
Хотите стать мастером в Python? Тогда изучайте язык на практике. В этом материале рассказываем, как создать блокировщик веб-сайтов Python.

Python − это круто, он позволяет создавать высоконагруженные приложения, анализировать данные. Но прежде, чем заниматься столь сложными вещами, стоит научиться чему-нибудь попроще. В этой статье мы расскажем, как создать блокировщик веб-сайтов на Python с базовыми структурами данных и файловыми операциями − это позволит сформировать понимание того, как реализовывать основные концепции Python.
Шаг №1 - Путь к hosts
Cначала найдите путь к файлу hosts (для Windows − C:\Windows\System32\ drivers\etc\hosts и для Linux − etc/hosts). Если вы хорошо разбираетесь в компьютерах, скорее всего, вы уже играли с этим файлом. Но если нет, то стоит знать, что файл hosts может использоваться для работы с IP-адресами.
Теперь нужно настроить, на какой IP будет перенаправляться пользователь при попадании на определённые сайты:
host_path = "/etc/hosts" redirect = "127.0.0.1" website_list = ["www.netflix.com","www.facebook.com"]
Шаг №2 − Rihanna и Drake
Среда установлена. Теперь, нужно определить, в какое время ресурсы будут заблокированы. Допустим, в рабочее время. Как это сделать? Должны быть часы работы, верно? Не вручную, конечно: мы будем использовать собственную библиотеку даты и времени Python для извлечения текущего времени при исполнении кода.
