

Текст публикуется в переводе, автор статьи – Патрик Мейер.
Вы читаете презентацию состояния дел на переднем крае синтеза речи в конце мая 2021-го года, с упором на технологии глубокого обучения. Я представлю синтез 71 научной публикации и объяснения, необходимые для понимания основных концепций.
Введение
В этой статье мы обсудим передовое состояние методов синтеза речи на данный момент. Я представлю методы, используемые для автоматической генерации звуковых сигналов на основе текстовых предложений. После этой краткой презентации я представлю проблемы, возникающие при синтезе речи, затем типовые последовательности обработки текста. Я кратко объясню, что такое мел-спектрограммы, глубокие генеративные модели, комплексные системы, кто является основными исследователями на сегодняшний день, и какие наборы данных позволяют проводить обучение. Я объясню, как измеряется качество, и на каких конференциях представляются основные труды. Наконец, мы поговорим о задачах, которые еще не решены.
Краткое содержание
Генерация сигнала обычно проводится в два этапа: на первом генерируется частотное представление предложения (мел-спектрограмма), а на втором из этого представления формируется звуковая волна. На первом этапе текст преобразуется в символы или фонемы, которые затем векторизуются. Затем нейронная сеть с архитектурой "энкодер-декодер" преобразует эти входные элементы в сжатое внутреннее представление (энкодер) и обратно преобразует в частотное представление (декодер). На этом этапе чаще всего используются сверточные нейронные сети с механизмами внимания, чтобы повысить уровень соответствия между входом и выходом. Это соответствие часто усиливается механизмами предсказания длительности, громкости и тона. На втором этапе так называемый вокодер преобразует трехмерное представление звука (время, частота и сила) в звуковой сигнал. Одни из самых эффективных архитектур – архитектуры GAN (генеративные состязательные сети), в которых генератор генерирует сигналы, которые будет классифицировать дискриминатор.
Когда эти архитектуры оцениваются человеком, уровень качества сгенерированного звука почти достигает уровня тренировочных данных. Поскольку превзойти уровень входных данных трудно, исследования в настоящее время направлены на такие элементы звука, как интонацию, ритм и личные особенности, а также более точная настройка параметров генерации звука, которые сделают сгенерированную речь еще более реалистичной.
Виртуальные голосовые помощники
Больше трех лет назад (в мае 2018-го) исполнительный директор Google Сандар Пичаи (Sundar Pichai) на семинаре по Google I/O представил телефонную запись разговора голосового помощника (Google Duplex) с работником парикмахерского салона. Этот голосовой помощник отвечал за запись клиентов на стрижку и укладку. Самым удивительным на то время было превосходное качество звонка – практически точная мимикрия служащего, назначающего визит, включая "Мммм..." в процессе разговора. Течение разговора было настолько идеальным, что я до сих пор думаю – а может, это был какой-нибудь трюк? Эта презентация предваряла наступающую революцию в области автоматизации общения с человеком посредством голоса.
Мечта или реальность, но даже теперь, три года спустя, функция резервации мест в ресторане или парикмахерской передается виртуальному голосовому помощнику только в Соединенных Штатах. Эта служба работает и в других странах, но только для улучшения надежности движков Google Search и Maps: помощник автоматически вызывает реального сотрудника для проверки. Эта инновационная компания демонстрирует нам свою способность создавать инструменты, способные помогать людям делать некоторые вещи с превосходным уровнем качества. По крайней мере, качество было достаточно хорошим, чтобы Google решила предоставлять эти инструменты.
Для реализации диалогового голосового помощника необходимо иметь конвейер обработки, в котором первый компонент трансформирует голос пользователя в текст (Речь-в-Текст). Второй компонент (Бот) анализирует текст пользователя и генерирует ответ. Третий и последний компонент переводит ответ Бота в речь (Текст-в-Речь). Результат проигрывается пользователю через динамики компьютера или через телефонную линию.
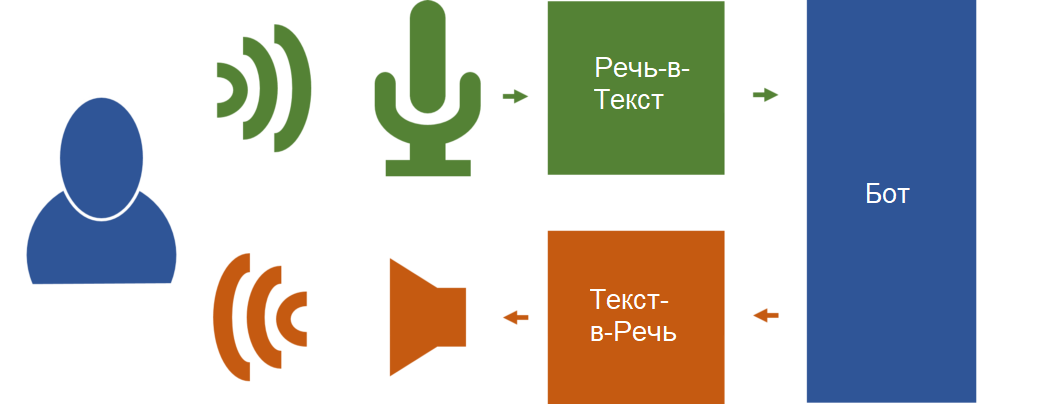
Синтез речи, также называемый Текст-в-Речь (Text-to-Speed, TTS), долго время реализовывался в виде серии трансформаций, в большей или меньшей степени продиктованных набором запрограммированных правил, и выдавал более-менее удовлетворительный результат. Вклад глубоких генеративных моделей в последние годы позволил создавать намного более автономные системы, способные генерировать тысячи различных голосов с качеством, близким к человеческому. Теперь системы стали настолько эффективными, что они могут клонировать человеческий голос по нескольким секундам записи этого голоса.
Проблема "один-ко-многим"
Чтобы сгенерировать аудиосигнал, система синтеза следует набору более или менее сложных шагов. Одна из основных проблем, которые должен решить синтез голоса – это моделирование "один-ко-многим", то есть способность преобразовать небольшое количество информации (предложение, которое нужно вокализовать) в данные формы сигнала, содержащие несколько тысяч значений. Более того, этот звуковой сигнал может иметь множество различных характеристик: громкость, выделение определенного слова, скорость произношения, управление концовкой произношения, добавление эмоций, тона... Проблема для архитектора системы заключается в реализации этой сложной обработки, разбивая генерацию звука на шаги, которые можно обучать глобально либо индивидуально.
Конвейеры обработки
Традиционные системы синтеза речи часто делятся на две категории: системы конкатенации и генеративные параметрические системы. Объединение дифонов попадает в категорию конкатенационных систем синтеза речи. Существует две разные схемы конкатенационного синтеза: первая основана на коэффициентах линейного предсказания (Linear Prediction Coefficients, LPC), а вторая – на Синхронном Перекрытии и Сложении Речи (Pitch Synchronous Overlap and Add, PSOLA). Результат часто получается ровным, монотонным и "роботским", то есть ему не хватает реальных характеристик, хотя его и можно модулировать. Под характеристиками мы имеем в виду интонацию, мелодичность, паузы, ритм, подачу, акцент... Этот метод был усовершенствован, когда появились генеративные акустические модели, основанные на скрытых марковских моделях (Hidden Markov Models, HMM), реализация контекстуальных деревьев решений. Сейчас стандартом стали глубокие генеративные системы, сбросив с трона старые системы, которые теперь считаются устаревшими.
