
link = 'https://coinmarketcap.com' + a
links.append(link)
return links
def text_before_word(text, word):
line = text.split(word)[0].strip()
return line
def get_page_data(html):
soup = BeautifulSoup(html, 'lxml')
try:
name = text_before_word(soup.find('title').text, 'price')
except:
name = ''
try:
price = text_before_word(soup.find('div',
class_='col-xs-6 col-sm-8 col-md-4 text-left').text, 'USD')
except:
price = ''
data = {'name': name,
'price': price}
return data
def write_csv(i, data):
with open('coinmarketcap.csv', 'a') as f:
writer = csv.writer(f)
writer.writerow((data['name'],
data['price']))
print(i, data['name'], 'parsed')
def main():
start = datetime.now()
url = 'https://coinmarketcap.com/all/views/all'
all_links = get_all_links(get_html(url))
for i, link in enumerate(all_links):
html = get_html(link)
data = get_page_data(html)
write_csv(i, data)
end = datetime.now()
total = end - start
print(str(total))
a = input()
if __name__ == '__main__':
main()
Программный код при использовании мультипроцессорного парсинга с 40 процессами:
from multiprocessing import Pool
import csv
from datetime import datetime
import requests
from bs4 import BeautifulSoup
def get_html(url):
response = requests.get(url)
return response.text
def get_all_links(html):
soup = BeautifulSoup(html, 'lxml')
tds = soup.find('table', id='currencies-all').find_all('td', class_='currency-name')
links = []
for td in tds:
a = td.find('a', class_='currency-name-container').get('href')
link = 'https://coinmarketcap.com' + a
links.append(link)
return links
def text_before_word(text, word):
line = text.split(word)[0].strip()
return line
def get_page_data(html):
soup = BeautifulSoup(html, 'lxml')
try:
name = text_before_word(soup.find('title').text, 'price')
except:
name = ''
try:
price = text_before_word(soup.find('div',
class_='col-xs-6 col-sm-8 col-md-4 text-left').text, 'USD')
except:
price = ''
data = {'name': name,
'price': price}
return data
def write_csv(data):
with open('coinmarketcap.csv', 'a') as f:
writer = csv.writer(f)
writer.writerow((data['name'],
data['price']))
print(data['name'], 'parsed')
def make_all(link):
html = get_html(link)
data = get_page_data(html)
write_csv(data)
def main():
start = datetime.now()
url = 'https://coinmarketcap.com/all/views/all'
all_links = get_all_links(get_html(url))
with Pool(40) as p:
p.map(make_all, all_links)
end = datetime.now()
total = end - start
print(str(total))
a = input()
if __name__ == '__main__':
main()
Характерные времена могут разниться в зависимости от оборудования и текущего состояния сайта.
2. Парсинг многостраничных сайтов
https://www.youtube.com/watch?v=zlWiw99bBUk
Во втором уроке рассматривается извлечение информации с многостраничного сайта по типу Avito.ru. В качестве примера берется задача поиска телефона по названию фирмы изготовителя с выводом названия товара, цены, ближайшей станции метро и ссылки объявления. Показывается простейший способ фильтрации нерелевантных блоков.
Обратите внимание: при многостраничном парсинге таких сайтов, как Avito.ru, ваш IP может быть временно забанен на совершение парсинга.
import requests
from bs4 import BeautifulSoup
import csv
def get_html(url):
r = requests.get(url)
return r.text
def get_total_pages(html):
soup = BeautifulSoup(html, 'lxml')
divs = soup.find('div', class_='pagination-pages clearfix')
pages = divs.find_all('a', class_='pagination-page')[-1].get('href')
total_pages = pages.split('=')[1].split('&')[0]
return int(total_pages)
def write_csv(data):
with open('avito.csv', 'a') as f:
writer = csv.writer(f)
writer.writerow((data['title'],
data['price'],
data['metro'],
data['url']))
def get_page_data(html):
soup = BeautifulSoup(html, 'lxml')
divs = soup.find('div', class_='catalog-list')
ads = divs.find_all('div', class_='item_table')
for ad in ads:
try:
div = ad.find('div', class_='description').find('h3')
if 'htc' not in div.text.lower():
continue
else:
title = div.text.strip()
except:
title = ''
try:
div = ad.find('div', class_='description').find('h3')
url = "https://avito.ru" + div.find('a').get('href')
except:
url = ''
try:
price = ad.find('div', class_='about').text.strip()
except:
price = ''
try:
div = ad.find('div', class_='data')
metro = div.find_all('p')[-1].text.strip()
except:
metro = ''
data = {'title':title,
'price':price,
'metro':metro,
'url':url}
write_csv(data)
def main():
url = "https://avito.ru/moskva/telefony?p=1&q=htc"
base_url = "https://avito.ru/moskva/telefony?"
