

Гистограмма – это двухмерный график с прямоугольными столбцами по оси X или Y. Мы используем эти столбцы для сравнения значений, принадлежащих дискретным категориям, сравнивая высоту или ширину соответствующих столбцов. Такие графики часто используются для визуализации данных, поскольку их нетрудно создать и просто понять.
Однако в некоторых ситуациях, таких, как создание инфографики или когда необходимо привлечь внимание публики к данным, гистограмма может быть недостаточно привлекательной. Иногда слишком большое количество гистограмм может сделать презентацию скучной.
Визуализация данных включает множество видов графиков. Эта статья продемонстрирует девять идей, которые можно использовать не только для разнообразия, но и для улучшения внешнего вида полученных результатов.
Предупреждение. Целью этой статьи не является опорочить гистограммы. Каждый вид графиков имеет свои преимущества. Эта статья всего лишь демонстрирует виды визуализации, привлекающие внимание больше, чем гистограммы. Разумеется, они не идеальны – каждый из них имеет свои преимущества и недостатки.
Давайте приступим к делу.
Получаем данные
Начнем с импортирования библиотек.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Чтобы продемонстрировать, что методы, используемые в этой статье, можно применять к реальным данным, мы используем данные из Списка стран по выбросам углекислого газа из Википедии. Эта статья содержит список суверенных государств и территорий и их выбросы углекислого газа в 2018 году.
Мы используем эти данные из Википедии в соответствии с лицензией. Я использовал следующие шаги из статьи «Получение данных из Интернета – из таблицы Википедии в DataFrame»:
import requests
from bs4 import BeautifulSoup
wikiurl='https://en.wikipedia.org/wiki/List_of_countries_by_carbon_dioxide_emissions'
table_class='wikitable sortable jquery-tablesorter'
response=requests.get(wikiurl)
#status 200: Сервер успешно ответил на запрос http
print(response.status_code)
Используем BeautifulSoup для разбора полученных данных:
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table',{'class':"wikitable"})
df2018 = pd.read_html(str(table))[0]
df2018
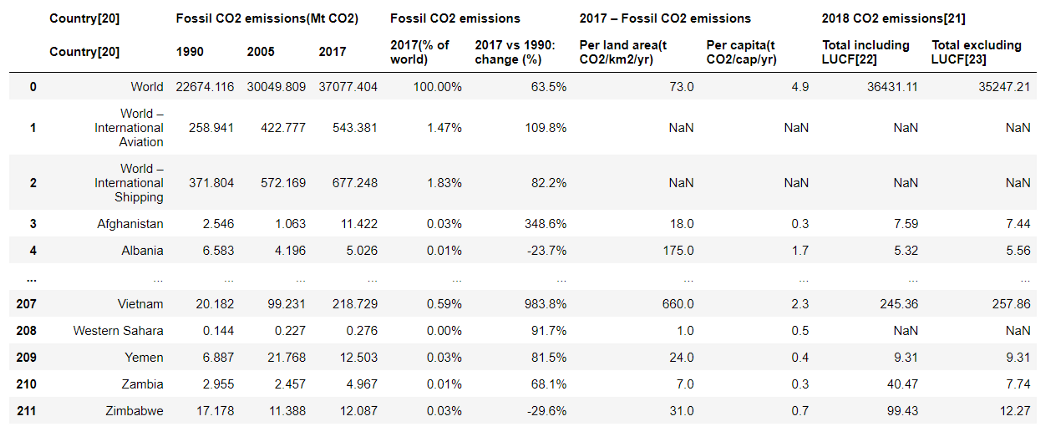
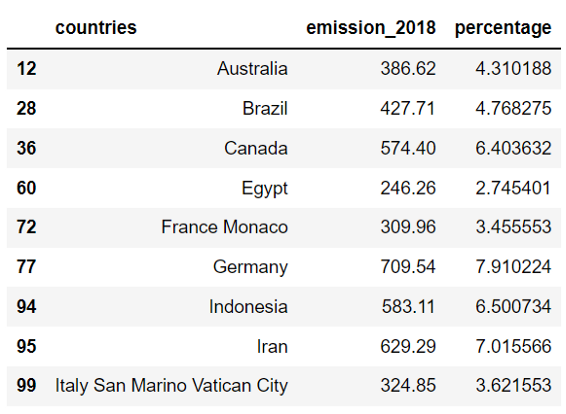
В качестве примера я выберу последний столбец, «Выбросы углекислого газа в 2018 / Общие, за исключением изменения методов использования земель и лесного хозяйства» и отфильтрую только страны с выбросами от 200 до 1000 MTCO2e (Метрических тонн эквивалента углекислого газа).
Приведенный ниже код можно изменять, если вы хотите использовать другие столбцы или другой диапазон выбросов CO2.
# Получаем списки данных
emi_ = df2018[('2018 CO2 emissions[21]', 'Total excluding LUCF[23]')]
country_ = list(df2018[('Country[20]', 'Country[20]')])
country_mod = [i.replace('\xa0',' ') for i in country_]
# Создаем DataFrame
df = pd.DataFrame(zip(country_mod,emi_), columns = ['countries', 'emission_2018'])
# Убираем строку о стране, которую нельзя конвертировать
df = df[df['countries']!='Serbia & Montenegro']
df.iloc[:,1] = df.iloc[:,1].astype('float')
df = df[(df['emission_2018']>200) & (df['emission_2018']<1000)]
df['percentage'] = [i*100/sum(df['emission_2018']) for i in df['emission_2018']]
df.head(9)
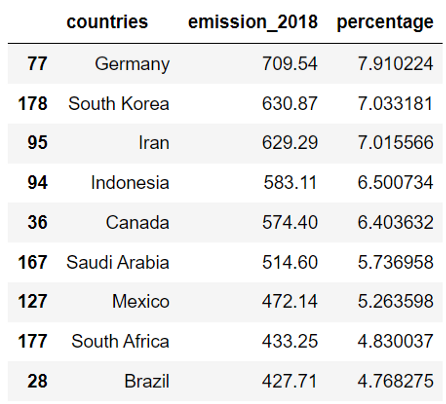
После получения DataFrame мы отсортируем выбросы углекислого газа, чтобы получить новую DataFrame. Оба DataFrame, обычный и отсортированный, будут использованы позже для прорисовки. Мы создаем два DataFrame для того, чтобы продемонстрировать, что результаты могут быть различными.