Следуя принципу "один-ко-многим", система, которую нужно построить, состоит из трансформации текста во внутреннее состояние, а затем из трансформации этого внутреннего состояния в аудиосигнал. Большинство систем статистического параметрического синтеза речи (Statistical Parametric Speech Synthesis, SPSS) генерируют не выходной сигнал, а его частотное представление. Затем второй компонент, называемый вокодером, заканчивает генерацию на основе этого представления. Принципы генеративных нейронных сетей за последние годы стали стандартом в синтезе речи, включая сверточные нейронные сети, затем рекуррентные, вариационные автоэнкодеры (2013), механизмы внимания (2014), генеративные состязательные сети (2014) и другие.
Следующая диаграмма описывает различные компоненты архитектуры конвейера машинного обучения, используемого для генерации речи.

Как и любая система, основанная на обучении, генерация в основном состоит из двух фаз: фаза обучения и фаза генерации (вывода). Иногда добавляется "промежуточная" фаза для тонкой настройки акустической модели на основе других данных.
Внешний вид конвейера зависит от фазы:
- На фазе обучения конвейер обеспечивает генерацию моделей. Предложения являются входами энкодера/декодера, и с этими предложениями ассоциируются голосовые файлы. Иногда к этому добавляется идентификатор говорящего человека. Во многих системах генерируется мел-спектрограмма, и вокодер переводит это представление в форму сигнала. Входы вокодера – это акустические параметры (обычно мел-спектрограмма) и голос, ассоциируемый с параметрами. Этот набор параметров, извлеченный из двух модулей анализа синтеза, известен как "лингвистические признаки" (Акустический Признак).
- На фазе генерации этот конвейер отвечает за выполнение вывода (также называемого синтезом или генерацией). Входом является предложение, которое нужно трансформировать, иногда также идентификатор говорящего для выбора речевых признаков, которые будут соответствовать сгенерированному голосу. Выходом является мел-спектрограмма. Роль вокодера заключается в генерации финальной формы сигнала по сжатому представлению аудио, которое нужно сгенерировать.
В деталях используемый для обучения (тренировки) конвейер включает в себя:
- Модуль Анализа Текста, выполняющий операции нормализации текста, преобразующий числа в текст, разбивающий предложение на части (части речи), трансформирующий графемы (написанный текст) в фонемы, добавляет элементы характеристик и так далее. Некоторые системы обрабатывают прямо символы текста, другие используют только фонемы. Во время обучения и синтеза этот модуль часто применяется "как есть".
- Модуль Акустического Анализа получает в качестве входа акустические характеристики, ассоциированные с текстом. Этот модуль также может получать идентификатор говорящего при обучении со множеством разных голосов. Этот модуль будет анализировать разницу между теоретическими признаками и данными, сгенерированными в процессе обучения. Акустические признаки можно сгенерировать из обрацов голоса, используя "классические" алгоритмы обработки сигналов вроде Быстрого Преобразования Фурье (БПФ). Этот модуль также может генерировать модели, чтобы предсказать длительность сигнала (связь между фонемой и количеством сэмплов на мел-спектрограмме) и его положение в тексте. Новейшие системы идут еще дальше и добавляют предсказание тона. В конце 2020-го Эва Шекели из школы EECS в Стокгольме добавила изучение дыхания, что сократило расстояние между человеческой и машинной речью.
- Акустические модели фазы обучения представляют скрытые состояния, извлеченные из вектора представления предложения (embedding), вектора говорящего и акустических признаков. Кроме этого, существуют модели предсказания для ударений и других признаков.
- Модуль Анализа Речи используется для извлечения различных параметров из исходных голосовых записей. В некоторых системах, особенно комплексных, удаляется молчание в начале и конце записей. Извлечение признаков, которое сильно различается от системы к системе, может включать извлечение из исходных речевых сигналов тона, энергии, ударения, длительности звучания фонем, фундаментальной частоты (1-й гармонической частоты или F0), и так далее. Эти входные голосовые файлы могут принадлежать одному и тому же говорящему или нескольким. Если модель тренируется на нескольких разных голосах, ко входным данным добавляется вектор говорящего.
Конвейер, используемый для синтеза (вывода), включает в себя:
- Основываясь на выводе модуля анализа текста и акустической модели (или моделей), модуль Предсказания Признаков генерирует сжатые представления, необходимые для завершения генерации. Эти выводы могут включать в себя одно или несколько из следующих представлений: мел-спектрограмма сигнала (MelS), кепстральные коэффициенты по шкале Барка (Cep), спектрограммы линейной шкалы логарифмической магнитуды (MagS), фундаментальная частота (F0), пакет спектра, параметры апериодичности, длительность фонем, высота тона...
- Входными данными вокодера может быть одно или большее количество представлений, упомянутых выше. Существует множество версий этого модуля, и обычно он реализуется в виде отдельного модуля, что исключает его применение в комплексных системах. Среди самых популярных вокодеров – Griffin-Lim, WORLD, WaveNet, SampleRNN, GAN-TTS, MelGAN, WaveGlow и HiFi-GAN, которые генерируют сигналы, очень близкие к человеческой речи.
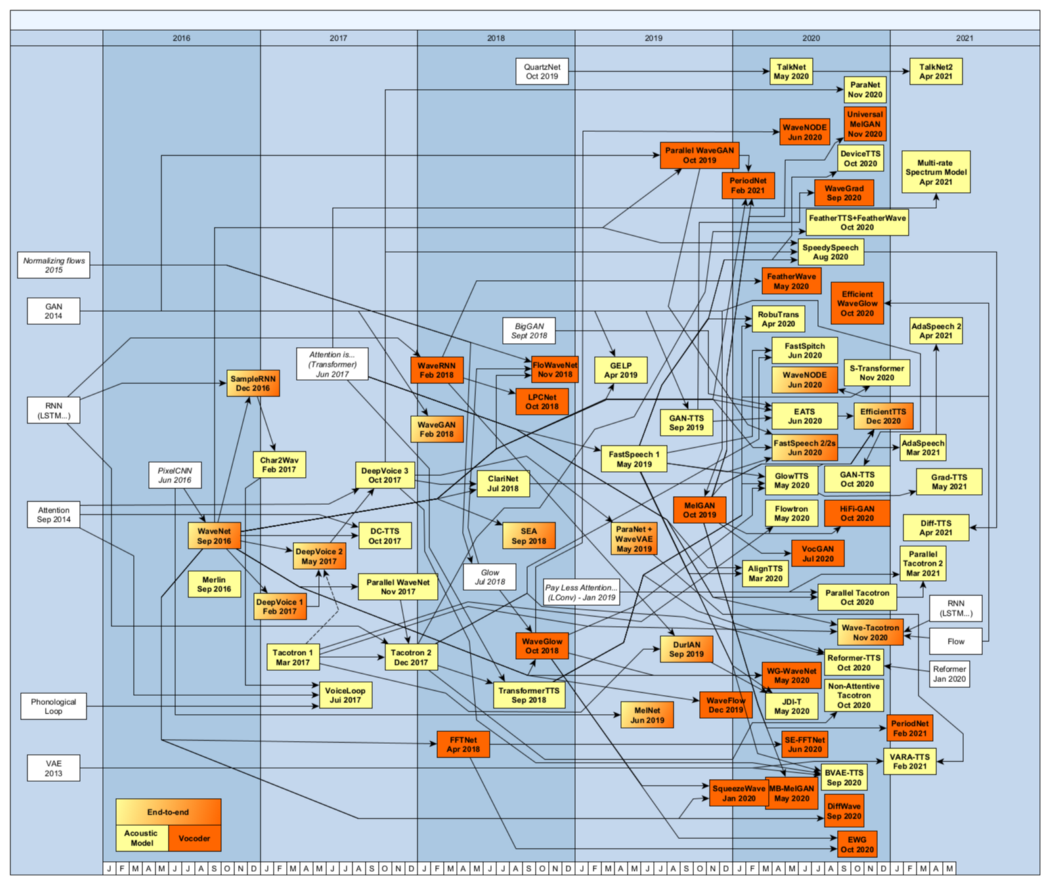
Следующая диаграмма представляет различные архитектуры, разделенные по году публикации научной статьи. Она также показывает связи, когда система использует особенности предыдущей системы.