Циклы позволяют выполнять код быстро. Мы проверяем, сколько сейчас времени, и если оказывается, что сейчас от 8:00 до 16:00, то на экран выводится Rihanna, которая поёт о том, что нужно работать. А если появляется Drake, то можно развлекаться. .time.sleep(5) добавляет задержку в пять секунд, это нужно для нормальной работы циклов.
Примечание: в целях безопасности скопируйте файл hosts в рабочий каталог и укажите путь к этому файлу, а не к исходному. Как только мы получим то, что нам нужно, можно будет изменить путь к исходному файлу.
import time
from datetime import datetime as dt
host_path = "/etc/hosts"
redirect = "127.0.0.1"
website_list = ["www.netflix.com","www.facebook.com"]
while True:
ymd = (dt.now().year, dt.now().month, dt.now().day)
if dt(*ymd, 8) < dt.now() < dt(*ymd,16):
print("Rihanna")
else:
print("Drake")
time.sleep(5)
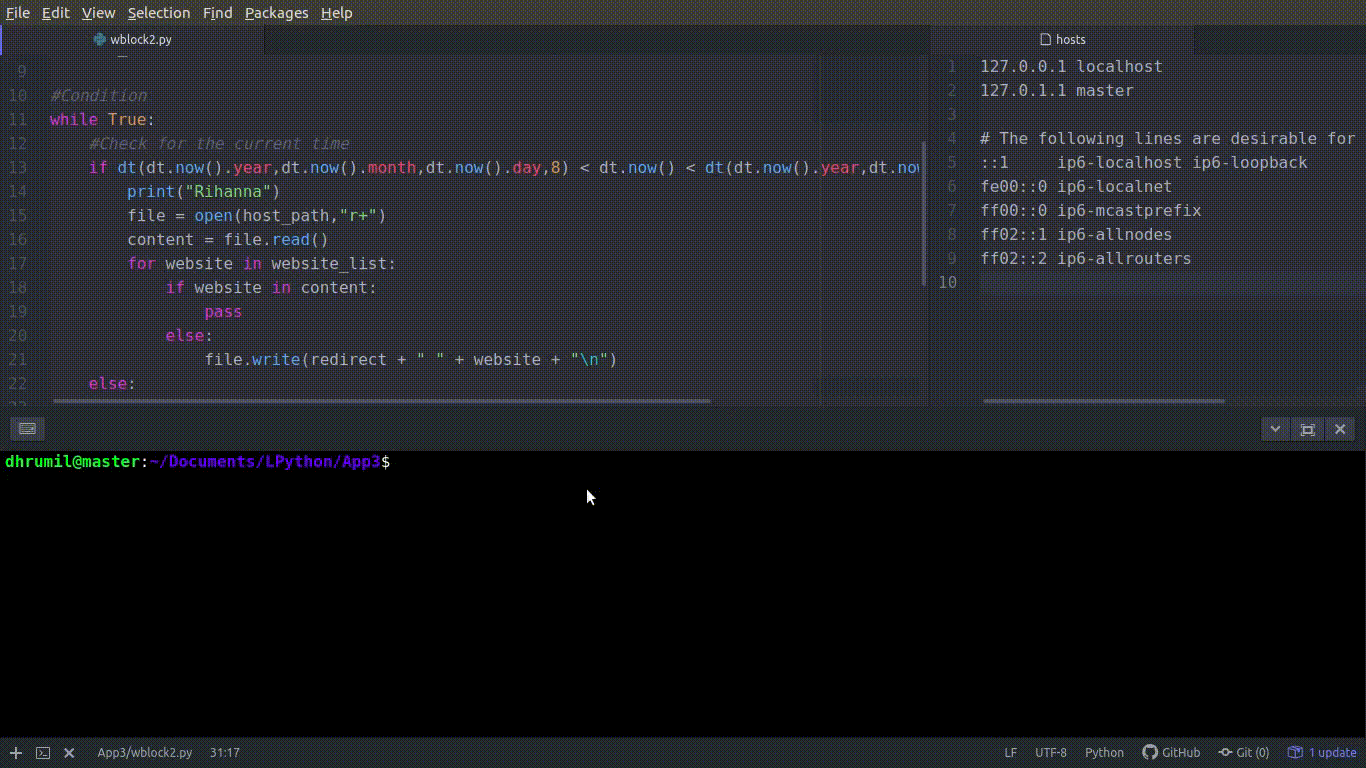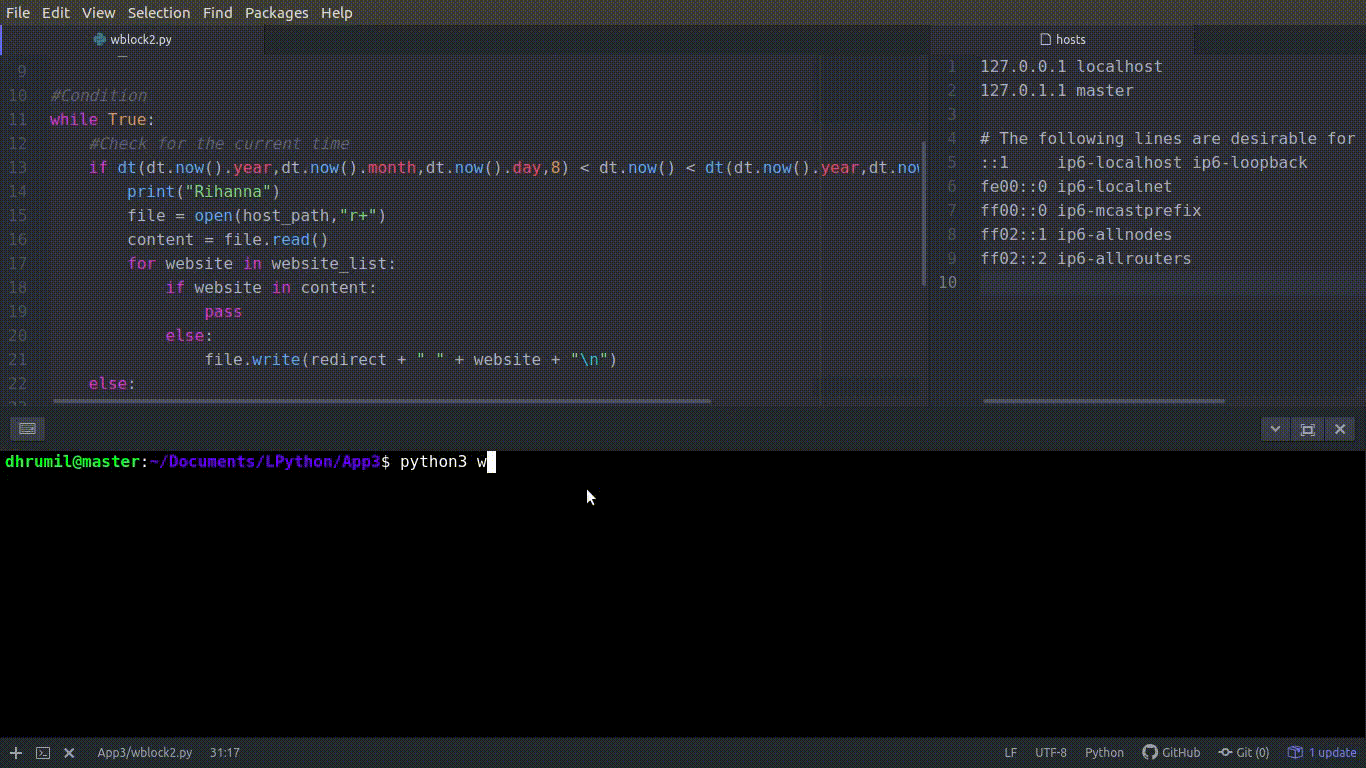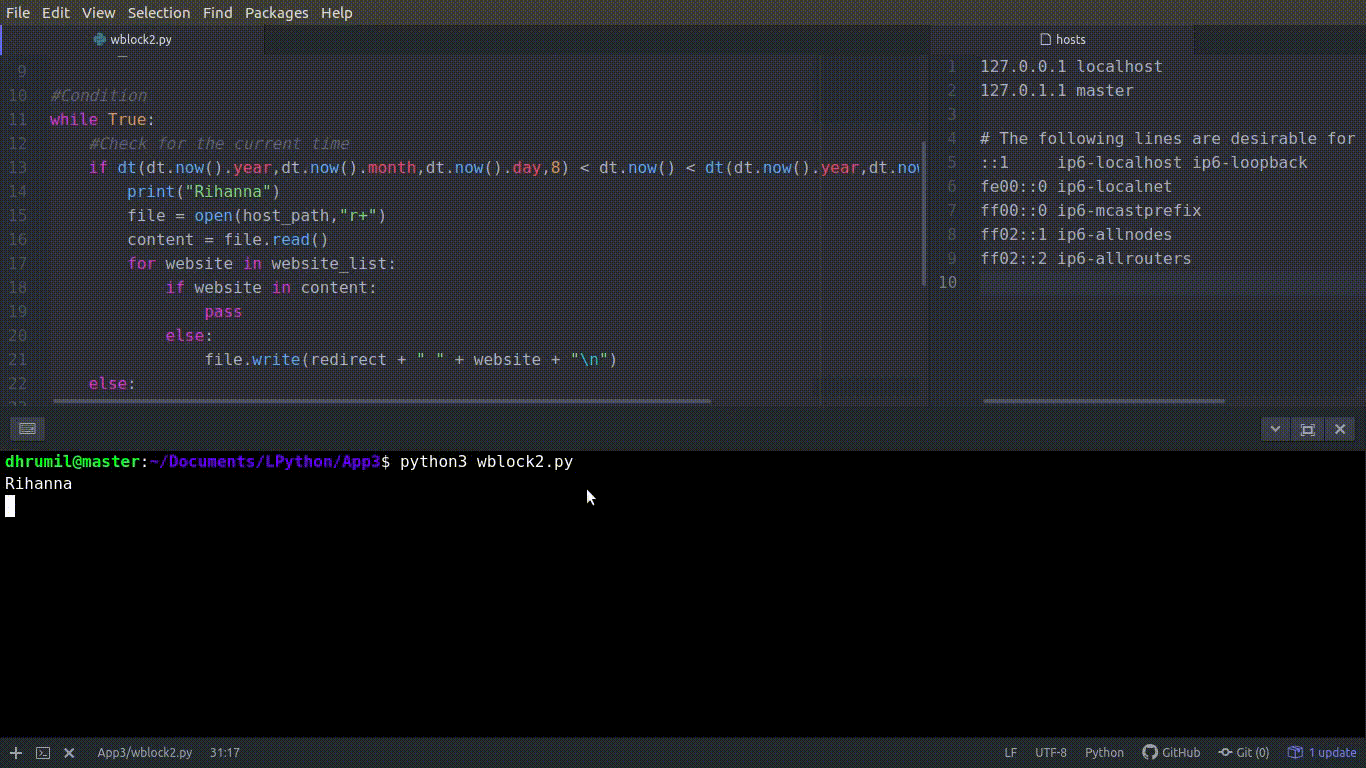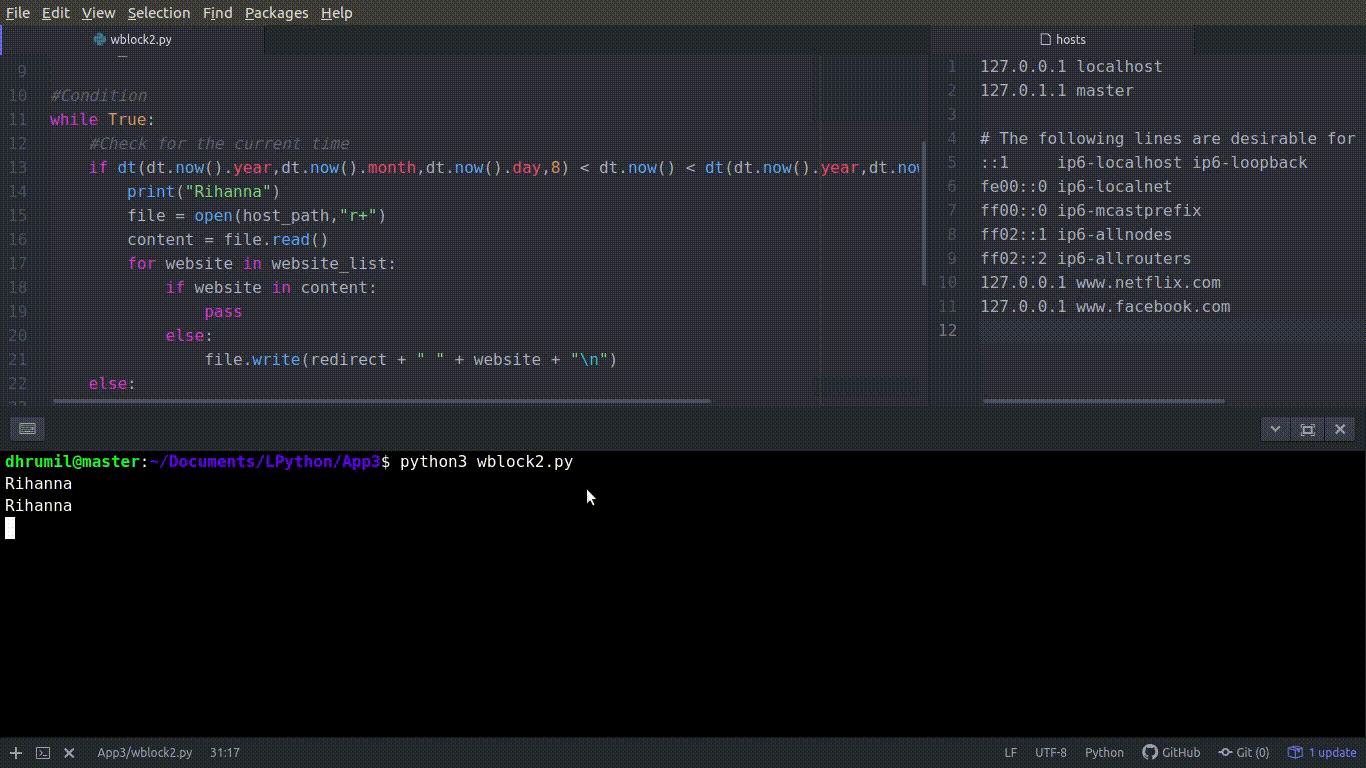
Давайте перейдем к последнему шагу блокировки веб-сайтов. Мы собираемся использовать базовые операции чтения и записи файлов в Python. Процесс состоит из двух частей: сначала происходит блокировка, потому что начинается рабочий день, а затем разблокировка, потому что время отдыхать.