df_s = df.sort_values(by='emission_2018', ascending=False)
df_s.head(9)
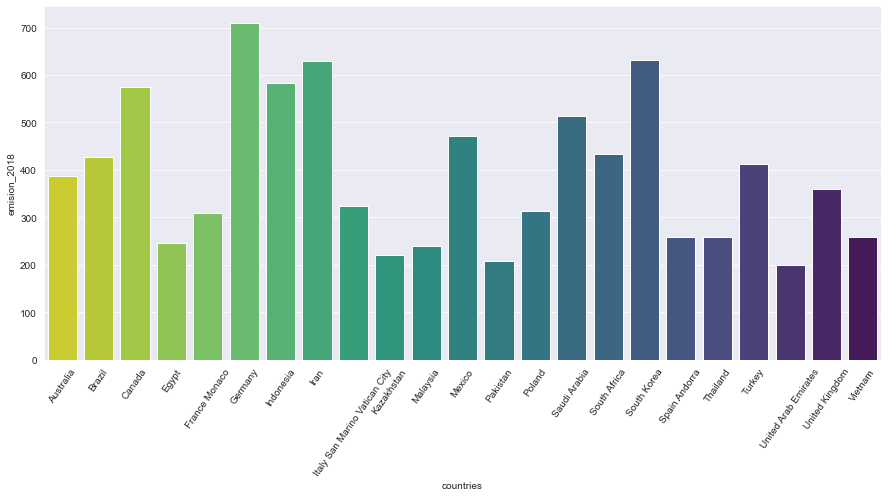
Теперь, когда все готово, давайте нарисуем гистограмму для будущего сравнения с другими методами визуализации.
plt.figure(figsize=(15,6.5))
sns.set_style('darkgrid')
g = sns.barplot(data=df, x='countries', y='emission_2018', ci=False, palette='viridis_r')
g.set_xticklabels(df['countries'], rotation=55, fontdict={'fontsize':10})
plt.show()
Прежде чем продолжить, определим функцию, возвращающую список цветов, которую мы будем использовать в каждой визуализации.
def get_color(name, number):
pal = list(sns.color_palette(palette=name, n_colors=number).as_hex())
return pal
Используем эту функцию для получения нескольких списков цветов:
pal_vi = get_color('viridis_r', len(df))
pal_plas = get_color('plasma_r', len(df))
pal_spec = get_color('Spectral', len(df))
pal_hsv = get_color('hsv', len(df))
Визуализации
В этой статье рассматривается 9 видов визуализации, которые можно разделить на две группы: изменение прямоугольных столбцов и изменение форм.
Изменение прямоугольных столбцов:
- Круговая диаграмма
- Радиальная гистограмма
- Древовидная диаграмма
- Вафельная диаграмма
- Интерактивная гистограмма
Изменение форм:
- Секторная диаграмма
- Лепестковая диаграмма
- Пузырьковая диаграмма
- Упаковка кругов
1. Изменение направления с помощью Круговой диаграммы (также известной как Гоночная диаграмма)
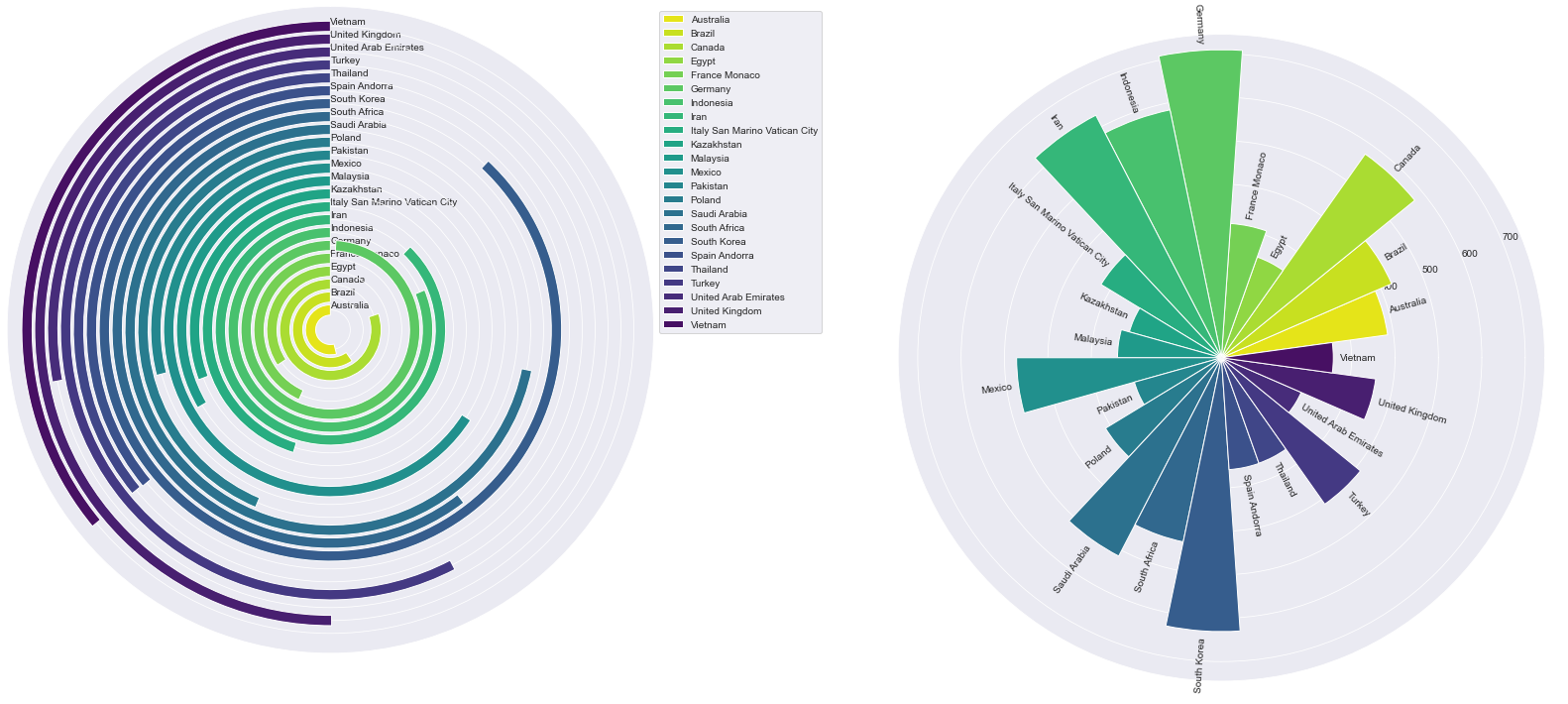
Концепция Круговой диаграммы заключается в «закрутке» столбцов диаграммы вокруг центра круга. Каждый столбец начинается с одного и того же градуса и движется в одном и том же направлении. Максимальное значение соответствует тому столбцу, который заполняет большую часть своего круга.