Знакомимся с мел-спектрограммами
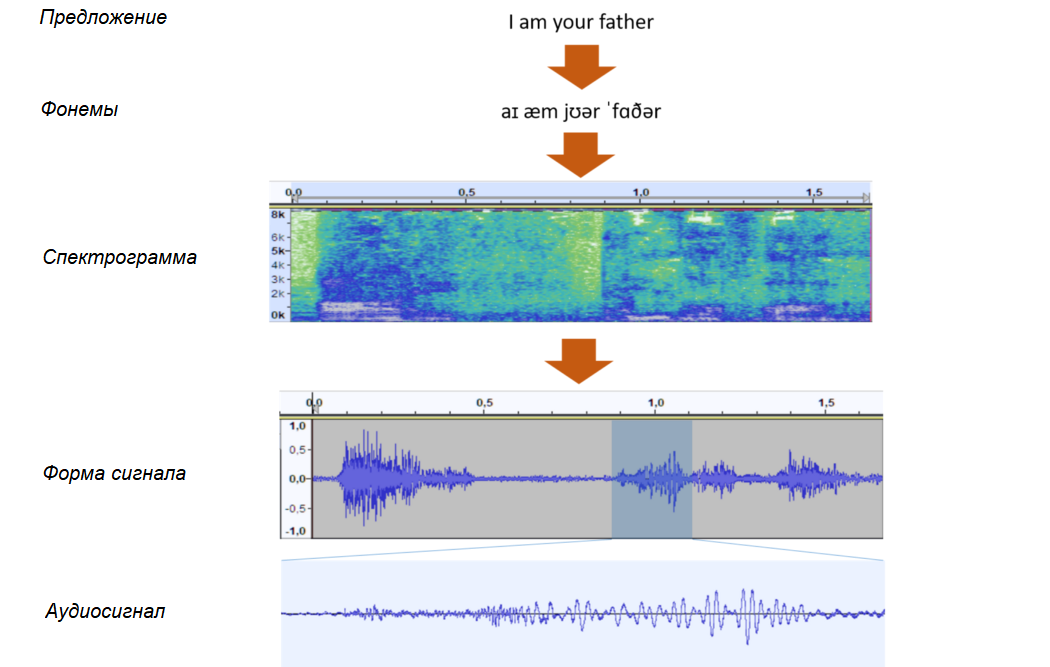
Первое преобразование заключается в Оконном Быстром Преобразовании Фурье (Short-Term Fast Fourier Transform, STFFT). Это преобразование разбирает сигнал на компоненты, улавливая различные частоты, которые его составляют, а также амплитуду каждой частоты. Из-за того, что сигнал со временем меняется, он разбивается на оконные сегменты (обычно между 20 и 50 мс), которые частично перекрываются.
Горизонтальная ось соответствует временной шкале, вертикальная – частоте, а цвет пикселя соответствует уровню сигнала в децибелах (dB). Чем ярче цвет, тем мощнее сигнал на этой частоте. Затем частотная шкала переводится в логарифмическую частотную.
Поскольку человеческое ухо воспринимает разницу в частотах для высоких и низких частот по-разному, Стевенс, Волкманн и Ньюманн в 1937-м году предложили шкалу, названную мел-шкалой, при которой одинаковая разница между звуками в мел-единицах кажется слушателю постоянной на любых частотах. Спектрограмма, преобразованная в соответствии с мел-шкалой, и называется мел-спектрограммой.
Глубокие генеративные модели
Автоматическое генеративное моделирование – это очень широкая область, имеющая почти бесконечное множество применений. Очевидные приложения – это генерация изображений и генерация текста, популяризированная GPT-2 и GPT-3. В нашем случае мы рассчитываем реализовать с их помощью генерацию голоса. Популярные вначале так называемые "классические" сети (такие, как сверточные нейронные сети, CNN) были заменены более сложными рекуррентными сетями (RNN), которые ввели понятие предыдущего контекста, важного для последовательной речи. Сегодня эта генерация обычно реализуется глубокими сетевыми архитектурами вроде расширенных причинно-следственных сверточных сетей (Dilated Causal Convolution Networks, DCCN), "учитель-ученик", вариационные автоэнкодеры (Variational Auto-Encoders, VAE), генеративные состязательные сети (Generative Adversarial Networks, GAN), модели точного подобия, такие, как PixelCNN/RNN, Image Transformer'ы, Generative Flow и так далее.
Самые популярные архитектуры включают:
- Авторегрессивная модель – модель, основанная на регрессии для временных рядов, при которой будущие значения определяются только прошлыми значениями, а не какими-либо другими данными. Если говорить о генерации речи, большинство ранних моделей, основанных на нейронных сетях, были авторегрессивными, а это означало, что будущие паттерны речи полностью определяются прошлыми паттернами, на основе которых рассчитываются долговременные зависимости. Такие модели довольно легко создавать и обучать, но их недостаток в том, что они распространяют и даже усиливают ошибки. Время генерации при этом пропорционально длине генерируемой последовательности. Будучи последовательными, эти модели имеют крупный недостаток: они не могут использовать возможность параллелизма, заложенную в новейшие процессоры GPU и TPU. Это усложняет их применение в системах реального времени, в которых необходимо отвечать пользователю в течение определенного времени. Не-авторегрессивные системы, введенные с появлением WaveNet и ClariNet, позволяют генерировать сэмплы голоса, не полагаясь на результаты предыдущей генерации, что допускает полную параллелизацию, ограниченную только памятью процессоров. Такие системы сложнее реализовать, обучать, и они не настолько точные (поскольку исчезли внутренние зависимости), но могут сгенерировать все сэмплы за миллисекунды.
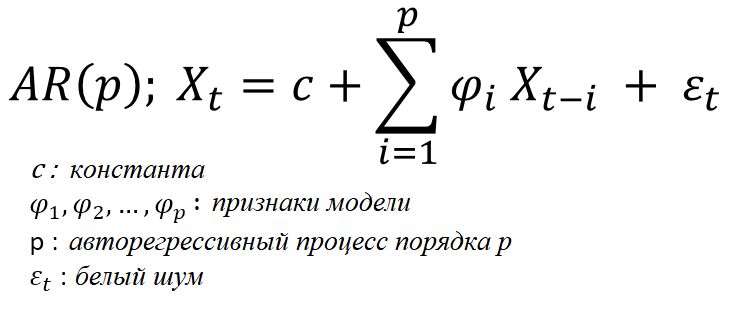
- Введенные в 2016 компанией Google и ее популярной WaveNet расширенные причинно-следственные сверточные сети (Dilated Causal Convolution Network, DCCN) – это сверточные сети, в которых фильтр применяется к области, большей своей длины, пропуская входные значения с определенным шагом. Это расширение позволяет сети обрабатывать очень большие входные массивы, имея всего лишь несколько слоев. Впоследствии многие архитектуры интегрировали эту модель в свои конвейеры генерации.