Получаем текущее время. Сначала мы открываем файл, затем изучаем его содержимое и сохраняем в переменной «content». r+ и путь файлу − это разрешение на чтение и запись из файла и в файл. Вы открыли файл, прочитали содержание, и что теперь? Проверьте, есть ли сайт в файле, и если нет, добавьте его туда. Первая часть завершена, сайты из списков заблокированы. Вот что происходит в коде:
while True:
if dt(dt.now().year,dt.now().month,dt.now().day,8) < dt.now() < dt(dt.now().year,dt.now().month,dt.now().day,16):
print("Rihanna")
file = open(host_path,"r+")
content = file.read()
for website in website_list:
if website in content:
pass
else:
file.write(redirect + " " + website + "\n")
else:
print("Drake")
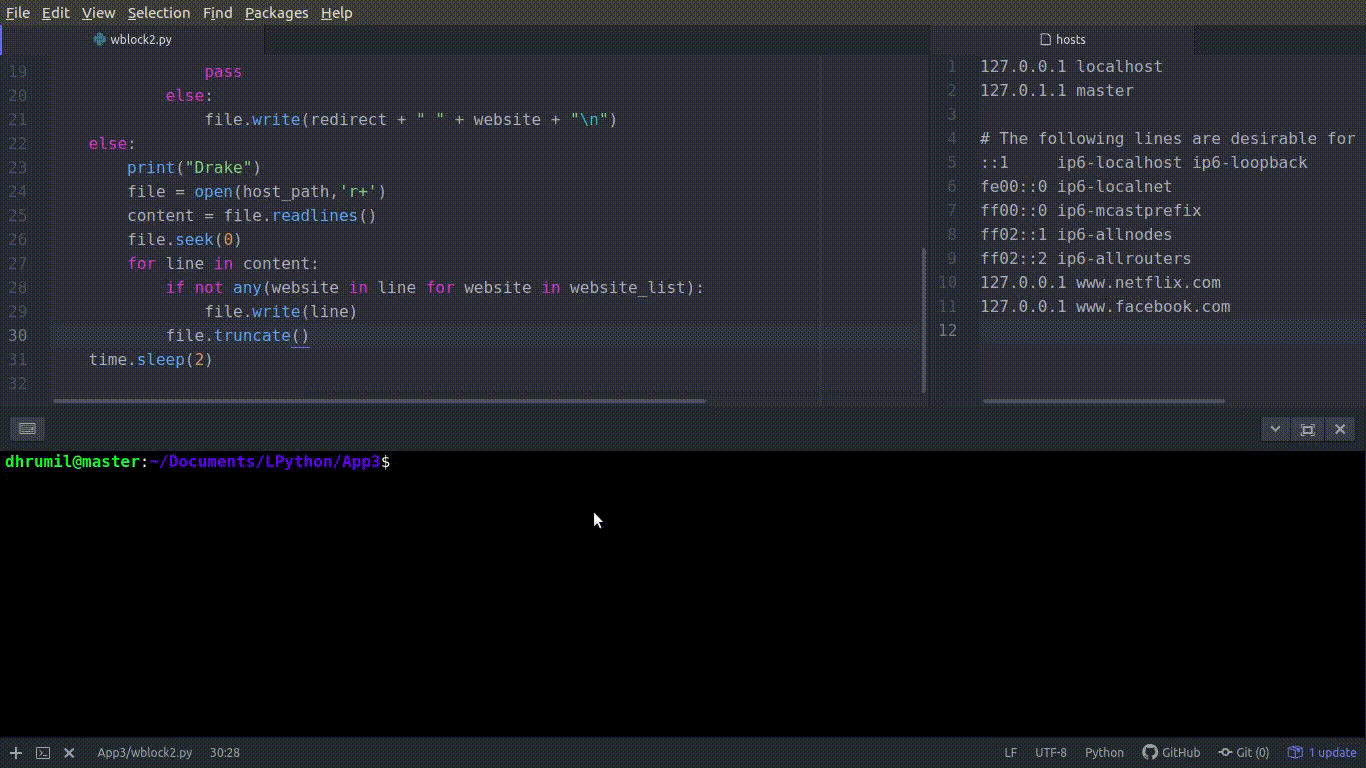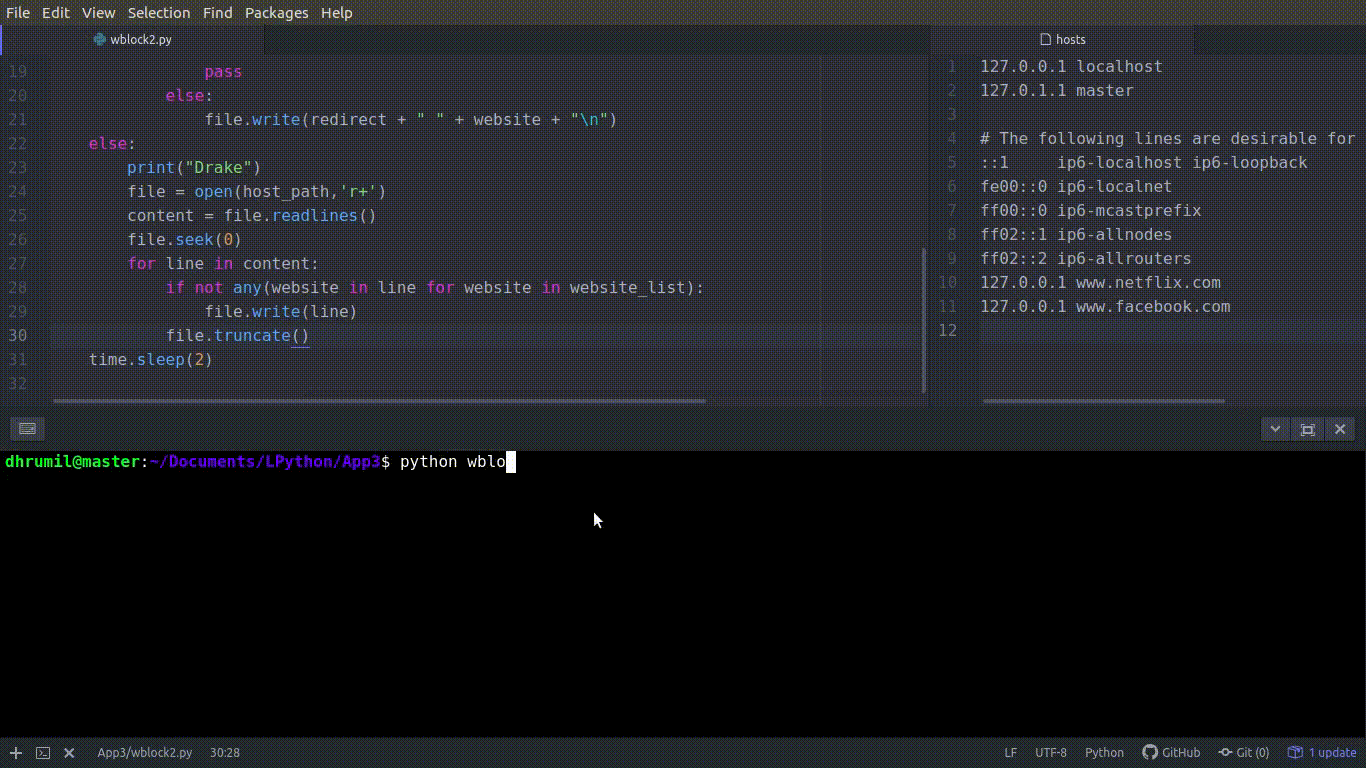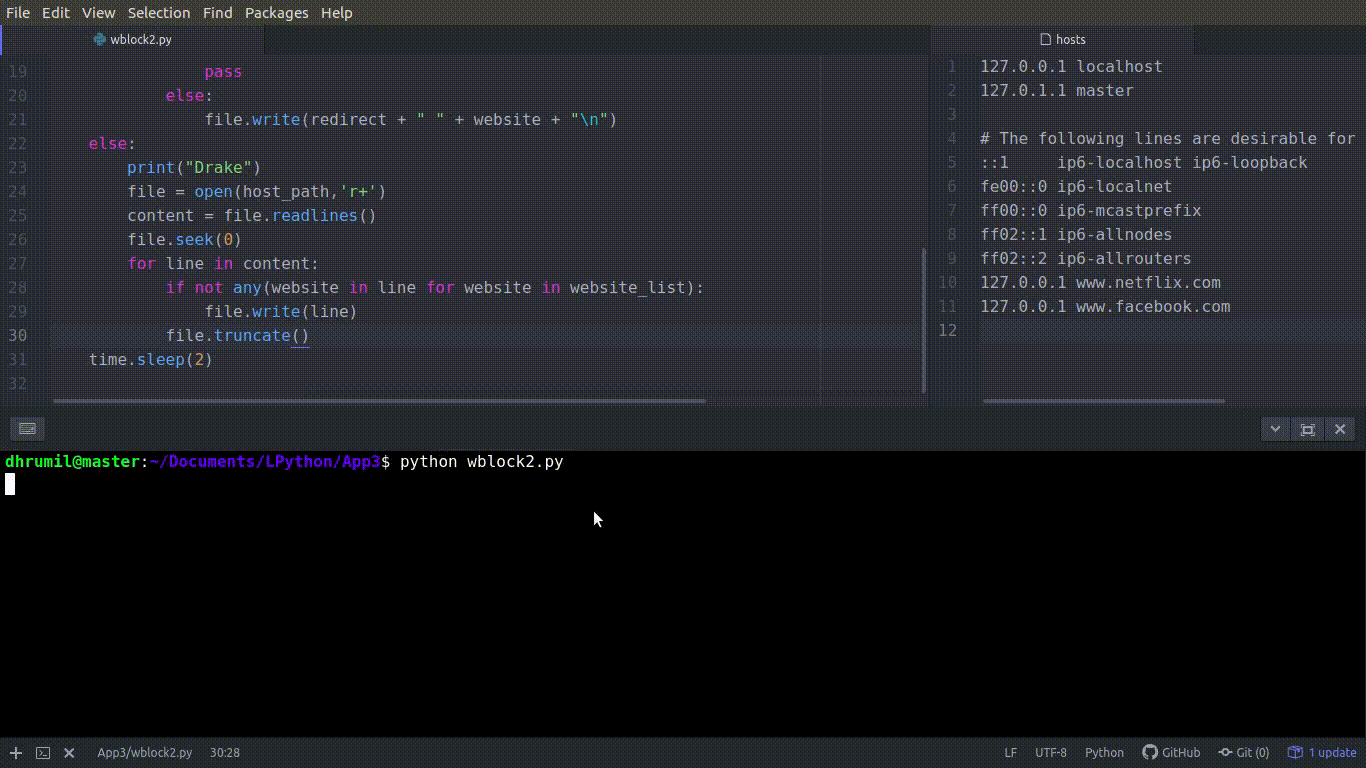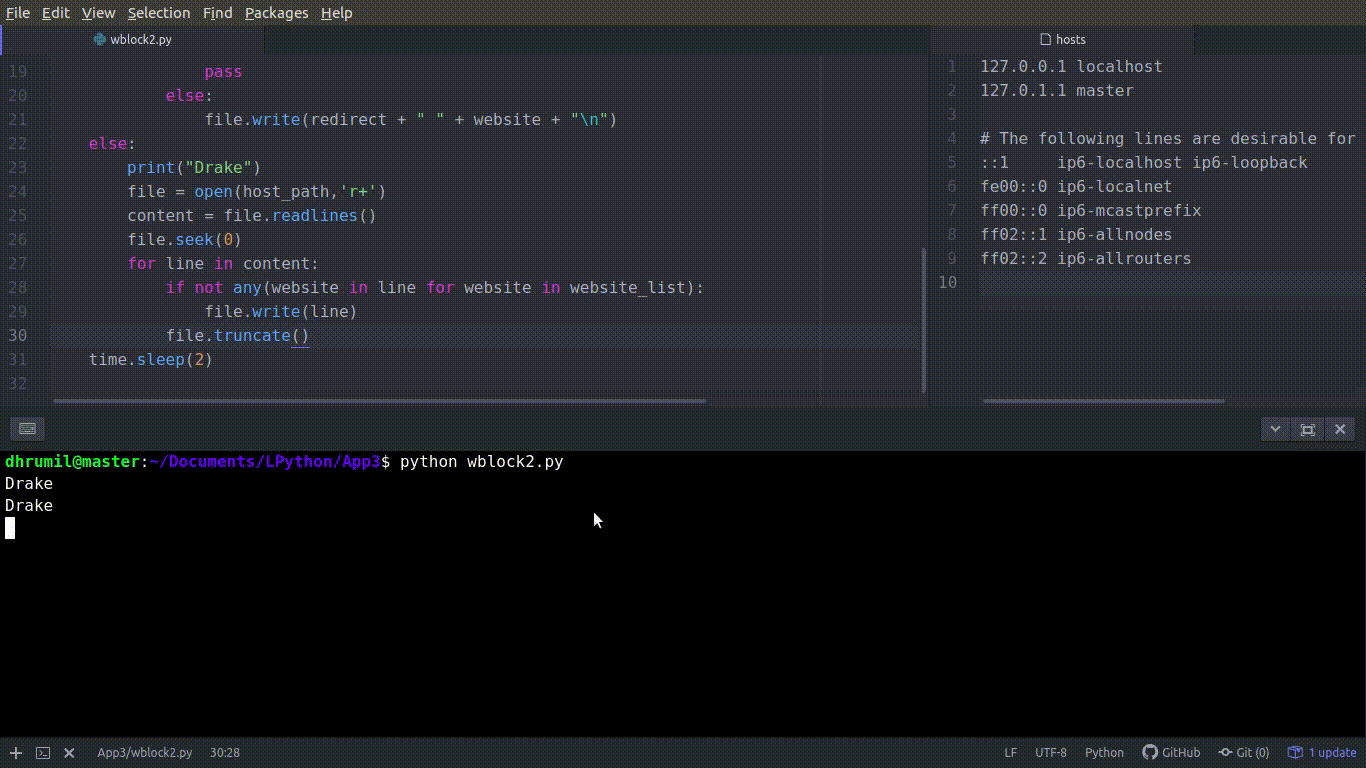
Когда приходит время расслабиться и посмотреть Netflix, можно разблокировать наши веб-сайты. По сути, нужно удалить те сайты, которые мы добавили в файл. Для этого откроем файл и будем читать записи построчно с помощью file.readlines(). file.seek(0) используется, чтобы поместить указатель в исходное положение файла. Если наш веб-сайт из списка на блокировку отсутствует в строке файла хоста, добавьте эту строку. Если в строке есть наш веб-сайт, игнорируйте её. Так можно реализовать удаление сайта из списка блокировки.