Это хорошая идея для привлечения внимания зрителей. Но при этом столбцы, заканчивающиеся на половине круга, трудно распознавать. Имейте в виду, что длина столбцов не одинакова: столбцы, находящиеся ближе к центру круга, короче столбцов, находящихся дальше.
Давайте нарисуем Круговую диаграмму для нашего DataFrame.
import math
plt.gcf().set_size_inches(12, 12)
sns.set_style('darkgrid')
# Установим максимальное значение
max_val = max(df['emission_2018'])*1.01
ax = plt.subplot(projection='polar')
# Зададим внутренний график
ax.set_theta_zero_location('N')
ax.set_theta_direction(1)
ax.set_rlabel_position(0)
ax.set_thetagrids([], labels=[])
ax.set_rgrids(range(len(df)), labels= df['countries'])
# Установим проекцию
ax = plt.subplot(projection='polar')
for i in range(len(df)):
ax.barh(i, list(df['emission_2018'])[i]*2*np.pi/max_val,
label=list(df['countries'])[i], color=pal_vi[i])
plt.legend(bbox_to_anchor=(1, 1), loc=2)
plt.show()
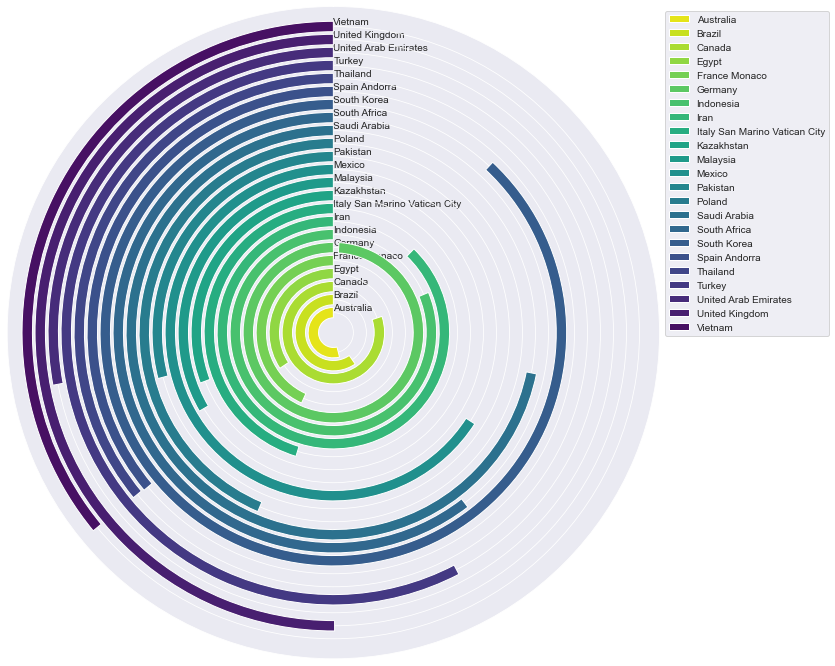
Нарисуем круговую диаграмму для отсортированного DataFrame.
import math
plt.gcf().set_size_inches(12, 12)
sns.set_style('darkgrid')
# Установим максимальное значение
max_val = max(df_s['emission_2018'])*1.01
ax = plt.subplot(projection='polar')
for i in range(len(df)):
ax.barh(i, list(df_s['emission_2018'])[i]*2*np.pi/max_val,
label=list(df_s['countries'])[i], color=pal_plas[i])
# Зададим внутренний график
ax.set_theta_zero_location('N')
ax.set_theta_direction(1)
ax.set_rlabel_position(0)
ax.set_thetagrids([], labels=[])
ax.set_rgrids(range(len(df)), labels= df_s['countries'])
# Установим проекцию
ax = plt.subplot(projection='polar')
plt.legend(bbox_to_anchor=(1, 1), loc=2)
plt.show()
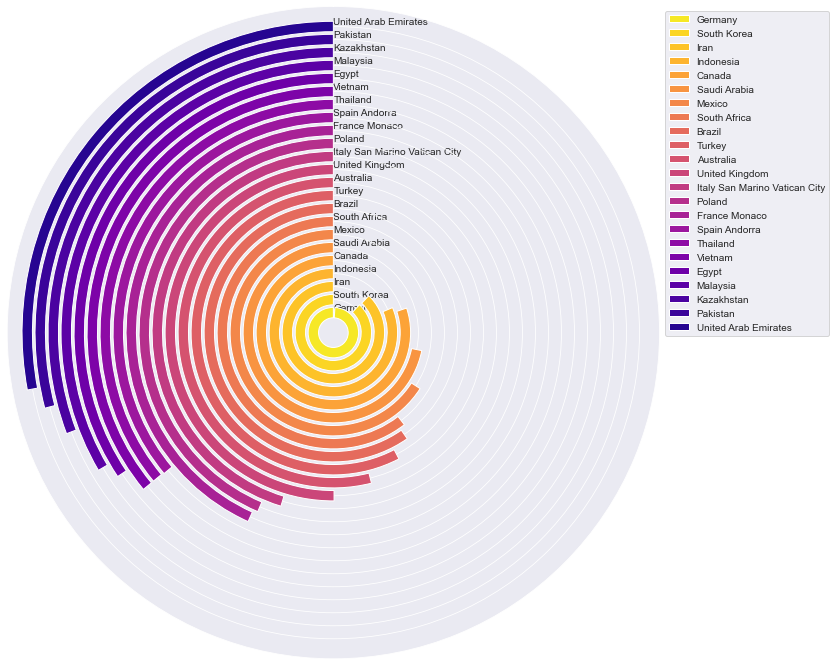
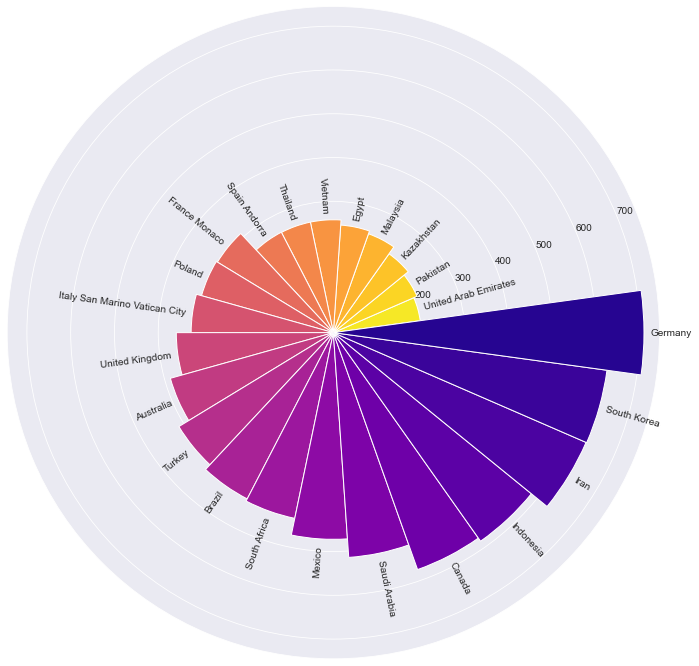
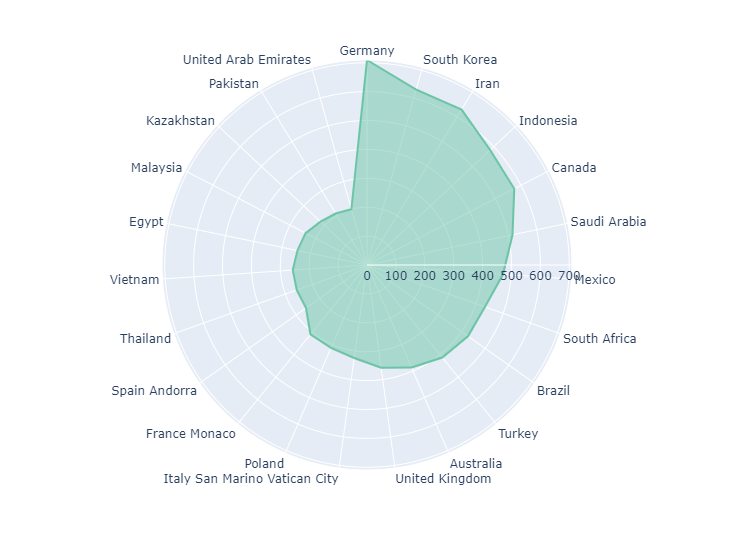
2. Начинаем от центра – Радиальная гистограмма