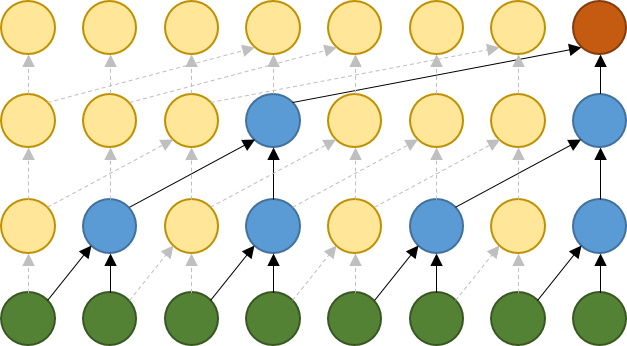
- Потоковые архитектуры (Flow) состоят из серии обратимых трансформаций (Динх и пр., 2014 – Резенде и Мохаммед, 2015). Термин "поток" означает, что простые обратимые трансформации можно комбинировать для создания сложных обратимых трансформаций. Модель Нелинейной Независимой Оценки Компонентов (Nonlinear Independent Component Estimation, NICE) и модель Real Non-Volume Preserving (RealNVP) представляют два популярных вида обратимых трансформаций. В 2018-м NVIDIA использовала этот метод, интегрировав методику Glow (термин, означающий Generative-Flow) в WaveGlow для генерации голосовых файлов на основе мел-спектрограммы.
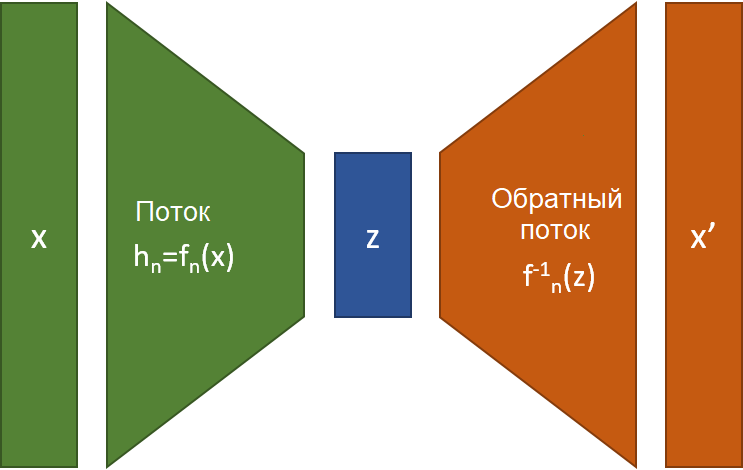
- В модели Учитель-Ученик используются две модели: предобученная авторегрессивная модель (Учитель) используется для того, чтобы не-авторегрессивная модель (Ученик) усвоила правильные акценты и ударения. Учитель будет учитывать выходы параллельной системы прямого прохода (Студента). Этот механизм также называется Дистилляцией Знаний (Knowledge Distillation). Критерии обучения Студента имеют отношение к обратным авторегрессивным потокам и прочим потоковым моделям, введенным с появлением WaveGlow. Крупнейшая проблема таких моделей параллельного синтеза – они могут работать только с обратимыми трансформациями, что ограничивает возможности модели.
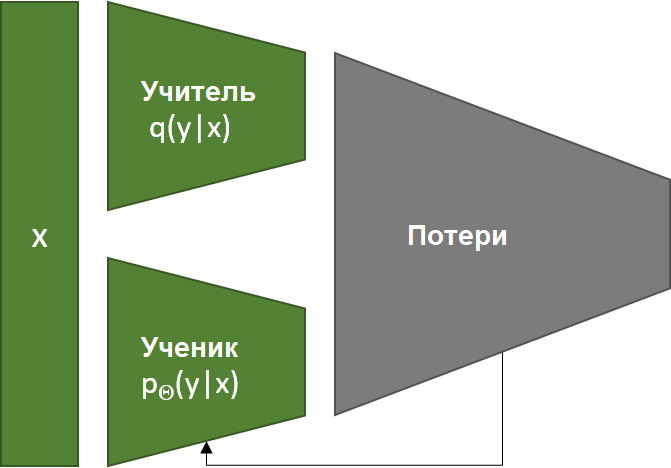
- Вариационные автоэнкодеры (Variational Auto-Encoders, VAE) – это адаптация автоэнкодеров. Автоэнкодер состоит из двух нейронных сетей, взаимодействующих друг с другом. Первая сеть переводит входные данные в последовательное сжатое внутреннее представление z, которое можно интерполировать. Вторая нейронная сеть отвечает за восстановление входа из внутреннего представления, сокращая потери вывода. Для сокращения эффектов переобучения, обучение регуляризируется по среднему значению и ковариации. В случае генерации голоса энкодер преобразует текст во внутренее состояние в соответствии с акустическими признаками, а декодер преобразует это состояние в звуковой сигнал. Модель энкодер/декодер многое заимствует у генерации изображений, поскольку в их основе лежит идея генерация изображения (спектрограммы). Таким образом, PixelCNN, Glow и BigGAN послужили источниками идей для сетей TTS.
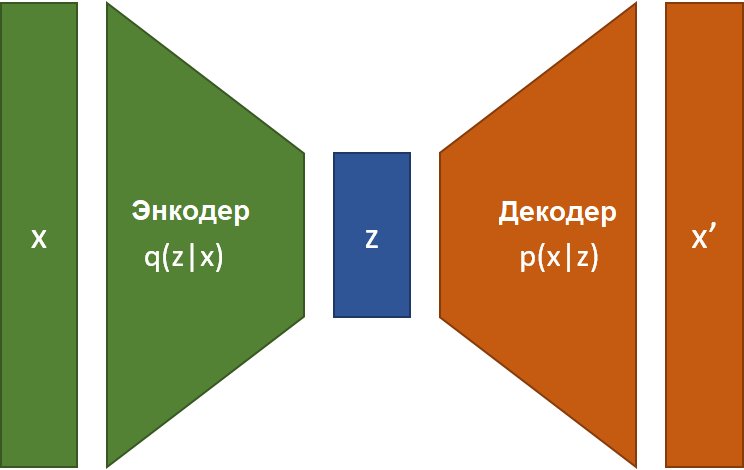
- Генеративные состязательные сети (Generative Adversarial Networks – GAN, Гудфеллоу и пр.) появились в 2014-м, чтобы помочь в генерации изображений. Они основаны на парадигме "соревнования" генератора с дискриминатором. Генератор обучается генерировать изображения на основе входных данных, а дискриминатор обучается отличать истинные изображения от сгенерированных. Команда из Сан-Диего (Донахью и пр., 2018) применяет этот метод для генерации аудиосигналов (WaveGAN и SpecGAN). Многие вокодеры также используют эту методику как основу для генерации. GAN – один из лучших методов генерации звуковых файлов.
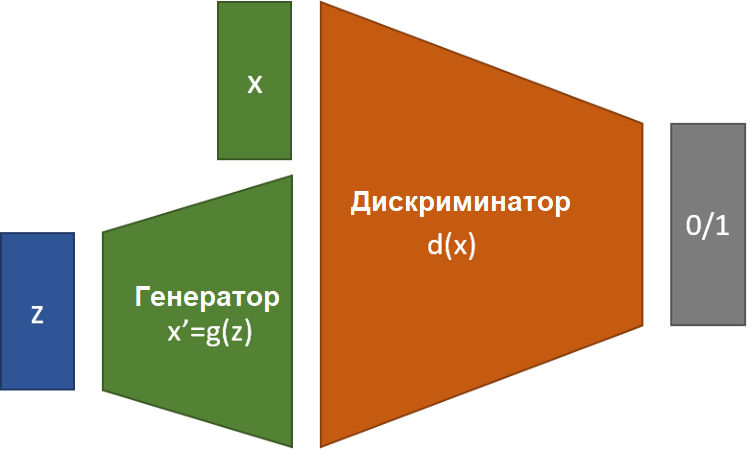
Существуют и другие системы, но они не так популярны – например, Диффузионная Вероятностная Модель, состоящая из модификации сигналов последовательностью Марковских переходов вроде добавления Гауссовского шума, IAF...
