
Три доклада с конференции Data Fest 4, объединяющей исследователей, инженеров и разработчиков, связанных с Data Science.
Михаил Коробов и Константин Лопухин (Scrapinghub) "Как собрать датасет из интернета"
Часть 1
Анализ данных предполагает, в первую очередь, наличие этих данных. Первая часть доклада рассказывает о том, что делать, если у вас не имеется готового/стандартного датасета, либо он не соответствует тому, каким должен быть. Наиболее очевидный вариант - скачать данные из интернета. Это можно сделать множеством способов, начиная с сохранения html-страницы и заканчивая Event loop (моделью событийного цикла). Последний основан на параллелизме в JavaScript, что позволяет значительно повысить производительность. В парсинге event loop реализуется с помощью технологии AJAX, утилит вроде Scrapy или любого асинхронного фреймворка.
Извлечение данных из html связано с обходом дерева, который может осуществляться с применением различных техник и технологий. В докладе рассматриваются три «языка» обхода дерева: CSS-селекторы, XPath и DSL. Первые два состоят в довольно тесном родстве и выигрывают за счет своей универсальности и широкой сфере применения. DSL (предметно-ориентированный язык, domain-specific language) для парсинга существует довольно много, и хороши они, в первую очередь, тем, что удобство работы с ним осуществляется благодаря поддержке IDE и валидации со стороны языка программирования.
Для тренировки написания пауков компанией ScrapingHub создан учебный сайт toscrape.com, на примере которого рассматривается парсинг книжного сайта. С помощью chrome-расширения SelectorGadget, которое позволяет генерировать CSS-селекторы, выделяя элементы на странице, можно облегчить написание скрапера.
Пример с использованием scrapy:
import scrapy
class BookSpider(scrapy.Spider):
name = 'books'
start_urls = ['http://books.toscrape.com/']
def parse(self, response):
for href in response.css('.product_pod a::attr(href)').extract():
url = response.urljoin(href)
print(url)
Пример без scrapy:
import json
from urllib.parse import urljoin
import requests
from parsel import Selector
index = requests.get('http://books.toscrape.com/')
books = []
for href in Selector(index.text).css('.product_pod a::attr(href)').extract():
url = urljoin(index.url, href)
book_page = requests.get(url)
sel = Selector(book_page.text)
books.append({
'title': sel.css('h1::text').extract_first(),
'price': sel.css('.product_main .price_color::text')extract_first(),
'image': sel.css('#product_gallery img::attr(src)').extract_first()
})
with open('books.json', 'w') as fp:
json.dump(books, fp)
Некоторые сайты сами помогают парсингу с помощью специальных тегов и атрибутов html. Легкость парсинга улучшает SEO сайта, так как при этом обеспечивается большая легкость поиска сайта в сети.
Часть 2
О скорости скачивания страниц, распределении на процессы и способах их координации. При больших объемах выборки данных важно оптимизировать скорость и частоту запросов таким образом, чтобы не положить сайт и не быть заблокированным за бомбардировку автоматическими запросами. Это может быть реализовано путем разбиения на несколько процессов: например, разделив между ними url-ы, чтобы в рамках одного процесса осуществлялся парсинг одного сайта. Еще один вариант - общая очередь, куда помещаются запросы и достаются по мере необходимости.
Какие существуют варианты хранения полученных данных? Можно извлекать информацию сразу, либо сохранять HTML-страницы для последующей обработки в исходном (около 100КБ) или сжатом (15 КБ) размере. Порядок обхода сайта для извлечения данных зависит от его объема и структуры. Большинство современных сайтов представляют собой весьма сложные конфигурации большого числа страниц со ссылками друг на друга, напоминающие паутину. Две стандартные стратегии обхода: в глубину и в ширину. Плюсы и минусы обхода в глубину:
- небольшой размер очереди запросов
- удобен для краулера одного сайта
- может не подойти для обхода всех ссылок (т.к. глубина может быть очень большой или бесконечной)
Особенности в ширину:
- подходит для обхода всех ссылок на сайте
- большой размер очереди
- реальная глубина - 2-4
- возможные проблемы глубины в графе ссылок
Вторая часть доклада посвящена примерам ресурсов, предоставляющих готовые датасеты, собранные со всего интернета. В базе данных Common Crawl, например, хранится около 300 ТБ информации, которая обновляется каждый месяц. Сервис Web Data Commons извлекает из Common Crawl структурированные данные.
Дмитрий Сергеев (ZeptoLab) "Написание пауков, или что делать, когда тебя вычисляют по IP"
Как вести себя, если при сборе данных сервер блокирует ваши автоматические запросы, выдавая ошибки 403, 404, 503 и так далее? Во-первых, нужно запастись терпением и пожертвовать частотой отправки запросов. Ни один уважающий себя сервер не потерпит бесцеремонной продолжительной бомбардировки автоматическими запросами. Докладчик столкнулся с этим лично, проводя на досуге исследование популярности мемов на одном из популярных информационных ресурсов. Будучи заблокированным по IP, он написал письмо в техподдержку с просьбой разбанить его, на что получил автоматический ответ о разблокировке. Подумав, что, если ему отвечает автомат, то и просить о разблокировке можно автоматически, он написал бота, который при каждом бане отправлял поддержке письмо с текущим IP и слезной просьбой о разбане. Автоматы переписывались всю ночь, в течение которой докладчик выяснил, что время ожидания разбана растет экспоненциально.