Концепция радиальной гистограммы заключается в изменении направления столбцов. Прежде все наши столбцы имели одно и то же направление, а теперь каждый столбец начинается от центра круга и движется в своем направлении к краю круга.
Пожалуйста, имейте в виду, что сравнивать столбцы, не находящиеся рядом, может быть трудно. Метки столбцов будут располагаться под разным углом, что может быть неудобно для зрителей.
Нарисуем Радиальную гистограмму для нашего исходного DataFrame.
plt.figure(figsize=(12,12))
ax = plt.subplot(111, polar=True)
plt.axis()
# Установим минимальное и максимальное значение
lowerLimit = 0
max_v = df['emission_2018'].max()
# Установим высоту и ширину
heights = df['emission_2018']
width = 2*np.pi / len(df.index)
# Установим индекс и угол
indexes = list(range(1, len(df.index)+1))
angles = [element * width for element in indexes]
bars = ax.bar(x=angles, height=heights, width=width, bottom=lowerLimit,
linewidth=1, edgecolor="white", color=pal_vi)
labelPadding = 15
for bar, angle, height, label in zip(bars,angles, heights, df['countries']):
rotation = np.rad2deg(angle)
alignment = ""
# Разберемся с направлением
if angle >= np.pi/2 and angle < 3*np.pi/2:
alignment = "right"
rotation = rotation + 180
else:
alignment = "left"
ax.text(x=angle, y=lowerLimit + bar.get_height() + labelPadding,
s=label, ha=alignment, va='center', rotation=rotation,
rotation_mode="anchor")
ax.set_thetagrids([], labels=[])
plt.show()
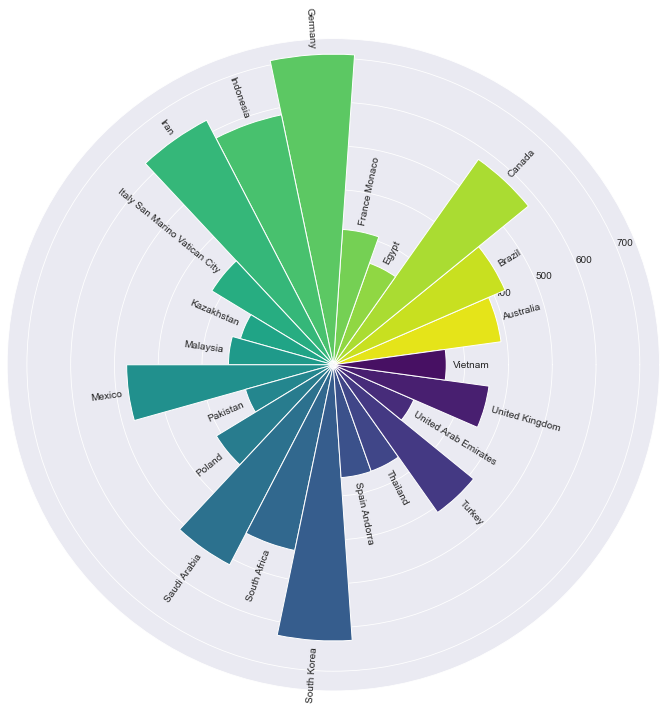
Теперь нарисуем радиальную гистограмму для отсортированного DataFrame
plt.figure(figsize=(12,12))
ax = plt.subplot(111, polar=True)
plt.axis()
# Установим минимальное и максимальное значение
lowerLimit = 0
max_v = df_s['emission_2018'].max()
# Установим высоту и ширину
heights = df_s['emission_2018']
width = 2*np.pi / len(df_s.index)
# Установим индекс и угол
indexes = list(range(1, len(df_s.index)+1))
angles = [element * width for element in indexes]