Появление механизма внимания радикально улучшило сети seq2seq, убрав необходимость рекуррентности, но предсказать правильную синхронизацию между входом и выходом, по-прежнему сложно. Ранние сети использовали механизм внимания, основанный на содержании, но получали ошибки в синхронизации. Чтобы справиться с этой проблемой, были предложены и протестированы несколько других механизмов внимания: механизм Гауссовской Смешанной Модели внимания (Gaussian Mixture Model, GMM), механизм Гибридного Внимания, Чувствительного к Локации (Hybrid Location-Sensitive Attention) и метод синхронизации с Монотонным Вниманием.
Эта таблица перечисляет различные архитектуры основных нейронных сетей, построенных за последние годы.
Комплексные системы
В феврале 2017-го университет Монреаля представила Char2Wav: комбинацию двунаправленной рекуррентной нейронной сети, рекуррентной нейронной сети с вниманием и нейронного вокодера из SampleRNN. Это комплексная сеть, позволяющая изучать звуковые сэмплы напрямую из текста, не проходя через промежуточные шаги вроде мел-спектрограммы. В качестве входа для выходных сетей используется непосредственно выход остальных нейронных сетей.
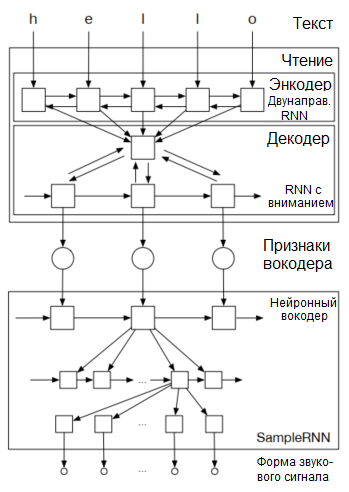
Char2Wav включает проигрыватель и нейронный вокодер. Чтение производит энкодер-декодер с вниманием. Этот энкодер принимает в качестве входа текст или фонемы, а декодер работает из промежуточного представления. По утверждению университета:
"В отличие от традиционных моделей, преобразующих текст в речь, Char2Wav обучается создавать аудио непосредственно из текста."
В том же месяце Baidu также разработала полностью автономную комплексную систему, называемую DeepVoice. Она обучается на наборе данных небольших фрагментов аудио и их транскрипции. Позднее, в 2020-м, Microsoft представила нейронную сеть FastSpeech 2s, которая не генерировала мел-спектрограммы, но по качеству уступала аналогичной сети, которая их генерировала.
Комплексные архитектуры не доминируют в области генерации голоса. Большинство архитектур разделяют модель, переводящую графемы в фонемы, модель предсказания длительности, модель акустических признаков для генерации мел-спектрограммы и вокодер.
Последние публикации и Blizzard Challenge 2020, организованный в прошлом году университом науки и технологии Китая (USTC) при поддержке Эдинбургского университета, подтверждают такое состояние дел, поскольку последнее соревнование показало полное исчезновение классических систем и доминирование статистических параметрических систем синтеза речи, основанных на двух стадиях генерации. Более половины соревнующихся команд использовали нейронные системы, переводящие последовательность-в-последовательность (напр., Tacotron) с использованием вокодеров WaveRNN или WaveNet. Остальная половина применяют подходы, основанные на DNN, с теми же вокодерами.
Кто исследователи?
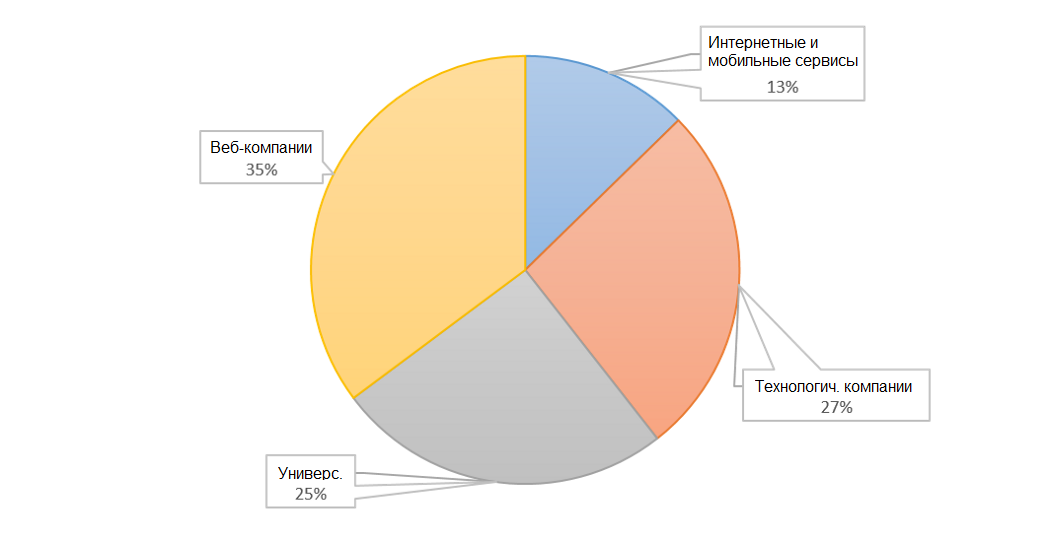
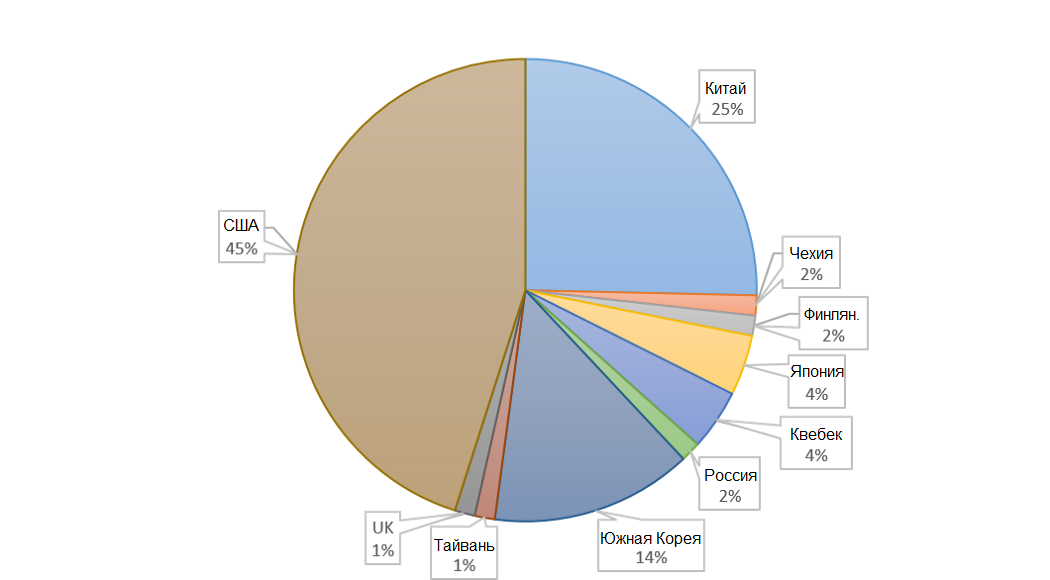
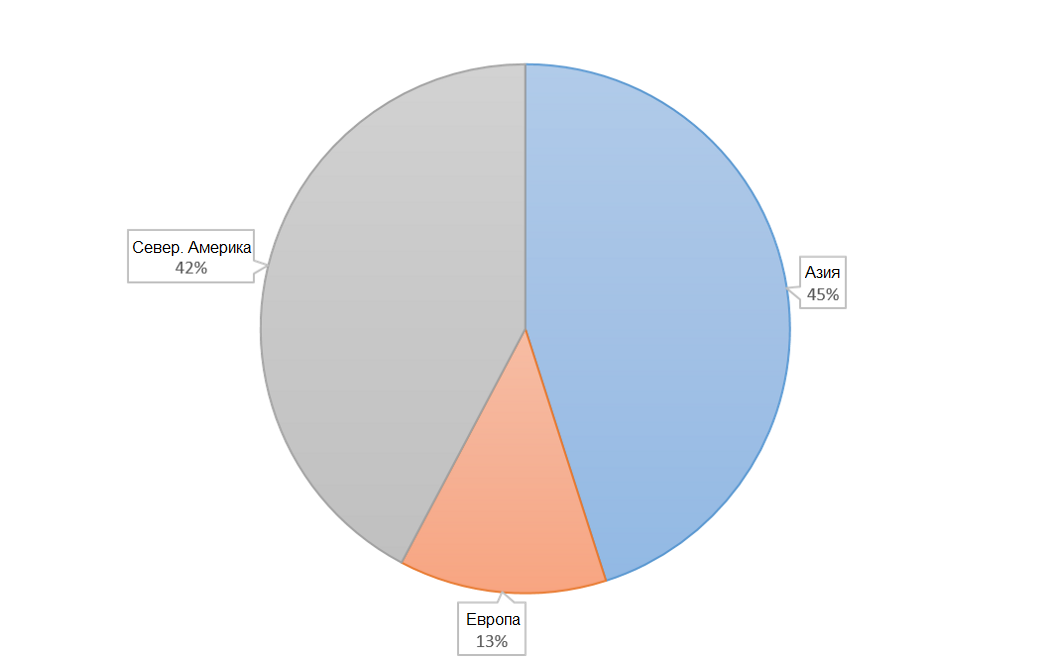
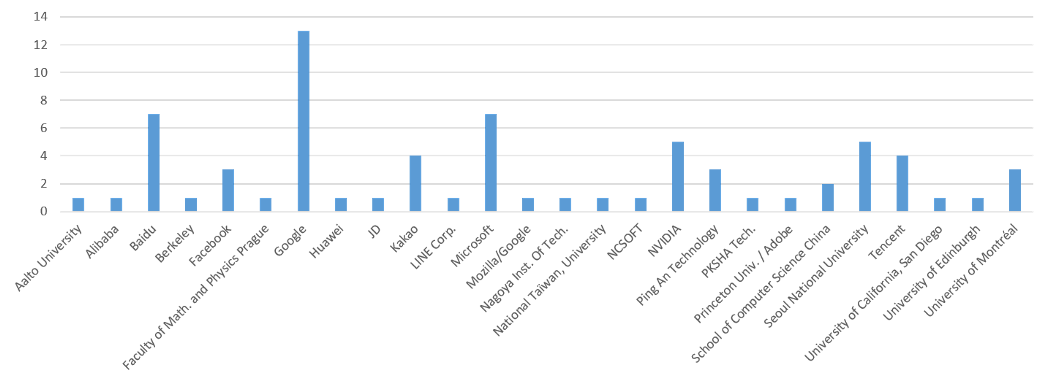
Где найти данные
Обязательная аннотация каждого элемента речевых последовательностей больше не считается обязательной. Сегодня единственными обязательными элементами считаются предложение и соответствующий ему голосовой фрагмент – для генерации моделей больше ничего не нужно. Поэтому сейчас доступно намного больше данных, чем прежде, в частности (в алфавитном порядке):
- Речевые базы Blizzard – многоязычная – разные размеры. Соревнование Blizzard предоставляет каждому участнику несколько образцов речи для обучения моделей. Эти базы данных доступны для свободного скачивания во время каждого соревнования.
- CMU-Arctic – США – 1.08 Гб – эти базы данных состоят из примерно 1150 тщательно выбранных фраз из текстов "Проекта Гутенберг" и не защищены авторским правом.