Постепенно он учился быть похожим на человека не нарушая трех законов робототехники имитируя браузер: ставя временны′е заглушки перед запросами (при заполнении форм, кликах на кнопки, переходе по страницам, параллельных запросах и т.д.):
time.sleep(3)
генерируя случайные юзер-агенты:
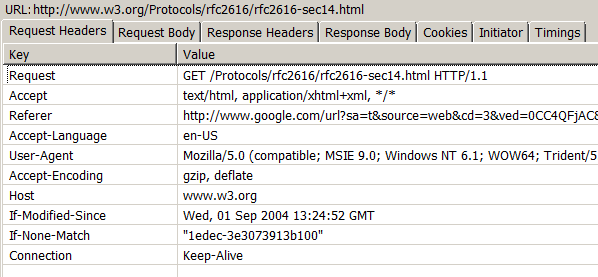
и используя Tor для многоуровневой переадресации:
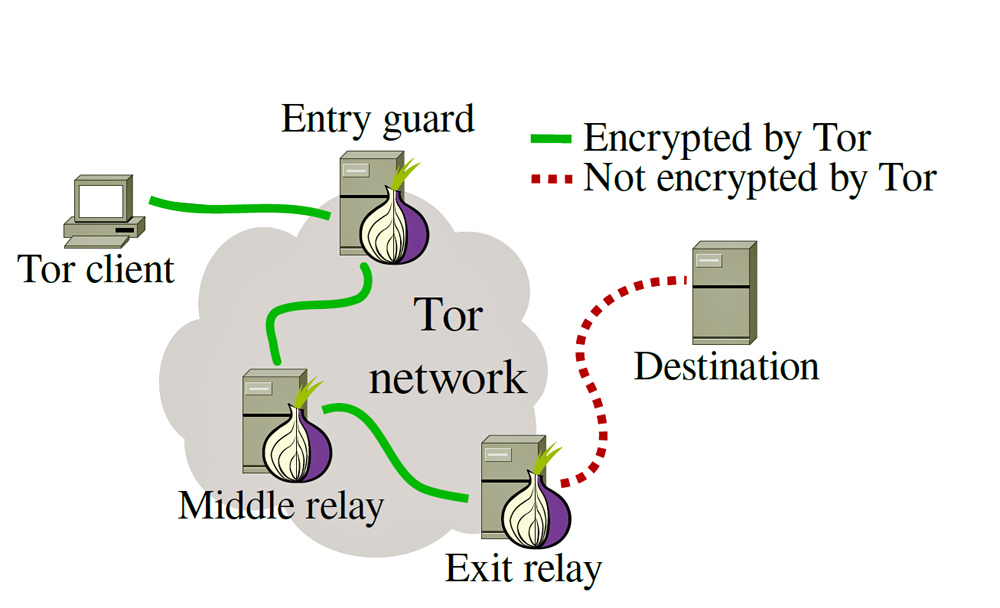
Комбинация этих методов позволяет достичь желаемого объема полученной информации без потери времени на баны и ожидание разблокировки.
Пример
Пример кода, который использует генератор хэдеров и тор для определения текущего IP-адреса:
import os
import socket
import requests
import time
import socks
import stem.process
from stem import Signal
from stem.control import Controller
from user_agent import generate_user_agent
current_time = lambda: int(round(time.time()))
class Network:
def switch_ip(self):
self.controller.signal(Signal.NEWNYM)
print("Switching IP. Waiting.")
t = current_time()
time.sleep(self.controller.get_newnym_wait())
print("{0}s gone".format(current_time() - t))
def print_bootstrap_lines(self, line):
print(line)
def init_tor(self, password='supersafe', log_handler=None):
self.tor_process = None
self.controller = None
try:
self.tor_process = stem.process.launch_tor_with_config(
tor_cmd=self.tor_path,
config=self.tor_config,
init_msg_handler=log_handler
)
self.controller = Controller.from_port(port=self.SOCKS_PORT + 1)
self.controller.authenticate(password)
except:
if self.tor_process is not None:
self.tor_process.terminate()
if self.controller is not None:
self.controller.close()
raise RuntimeError('Failed to initialize Tor')
socket.socket = self.proxySocket
def kill_tor(self):
print('Killing Tor process')
if self.tor_process is not None:
self.tor_process.kill()
if self.controller is not None:
self.controller.close()
def __init__(self):
# путь к директории файлов браузера Tor. В данном случае, директория для OS X
TOR_DIR = '/Applications/TorBrowser.app/Contents/Resources/TorBrowser/Tor/'
PASS_HASH = '16:DEBBA657C88BA8D060A5FDD014BD42DB7B5B736C0C248422F37C46B930'
IP_ADDRESS = '127.0.0.1'
self.SOCKS_PORT = 9150
self.tor_config = {
'SocksPort': str(self.SOCKS_PORT),
'ControlPort': str(self.SOCKS_PORT + 1),
'HashedControlPassword': PASS_HASH,
'GeoIPFile': os.path.join(TOR_DIR, 'geoip'),
'GeoIPv6File': os.path.join(TOR_DIR, 'geoip6')
}
self.tor_path = os.path.join(TOR_DIR, 'tor')
# Setup proxy
socks.setdefaultproxy(socks.PROXY_TYPE_SOCKS5, IP_ADDRESS, self.SOCKS_PORT)
self.nonProxySocket = socket.socket
self.proxySocket = socks.socksocket
def main():
try:
network = Network()
network.init_tor('supersafe', network.print_bootstrap_lines)
url = 'http://checkip.amazonaws.com/'
headers = {'User-Agent': generate_user_agent()}
req = requests.get(url, headers=headers)
print(req.content)
network.switch_ip()
req = requests.get(url, headers=headers)
print(req.content)
finally:
network.kill_tor()
if __name__ == "__main__":
main()

Комментарии