bars = ax.bar(x=angles, height=heights, width=width, bottom=lowerLimit,
linewidth=1, edgecolor="white", color=pal_plas)
labelPadding = 15
for bar, angle, height, label in zip(bars,angles, heights, df_s['countries']):
rotation = np.rad2deg(angle)
alignment = ""
# Разберемся с направлением
if angle >= np.pi/2 and angle < 3*np.pi/2:
alignment = "right"
rotation = rotation + 180
else:
alignment = "left"
ax.text(x=angle, y=lowerLimit + bar.get_height() + labelPadding,
s=label, ha=alignment, va='center', rotation=rotation,
rotation_mode="anchor")
ax.set_thetagrids([], labels=[])
plt.show()
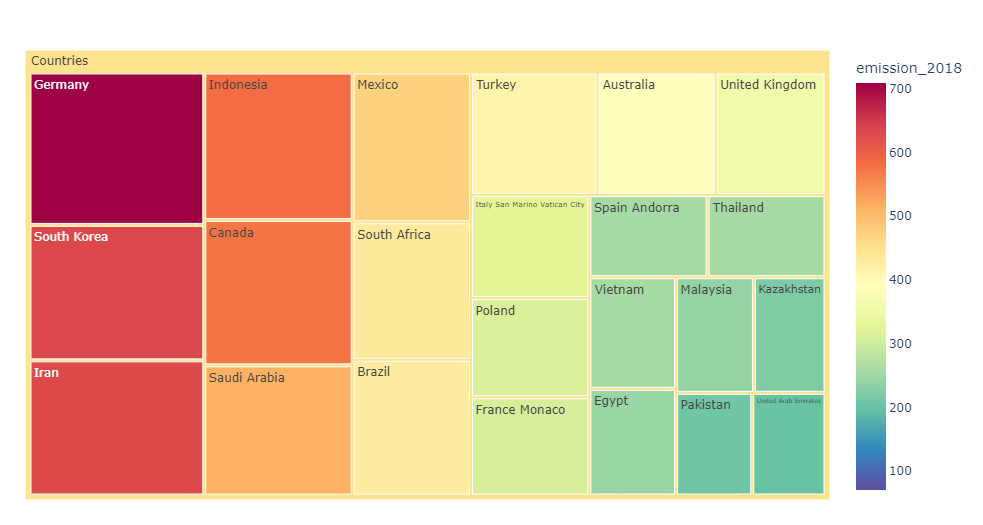
3. Используем для сравнения площадь в древовидной диаграмме
Древовидная диаграмма изображает иерархические данные в виде площадей прямоугольников. Несмотря на то, что наши данные не имеют иерархии, мы все-таки можем применить древовидную диаграмму, показав только один уровень иерархии.
При отрисовке древовидной диаграммы данные обычно сортируются по убыванию – от максимальных к минимальным. Если прямоугольников много, имейте в виду, что самые мелкие из них может быть трудно заметить или отделить друг от друга.
Создадим интерактивную древовидную диаграмму с помощью Plotly.
import plotly.express as px
fig = px.treemap(df, path=[px.Constant('Countries'), 'countries'],
values=df['emission_2018'],
color=df['emission_2018'],
color_continuous_scale='Spectral_r',
color_continuous_midpoint=np.average(df['emission_2018'])
)
fig.update_layout(margin = dict(t=50, l=25, r=25, b=25))
fig.show()
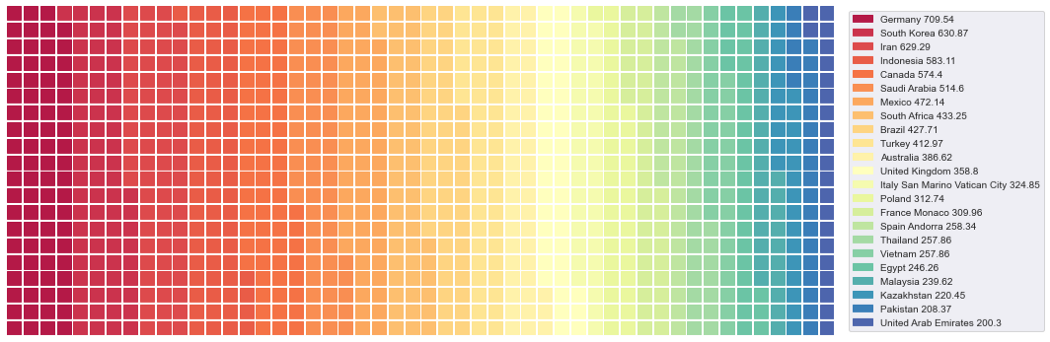
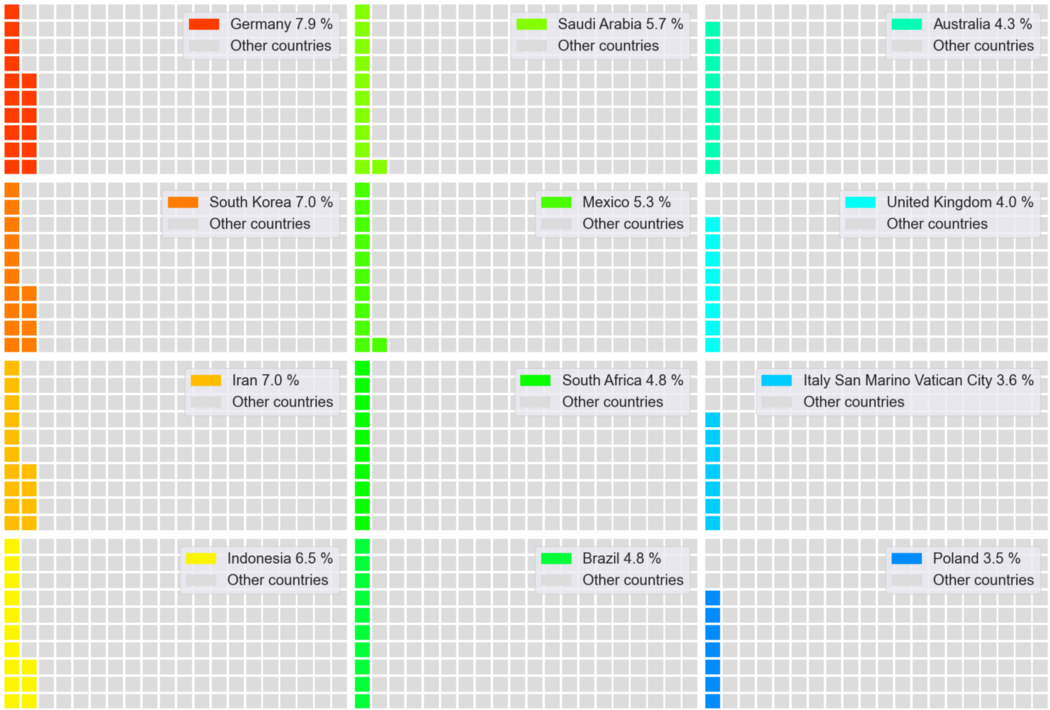
4. Собираем Вафельную диаграмму из маленьких квадратов
Вафельная диаграмма не только имеет забавное название – это очень хорошая идея для создания инфографики. Она состоит из множества маленьких квадратиков, вместе образующих большой прямоугольник – итоговый результат похож на вафлю.