else:
print("Drake")
file = open(host_path,'r+')
content = file.readlines()
file.seek(0)
for line in content:
if not any(website in line for website in website_list):
file.write(line)
file.truncate()
time.sleep(5)
Ещё чуть-чуть
Вы проделали большую работу по созданию блокировщика сайтов, но выполнять код для блокировки сайтов кажется плохой идеей, верно? Вот почему мы будем использовать планировщик задач для выполнения этой работы. Обратимся за помощью к Cron Job Scheduler (он предварительно установлен в операционной системе, вам не нужно ничего устанавливать). Просто откройте cron с разрешением sudo и параметром -e.

Добавьте путь к нашему основному файлу, а затем − команду @reboot.
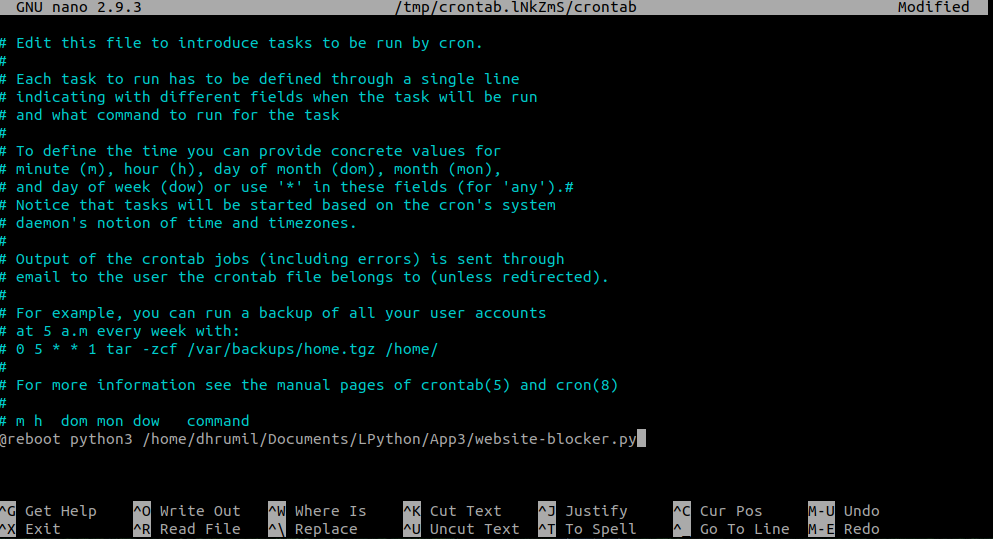
Готово! Сайты из списка успешно заблокированы. Перезагрузите компьютер, чтобы увидеть изменения.
Блокировщики веб-сайтов широко распространены в наши дни, и вы можете легко найти их в магазине приложений своего браузера в качестве расширения. Но кто знает, как эти вещи на самом деле работают? А тут всё понятно − найти код этого приложения можно на GitHub.
Понравился материал о том, как сделать блокировщик веб-сайтов на Python? Другие статьи по теме:
- NLP – это весело! Обработка естественного языка на Python
- Крупнейшая подборка Python-каналов на Youtube
- TOП-50 Python-проектов в 2018: самые востребованные инструменты
Книги по Python:
- 13 лучших книг по Python для начинающих и продолжающих
- 7 книг, которые стоит прочесть для изучения Python
- ТОП-10 книг по Python: эффективно, емко, доходчиво
Источник: Учимся Python на практике − создаём блокировщик веб-сайтов на Python on Towards Data Science


Комментарии