- CommonVoice 6.1 – многоязычная – разные размеры. Мозилла запустила инициативу по сбору данных, чтобы сделать распознавание речи открытым и доступным для всех. С этой целью они создали общественный проект, позволяющий каждому наговаривать предложения и проверять произношение других. Версия 6.1 для французского языка содержит 18 Гб или 682 часа проверенных записей.
- Европейская Ассоциация Языковых Ресурсов (European Language Resources Association) – многоязычная – разные размеры. Множество платных баз данных для коммерческого использования.
- LDC Corpora-Databs – многоязычная – разные размеры. Лингвистический консорциум данных (LDC) – это открытый консорциум университетов, библиотек, корпораций и государственных исследовательских лабораторий, созданный в 1992-м для преодоления критической нехватки данных для исследований и развития языковых технологий. LDC располагается в университете Пенсильвании.
- LibriSpeech – США – 57.14 Гб. Это массив, содержащий около 1000 часов английской речи с частотой дискретизации 16 кГц, подготовленный Вассилом Панайотовым с помощью Даниэля Пови. Эти данные получены из аудиокниг, записанных в рамках проекта LibriVox, они тщательно сегментированы и выравнены.
- LibriTTS – США – 78.42 Гб. Это англоязычный многоголосый массив из 585 часов начитанного текста с частотой дискретизации 24 кГц, подготовленный Хейгой Зен при поддержке Google Speech и команды Google Brain.
- LibriVox – многоязычная – разные размеры. Это группа добровольцев со всего мира, читающие и записывающие общедоступные тексты для создания бесплатных, доступных для скачивания аудиокниг.
- LJ Speech – США – 2.6 Гб. Несомненно, один из лучших и наиболее известный и часто используемый набор данных для оценки моделей. Это общедоступный речевой набор данных, состоящий из 13.100 коротких аудиоклипов одного и того же голоса, читающего фрагменты из 7 книг, не относящихся к беллетристике. Для каждого клипа приводится расшифровка. Длительность клипов – от 1 до 10 секунд, а их суммарная продолжительность – примерно 24 часа. Тексты были опубликованы с 1884 по 1964, они общедоступны. Звукозаписи были сделаны в 2016-2017 в рамках проекта LibriVox, и они также общедоступны.
- VCTK – США – 10.94 Гб. CSTR VCTK (Voice Clone ToolKit) включает речевые фрагменты, произнесенные 109 разными англоговорящими людьми с различными акцентами. Каждый голос читает примерно 400 предложений, выбранных из газеты "Геральд", Абзац о Радуге и информационный абзац. Эти предложения одинаковы для всех участников.
Существует множество наборов данных, и было бы затруднительно перечислить их все: OpenSLR, META-SHARE, аудиокниги... Однако, несмотря на изобилие речевых данных, найти наборы данных, позволяющие обучать модели в просодическом и эмоциональном аспектах, всегда сложно.
Как измерять качество?
Поскольку измерить качество звука необходимо для определения качества модели, это должны делать люди. Избранных людей, говорящих на оцениваемом языке, просят оценить качество звука аудиосигнала. На основе всех оценок одного и того же сигнала рассчитывается Средняя Оценка Мнений (Mean Opinion Score, MOS), не стандартизованная и поэтому субъективная. Этот рейтинг находится между 1 (Плохо) и 5 (Прекрасно).
| Рейтинг | Качество | Искажения |
| 5 | Прекрасно | Незаметны |
| 4 | Хорошо | Еле заметны, но не раздражают |
| 3 | Средне | Заметны и немного раздражают |
| 2 | Слабо | Раздражают, но приемлемы |
| 1 | Плохо | Очень раздражают и неприемлемы |
Избранные слушатели приглашаются прослушать сгенерированные аудиофайлы, иногда по сравнению с исходными файлами. После прослушивания они ставят свои оценки, и средняя оценка дает рейтинг MOS. Начиная с 2011, исследователи могут использовать хорошо описанный подход, основанный на подходах краудсорсинга. Лучший из них, названный фреймворком CrowdMOS, использующий главным образом сайт краудсорсинга Amazon Mechanical Turk (Ф. Рибейро и пр. – Майкрософт, 2011).