Обычно прямоугольники выстраиваются квадратами 10*10, чтобы показать процент прогресса. Между прочим, количество квадратов можно менять, чтобы оно соответствовало данным.
Нарисуем вафельную диаграмму, изображающую выбросы CO2 для каждой страны.
#!pip install pywaffle
from pywaffle import Waffle
fig = plt.figure(FigureClass=Waffle,
rows=20,
columns=50,
values=list(df_s['emission_2018']),
colors=pal_spec,
labels=[i+' '+format(j, ',') for i,j in zip(df_s['countries'], df_s['emission_2018'])],
figsize = (15,6),
legend={'loc':'upper right',
'bbox_to_anchor': (1.26, 1)
})
plt.tight_layout()
plt.show()
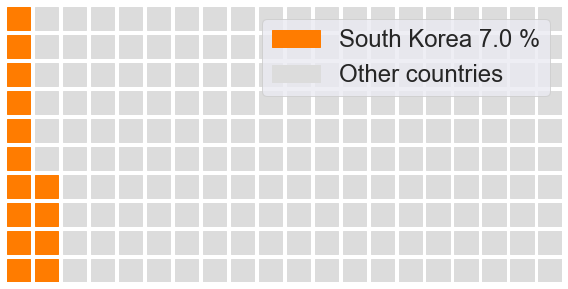
Этот результат может выглядеть цветным и привлекательным, но очень трудно различать похожие оттенки цветов. Это можно считать ограничением вафельной диаграммы. Поэтому считается, что вафельную диаграмму лучше всего использовать для небольшого количества категорий.
Чтобы избежать сложностей восприятия, давайте покажем каждую страну по одной, против всех остальных стран, а потом соберем коллаж. При работе со следующим кодом, пожалуйста, имейте в виду, что графики будут экспортированы на ваш компьютер для дальнейшего импорта. Нарисуем вафельные диаграммы для каждой страны.
save_name = []
for i,p,n,c in zip(df_s['emission_2018'], df_s['percentage'], df_s['countries'], pal_hsv):
fig = plt.figure(FigureClass=Waffle,
rows=10, columns=20,
values=[i, sum(df_s['emission_2018'])-i],
colors=[c,'gainsboro'],
labels=[n + ' ' + str(round(p,1)) +' %','Other countries'],
figsize = (8,8),
legend={'loc':'upper right', 'bbox_to_anchor': (1, 1), 'fontsize':24}
)
save_name.append('waffle_'+ n + '.png')
plt.tight_layout()
plt.savefig('waffle_'+ n + '.png', bbox_inches='tight') #export_fig
plt.show()
Теперь, когда у нас есть вафельные диаграммы для каждой страны, давайте определим функцию для создания фотоколлажа. Я нашел отличный код для объединения графиков на StackOverflow (ссылка):
from PIL import Image
def get_collage(cols_n, rows_n, width, height, input_sname, save_name):
c_width = width//cols_n
c_height = height//rows_n
size = c_width, c_height
new_im = Image.new('RGB', (width, height))
ims = []
for p in input_sname:
im = Image.open(p)
im.thumbnail(size)
ims.append(im)
i, x, y = 0,0,0
for col in range(cols_n):
for row in range(rows_n):
print(i, x, y)
try:
new_im.paste(ims[i], (x, y))
i += 1
y += c_height
except IndexError:
pass
x += c_width
y = 0
new_im.save(save_name)
Применим эту функцию, чтобы получить фотоколлаж.
# Чтобы создать фотоколлаж:
# width = number of columns * figure width
# height = number of rows * figure height
get_collage(5, 5, 2840, 1445, save_name, 'Collage_waffle.png')
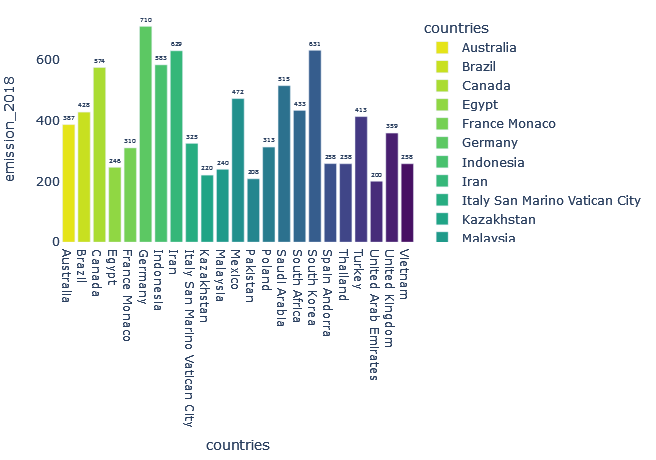
5. Ничего не меняем, но делаем гистограмму интерактивной
Мы можем сделать обычную гистограмму интерактивной. Это отличная идея, если вы собираетесь продолжать использовать эту гистограмму. С полученным результатом можно играть или фильтровать его любым удобным для вас способом. Plotly – это полезная библиотека, которая позволит легко создавать интерактивные гистограммы.