page_part = "p="
query_par = "&q=htc"
# total_pages = get_total_pages(get_html(url))
for i in range(1, 3):
url_gen = base_url + page_part + str(i) + query_par
html = get_html(url_gen)
get_page_data(html)
if __name__ == '__main__':
main()
3. Извлечение информации из генерируемых сайтом изображений
https://www.youtube.com/watch?v=ucTPsHW1914
Во второй части видео о парсинге Avito внимание фокусируется на совмещении парсинга с извлечением информации из изображений. Для этой задачи вместо библиотеки BeautifulSoup используется библиотека Selenium, работающая непосредственно с браузером на вашем компьютере. Для совместной работы может потребоваться файл драйвера браузера. Захват изображений и преобразование в текстовые строки осуществляется при помощи библиотек pillow и pytesseract.
from selenium import webdriver
from time import sleep
from PIL import Image
from pytesseract import image_to_string
class Bot:
def __init__(self):
self.driver = webdriver.Chrome() # or Firefox() or smth else
self.navigate()
def take_screenshot(self):
self.driver.save_screenshot('avito_screenshot.png')
def tel_recon(self):
image = Image.open('tel.gif')
print(image_to_string(image))
def crop(self, location, size):
image = Image.open('avito_screenshot.png')
x = location['x']
y = location['y']
width = size['width']
height = size['height']
image.crop((x, y, x+width, y+height)).save('tel.gif')
self.tel_recon()
def navigate(self):
self.driver.get('https://www.avito.ru/velikie_luki/telefony/lenovo_a319_1161088336')
button = self.driver.find_element_by_xpath(
'//button[@class="button item-phone-button js-item-phone-button
button-origin button-origin-blue button-origin_full-width
button-origin_large-extra item-phone-button_hide-phone
item-phone-button_card js-item-phone-button_card"]')
button.click()
sleep(3)
self.take_screenshot()
image = self.driver.find_element_by_xpath(
'//div[@class="item-phone-big-number js-item-phone-big-number"]//*')
location = image.location
size = image.size
self.crop(location, size)
def main():
b = Bot()
if __name__ == '__main__':
main()
4. Приемы работы с библиотекой BeautifulSoup
https://www.youtube.com/watch?v=3hgkiDAaSQs
В этом видео на более абстрактном примере локальной страницы даны дополнительные примеры работы методов find и find_all библиотеки BeautifulSoup. Показывается, как находить включающие информацию блоки при помощи методов parent, find_parent и find_parents. Описаны особенности работы методов next_element и next_sibling, упрощающих поиск данных в пределах одного раздела. В конце видео рассматривается, как сочетать поиск в BeautifulSoup с регулярными выражениями.
5. Использование прокси и изменение User-Agent
https://www.youtube.com/watch?v=MKq3u9NbpYE
В пятом видео анализируется основной прием, помогающий избежать при парсинге бана или появления капчи посредством использования прокси-сервера с меняющимся адресом и изменения параметра User-Agent. Демонстрируется пример использования метода find_next_sibling. Рассмотрена передача IP и User-Agent при запросе библиотеки requests. Для использования актуального списка доступных прокси-серверов мы рекомендуем дополнить код парсером соответствующего сайта (в видео используются заранее подготовленные файлы со списками прокси и браузерных агентов).