Большинство лабораторий предоставляют оценку своих алгоритмов, основанную на этом принципе, что позволяет получить общую картину их сравнительного качества. Следует отметить, что результаты оценок сильно зависят от говорящего и акустических характеристик записи. С другой стороны, сравнивать оценки можно не всегда, поскольку различные модели часто обучаются на разных наборах данных. И все-таки, эти оценки позволяют нам получить какое-то представление о сравнительном качестве архитектур относительно друг друга. Эта возможность усиливается, если исследователи проводят сравнительные тесты своей модели против моделей своих коллег.
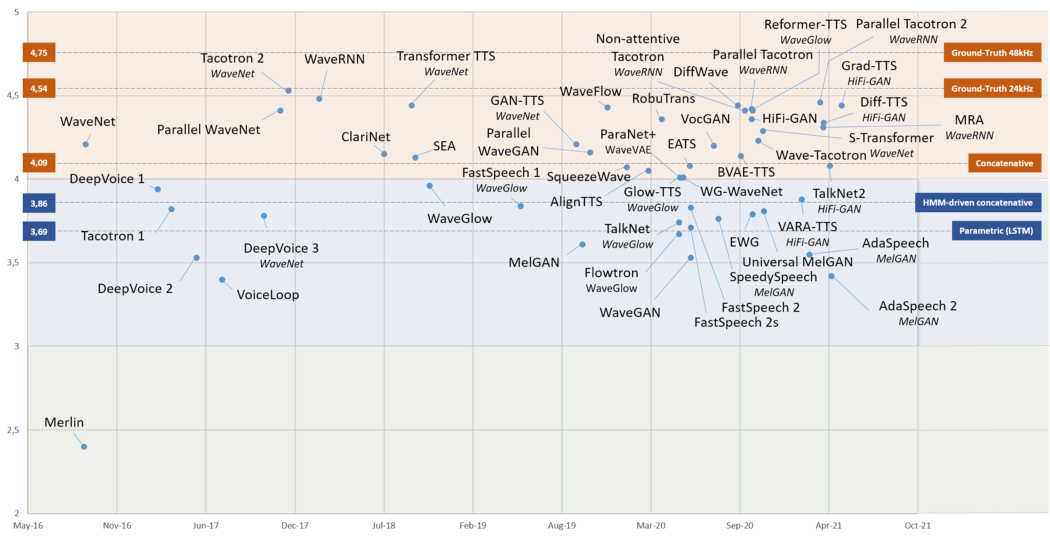
Следующая диаграмма показывает оценку MOS для каждой из изученных моделей. Опубликованы только MOS-оценки, полученные для английского языка.
Еще один часто используемый тест прослушивания – это метод MUSHRA (MUltiple Stimuli with Hidden Reference and Anchor). Слушателей просят сравнивать смешанные сигналы между естественной речью и сгенерированными аудиосигналами, и они дают оценки в диапазоне от 0 до 100.
В 2019-м Бинковский и пр. представили автоматический количественный тест, названный Дистанцией Глубокой Речи Фреше (Freshet DeepSpeech Distance, FDSD), представляющий собой адаптацию дистанции Фреше для получения рейтинга расстояния между исходным файлом и сгенерированным сигналом. Этот рейтинг преимущественно используется в генеративных состязательных сетях.
Часто вычисляют и другие метрики – например, RMSE (средняя квадратичная ошибка), NLL (Negative Log Likelihood), CER (Character Error Rate), WER (World Error Rate), UER (Utterance Error Rate), MCD (Mel-Cepstral Distortion)...
Голосовые конференции
Несколько конференций посвящены синтезу голоса, и мы отмечаем, что даты научных публикаций часто ориентируются к одной из этих конференций. В частности, мы отметим (в алфавитном порядке):
- ICASSP. Международная конференция по акустике, речи и обработке сигналов (The International Conference on Acoustics, Speech and Signal Processing) – ежегодная конференция, организованная IEEE и проводимая в июне. Обсуждаемые темы включают акустику, речь и обработку сигналов.
- ICLR. Организуемая с 2013-го года, международная конференция по представлениям для обучения (International Conference on Learning Representations) проводится в мае и занимается общими вопросами обучения.
- ICML. Созданная в 1980-м, Международная Конференция по Машинному Обучению (International Conference on Machine Learning) проводится каждый год в июле. Исследовательские статьи, присылаемые на конференцию, принимаются с конца декабря до начала февраля.
- Interspeech. Основанная в 1988-м конференция Interspeech проводится в конце августа или начале сентября. Цель International Speech Communication Association (ISCA) – поддерживать деятельность и обмен информацией во всех областях, относящихся к науке и технологиям речевого общения.
- NeurIPS. Созданная в 1987-м научная конференция по искусственному интеллекту и вычислительным нейронным наукам, названная NeurIPS (Neural Information Processing Systems), проводится в декабре каждого года. Она занимается всеми аспектами использования сетей машинного обучения и искусственного интеллекта.
Задачи будущего
В речевых системах важно, чтобы общение происходило как можно более естественно, то есть, без продолжительных пауз. Поэтому генерация голоса должна происходить практически мгновенно. Человек способен очень быстро реагировать на вопросы, тогда как системе генерации часто приходится дожидаться конца генерации, прежде чем выдавать звуковой сигнал пользователю (в основном потому, что она получает все предложение, которое нужно трансформировать). С помощью параллелизма недавно появившиеся не-авторегрессивные системы явно превосходят старые модели, поскольку они способны распределить генерацию звукового сигнала между несколькими параллельными процессами, и, следовательно, выдавать звуковые сигналы за несколько миллисекунд, независимо от длины предложения (это называется фактором реального времени или RTF). В телефонных колл-центрах виртуальный разговорный ассистент (также называемый колл-ботом) должен уметь реагировать на вопросы за несколько секунд, иначе он будет считаться неэффективным или вообще непригодным.
Системы генерации голоса часто "спотыкаются" на одиночных буквах, произношении, повторяющихся числах, длинных предложениях, произношении чисел и т.д., что приводит к неустойчивому, зависящему от входной информации, качеству звука. Более того, модели все еще иногда генерируют странные звуки, приводящие к диссонансам в выходном сигнале. Поскольку человеческое ухо особенно чувствительно к таким вариациям, плохое качество сгенерированного звука немедленно замечается и ухудшает оценку качества звука. Даже при значительных улучшениях полностью избавиться от таких проблем чрезвычайно сложно.
Размеры моделей и занимаемый ими объем памяти также являются серьезной задачей для будущих нейронных сетей, которым придется соответствовать сетям со множеством параметров (десятками миллионов параметров), располагая намного меньшими ресурсами. В мобильном телефоне или планшете процессор намного слабее, а памяти меньше. DeviceTTL (Хуанд и пр., лаборатория речи группы Alibaba, октябрь 2020) может генерировать голос, имея "всего" 1.5 миллиона параметров и 0.099 Гигафлопов, с качеством, близким к Tacotron'у с его 13.5 миллионами параметров. LightSpeech (Luo и пр., USTC и Microsoft, февраль 2021), основанная на FastSpeech2, сумела достичь такой же MOS, имея 1.8 миллиона параметров против 27 миллионов у FastSpeech2.