Единственная проблема – это научить конечных пользователей использовать интерактивную гистограмму – придется предоставить инструкцию, объясняющую, как использовать гистограмму. Давайте создадим интерактивную гистограмму.
import plotly.express as px
fig = px.bar(df, x='countries', y='emission_2018', text='emission_2018',
color ='countries', color_discrete_sequence=pal_vi)
fig.update_traces(texttemplate='%{text:.3s}', textposition='outside')
fig.update_layout({'plot_bgcolor': 'white',
'paper_bgcolor': 'white'})
fig.update_layout(width=1100, height=500,
margin = dict(t=15, l=15, r=15, b=15))
fig.show()
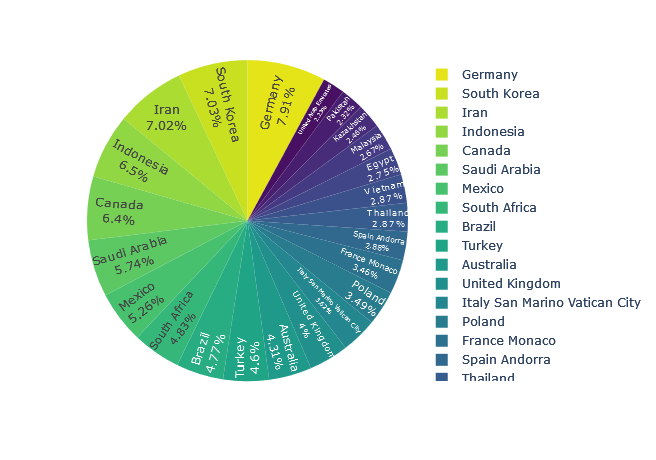
6. Показываем проценты в секторной диаграмме
Секторная диаграмма – это еще один привычный вид графика в визуализации данных. Это кругообразный статистический график, разделенный на секторы, чтобы показать числовые пропорции. Обычную секторную диаграмму можно сделать интерактивной, чтобы результат можно было настроить или отфильтровать. Для создания интерактивной секторной диаграммы можно использовать Plotly.
import plotly.express as px
fig = px.pie(df_s, values='emission_2018', names='countries',
color ='countries', color_discrete_sequence=pal_vi)
fig.update_traces(textposition='inside',
textinfo='percent+label',
sort=False)
fig.update_layout(width=1000, height=550)
fig.show()
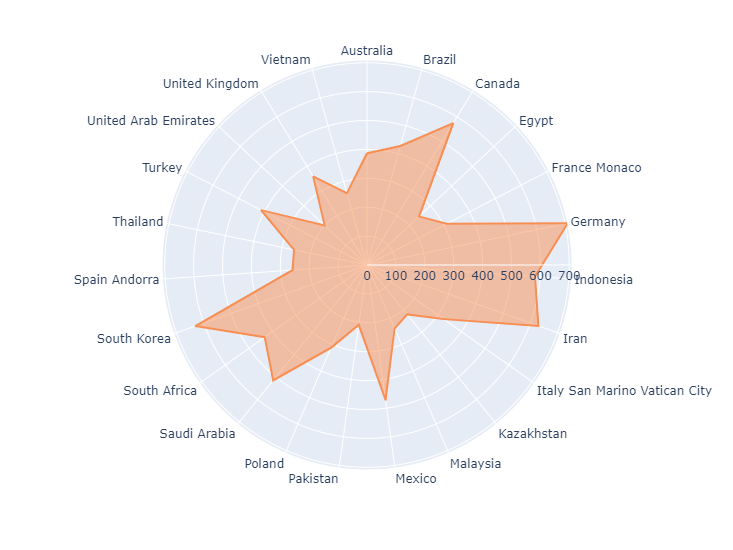
7. Чертим Лепестковую диаграмму внутри круга
Лепестковая диаграмма – это графический метод изображения многовариантных данных. Для сравнения, гистограммы обычно используются для категориальных данных. Чтобы создать лепестковую диаграмму, можно считать каждую категорию переменной в многовариантных данных. Значение каждой категории будет чертиться от центра.
Если категорий много, зрителям может быть трудно сравнивать данные, не расположенные рядом друг с другом. Эту проблему можно решить, рисуя лепестковую диаграмму для отсортированных данных. При этом зрители смогут определить, какие значения больше или меньше прочих.
Давайте нарисуем лепестковую диаграмму для нашего DataFrame.
import plotly.express as px
fig = px.line_polar(df, r='emission_2018',
theta='countries', line_close=True)
fig.update_traces(fill='toself', line = dict(color=pal_spec[5]))
fig.show()
Теперь нарисуем лепестковую диаграмму для отсортированного DataFrame
import plotly.express as px
fig = px.line_polar(df_s, r='emission_2018',
theta='countries', line_close=True)
fig.update_traces(fill='toself', line = dict(color=pal_spec[-5]))
fig.show()
8. Пузырьковая диаграмма: много-много кружков
Теоретически, пузырьковая диаграмма – это диаграмма рассеяния с различными размерами точек, представляющих данные. Это идеальный график для представления трехмерных данных: X, Y и размеры точек данных.