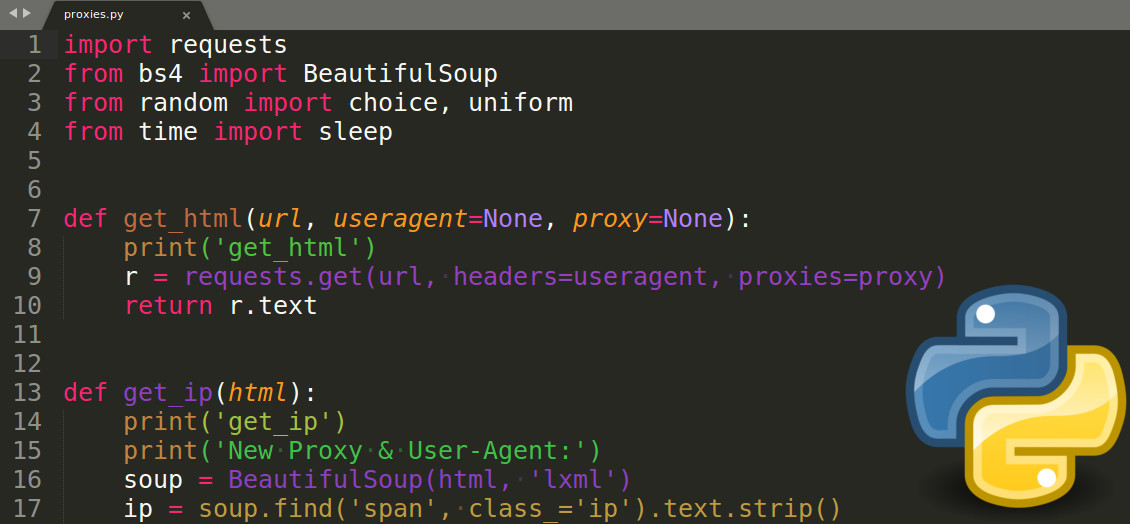
import requests
from bs4 import BeautifulSoup
from random import choice, uniform
from time import sleep
def get_html(url, useragent=None, proxy=None):
print('get_html')
r = requests.get(url, headers=useragent, proxies=proxy)
return r.text
def get_ip(html):
print('get_ip')
print('New Proxy & User-Agent:')
soup = BeautifulSoup(html, 'lxml')
ip = soup.find('span', class_='ip').text.strip()
ua = soup.find('span', class_='ip').find_next_sibling('span').text.strip()
print(ip)
print(ua)
print('---------------------------')
def main():
url = 'https://sitespy.ru/my-ip'
useragents = open('useragents.txt').read().split('\n')
proxies = open('proxies.txt').read().split('\n')
for i in range(10):
# sleep(uniform(3, 6))
proxy = {'http': 'http://' + choice(proxies)}
useragent = {'User-Agent': choice(useragents)}
try:
html = get_html(url, useragent, proxy)
except:
continue
get_ip(html)
if __name__ == '__main__':
main()
6. Парсинг сайтов с «ненормальной» структурой
https://www.youtube.com/watch?v=BLCmWzFbC0E
В этом видеоуроке на примере двух сайтов объясняется, как обрабатывать сайты с ошибками или сайты, сделанные непрофессионалами. Первый ресурс https://us-proxy.org/ представляет пример сайта, который выглядит как многостраничный, но это лишь видимость – все данные загружаются на главную страницу при первом обращении к сайту. Во втором примере в структуре блога http://startapy.ru/ используется три вертикальных списка с необычным горизонтальным смещением размещаемых блоков при добавлении новых публикаций. В видеоуроке показано, как средства анализа браузеров в связи с некорректной версткой могут вводить нас в заблуждение, при том что BeautifulSoup отображает и использует исправленный вариант.
7. Скачивание изображений и других файлов
https://www.youtube.com/watch?v=8vwoc0n6Isc
На примере сайта со свободными изображениями для фона рабочего стола https://www.hdwallpapers.in/ показывается процедура загрузки изображений с сайта – каждого в отдельную папку. Используются только библиотеки os (для работы с заданием пути сохранения файла) и requests. Показывается работа с блочной загрузкой файлов посредством метода iter_content.
import os
import requests
# url = 'https://www.hdwallpapers.in/thumbs/2018/spiral_silver_metal-t1.jpg'
# r = requests.get(url, stream=True) # stream for partial download
# with open('1.jpg', 'bw') as f:
# for chunk in r.iter_content(8192):
# f.write(chunk)
urls = [
'https://www.hdwallpapers.in/walls/messier_106_spiral_galaxy_5k-wide.jpg',
'https://www.hdwallpapers.in/walls/helix_nebula_5k-wide.jpg',
'https://www.hdwallpapers.in/walls/orion_nebula_hubble_space_telescope_5k-wide.jpg',
'https://www.hdwallpapers.in/walls/solar_space-wide.jpg'
]
def get_file(url):
r = requests.get(url, stream=True)
return r
def get_name(url):
name = url.split('/')[-1]
folder = name.split('.')[0]
if not os.path.exists(folder):
os.makedirs(folder)
path = os.path.abspath(folder)
return path + '/' + name
def save_image(name, file_object):
with open(name, 'bw') as f:
for chunk in file_object.iter_content(8192):
f.write(chunk)
def main():
for url in urls:
save_image(get_name(url), get_file(url))
if __name__ == '__main__':
main()


Комментарии