Большинство сгенерированных голосов монотонны и не содержат эмоциональной окраски, если не доступен набор данных, содержащий разнообразные эмоциональные выражения, записанные разными голосами. Чтобы отмечать системные изменения длительности и ритма, применяемые к выходному сигналу (просодия), существует язык разметки, называемый Speech Synthesis Markup Language (SSML). Используя систему тегов, окружающих слово, параметры которого нужно изменить, можно установить такие параметры, как тон и его диапазон (широкий или узкий), очертание, темп, длительность и громкость. Он также позволяет определить, например, паузы между словами и т.п. В последних публикациях появилась тенденция заменять такие теги другими механизмами – такими, как ожидаемая дикция просодии (Expressive TTL с помощью тегов стиля – Ким и пр., 2021). Исследователи также модифицируют существующие нейронные сети, добавляя к ним дополнительные сети для модуляции сгенерированного сигнала с целью моделирования эмоций и ударения (Emphasis – Ли и пр., 2018, CHiVE-WAN и пр., 2019; Flavored Tacotron – Эльяси и пр., 2021). Также используются методы преобразования голоса: сигнал модифицируется после генерации, чтобы модулировать его в зависимости от цели.
Большинство систем рассчитаны на генерацию единственного голоса, соответствующего тому, который был использован для их обучения. Имеется некоторый интерес (особенно в свете последних публикаций: Арик и пр., 2018, Джиа и пр., 2018, Attentron; Чои и пр., 2020, и SC-GlowTTS Казанова и пр. 2021) к генерации новых голосов, которые не были использованы в процессе обучения. Такой подход "TTS без обучения" (zero-shot TTS, или ZS-TTS) полагается на несколько секунд речи, чтобы адаптировать сеть к новому голосу. Этот метод похож на клонирование голоса (Voice Cloning). В соревновании, называемом The Multi-Speaker Multi-Style Voice Cloning Challenge команды должны клонировать голос говорящего на том же самом либо другом языке. Результаты также оцениваются с помощью крупномасштабного теста прослушивания. Еще одно похожее соревнование в основном концентрируется на преобразовании голоса: Voice Conversion Challenge.
В мире существует более 7.100 различных языков. Если добавить диалекты, эта цифра вырастет до 41.000 (например, на территории Китая есть более 540 языков, а в Индии их более 860). Промышленные системы синтеза речи часто предлагают лишь малую часть этой чрезвычайно разнообразной экосистемы. Например, система Speech-to-text из Google Cloud предлагает 41 язык, и 49, если считать варианты языков (например, канадский французский и собственно французский).
Современные нейронные сети могут воспроизвести голос методом передачи знаний на основе нескольких секунд речи нужным голосом. Это не только позволяет человеку, потерявшему голос, генерировать его, но и позволяет обманывать людей, изображая любой голос на основе пары минут аудиозаписи. То есть, можно "заставить" любого человека сказать все, что угодно, или даже "представлять" какую-нибудь компанию, моделируя голос ее руководителя. Это значит, что следующей задачей после качественной генерации голоса будет создание систем обнаружения подобных злоупотребления. Поскольку люди не могут дважды произнести одно и то же предложение совершенно одинаково, можно "вычислить" робота, попросив его повторить это же предложение. Однако вам потребуются отличные уши и звуковая память, чтобы отличить человека от робота!
Заключение
Университеты и исследовательские лаборатории компаний вышли за границы простой генерации речи и принялись за такие сложные задачи, как повышение скорости генерации без ухудшения качества, исправляя ошибки прошлой генерации, генерировать несколько разных голосов на основе записей единственного голоса, добавление в сигнал просодии и т.п.
Качество генерируемых сегодня голосов достаточно высокое для всех возможных видов приложений, а особенно для "разговорных ассистентов", основанных на речевом общении.
А как бы вы использовали синтез голоса в своем бизнесе?
Ссылки
CrowdMOS: изучение подхода к краудсорсингу средней оценки мнений (MOS).
BlizzardChallenge и BlizzardChallenge 2020.
SampleRNN: безусловная комплексная нейронная модель генерации аудио (2016), Соуруш Мехри и пр. [pdf]
WaveNet: генеративная модель для неотредактированного аудио (2016), Аарон ван ден Оорд и пр. [pdf]
Char2Wav: комплексный синтез речи (2017), Дж. Сотело и пр. [pdf]
DeepVoice: нейронное преобразование текста в речь в реальном времени (2017), Арик и пр. [pdf]
DeepVoice 2: многоголосое нейронное преобразование текста в речь (2017), Серкан Арик и пр. [pdf]
DeepVoice 3: нейронное преобразование текста в речь на 2000 голосов (2017), Вей Пинг и пр. [pdf]
Tacotron: на пути к комплексному синтезу речи (2017), Юксуань Ванг и пр. [pdf]
FastSpeech: быстрая, надежная и контролируемая система "текст в речь" (2019), Йи Рен и пр. [pdf]
MelNet: генеративная модель для аудио в частотной области (2019), Шон Васкез и пр. [pdf]
Многоголосый комплексный синтез речи (2019), Джихьюн Парк и пр. [pdf]
[ParaNet] Параллельная нейронная система "текст в речь" (2019), Кайнан Пенг и пр. [pdf]
WaveFlow: компактная модель на основе потока для необработанного аудио (2019), Вей Пинг и пр. [pdf]
Waveglow: генеративная сеть на основе потока для синтеза речи (2019), Р. Пренгер и пр. [pdf]
[EATS] Комплексная состязательная система "текст в речь" (2020), Йи Рен и пр. [pdf]
Merlin: нейронная сеть для синтеза речи с открытым кодом (2016), Ву и пр.
WaveGAN / SpecGAN состязательный аудио синтез (2018), Донахью и пр. [pdf]
WaveRNN: эффективный нейронный аудиосинтез (2018), Кальхбреннер и пр. [pdf]
FFTNet: зависимый от голоса нейронный вокодер реального времени (2018), Джин и пр. [pdf]
[SEA]: Пример эффективной адаптивной системы "текст в речь" (2018), Чен и пр. [pdf]
FloWaveNet: генеративный поток для необработанного аудио (2018), Ким и пр. [pdf]
RobuTrans: устойчивая модель "текст в речь" на основе трансформеров (2020), Ли и пр. [pdf]
TalkNet: полностью сверточная не-авторегрессивная модель синтеза речи (2020), Беляев и пр. [pdf]
WG-WaveNet: высококачественный синтез речи в реальном времени без GPU (2020), Хсу и пр. [pdf]
WaveNODE: Последовательный нормализующий поток для синтеза речи (2020), Ким и пр. [pdf]
FastPitch: параллельная система "текст в речь" с предсказанием тона (2020), Ланкуцкий и пр. [pdf]
SpeedySpeech: эффективный нейронный синтез речи (2020), Вейнер и пр. [pdf]
WaveGrad: оценка градиентов для генерации звуковых форм (2020), Чен и пр. [pdf]
DiffWave: универсальная диффузионная модель для синтеза аудио (2020), Конг и пр. [pdf]
Parallel Tacotron: не-авторегрессивный и контролируемый "текст в речь" (2020), Элиас и пр. [pdf]
Effective WaveGlow: улучшенный вокодер WaveGlow с увеличенной скоростью (2020), Сонг и пр. [pdf]
Reformer-TTS: нейронный синтез речи с реформерной сетью (2020), Ихм и пр. [pdf]
Wave-Tacotron: комплексный синтез "текст в речь" без спектрограмм (2020), Вайсс и пр. [pdf]
s-Transformer: сегментный трансформер для надежного нейронного синтеза речи (2020), Ванг и пр. [pdf]
AdaSpeech: адаптивная система "текст в речь" для произвольного голоса (2021), Чен и пр. [pdf]
Diff-TTS: диффузионная модель перевода текста в речь с удалением шумов (2021), Джеонг и пр. [pdf]
AdaSpeech 2: адаптивный перевод текста в речь без данных о транскрипции (2021), Юан и пр. [pdf]
Grad-TTS: диффузионная вероятностная модель для перевода текста в речь (2021), Попов и пр. [pdf]
Комментарии