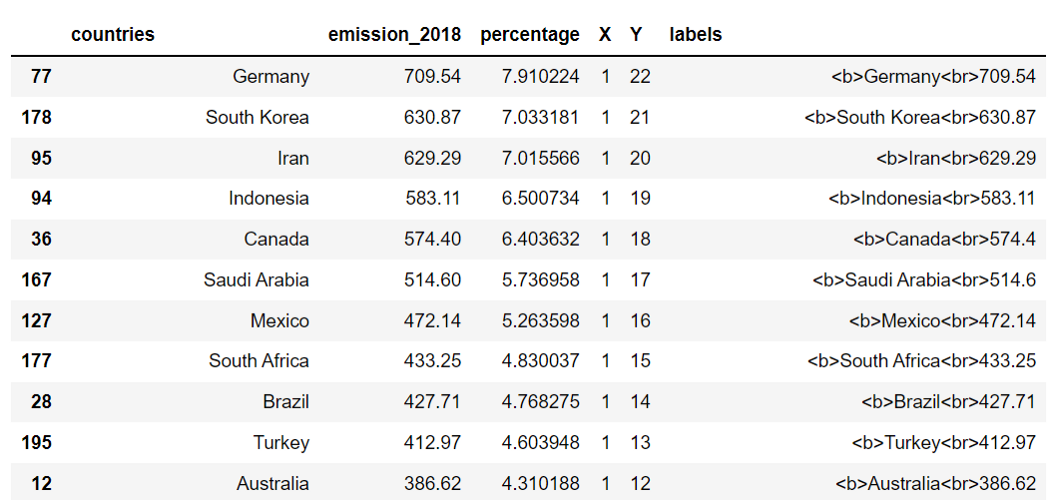
При создании пузырьковых диаграмм для категориальных данных хорошо то, что у них нет координат X и Y, и мы можем расположить кружки данных так, как захотим. Например, следующий код показывает, как разместить кружки данных вертикально.
Создайте список значений X, значений Y и меток. Затем добавьте их в качестве столбцов DataFrame. Если вы хотите разместить кружки горизонтально, поменяйте местами значения столбцов X и Y.
# Столбцы по осям X и Y
df_s['X'] = [1]*len(df_s)
list_y = list(range(0,len(df_s)))
list_y.reverse()
df_s['Y'] = list_y
# Столбец меток
df_s['labels'] = ['<b>'+i+'<br>'+format(j, ",") for i,j in zip(df_s['countries'], df_s['emission_2018'])]
df_s
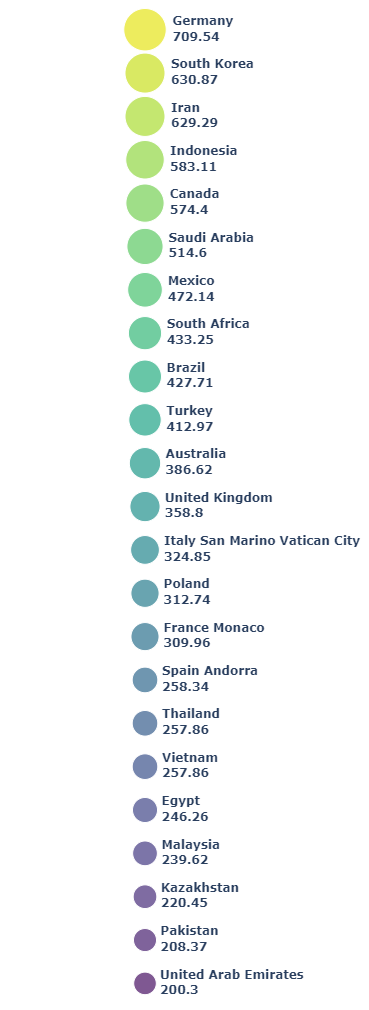
Теперь нарисуем нашу пузырьковую диаграмму.
import plotly.express as px
fig = px.scatter(df_s, x='X', y='Y',
color='countries', color_discrete_sequence=pal_vi,
size='emission_2018', text='labels', size_max=30)
fig.update_layout(width=500, height=1100,
margin = dict(t=0, l=0, r=0, b=0),
showlegend=False
)
fig.update_traces(textposition='middle right')
fig.update_xaxes(showgrid=False, zeroline=False, visible=False)
fig.update_yaxes(showgrid=False, zeroline=False, visible=False)
fig.update_layout({'plot_bgcolor': 'white',
'paper_bgcolor': 'white'})
fig.show()
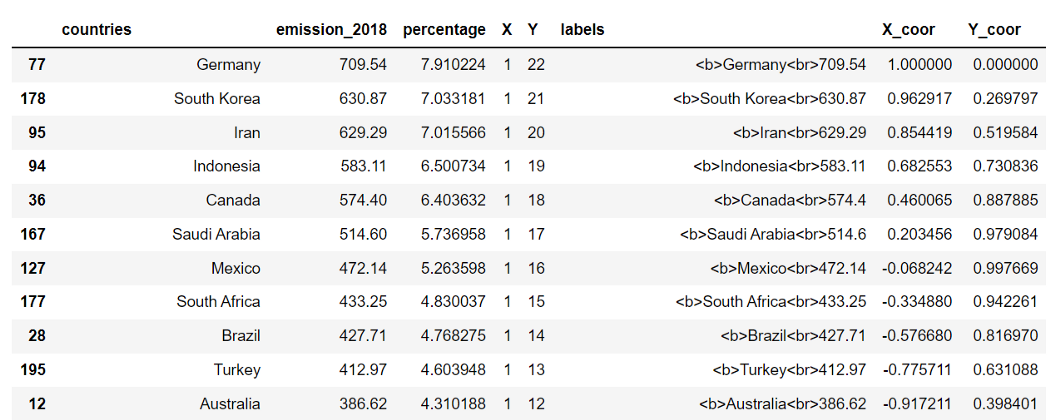
Чтобы продемонстрировать, что мы можем изображать пузыри в различных формах, давайте попробуем расположить их по кругу.
Чтобы сделать это, нам нужно рассчитать координаты X и Y. Начнем с деления 360 градусов на количество строк в таблице данных. Затем получим координаты X и Y из градусов с помощью функций синуса и косинуса.
# Создаем координаты X и Y по кругу
e = 360/len(df)
degree = [i*e for i in list(range(len(df)))]
df_s['X_coor'] = [math.cos(i*math.pi/180) for i in degree]
df_s['Y_coor'] = [math.sin(i*math.pi/180) for i in degree]
df_s
Теперь нарисуем пузырьковую диаграмму по кругу.
import plotly.express as px
fig = px.scatter(df_s, x='X_coor', y='Y_coor',
color="countries", color_discrete_sequence=pal_vi,
size='emission_2018', text='labels', size_max=40)
fig.update_layout(width=800, height=800,
margin = dict(t=0, l=0, r=0, b=0),
showlegend=False
)
fig.update_traces(textposition='bottom center')
fig.update_xaxes(showgrid=False, zeroline=False, visible=False)
fig.update_yaxes(showgrid=False, zeroline=False, visible=False)
fig.update_layout({'plot_bgcolor': 'white',
'paper_bgcolor': 'white'})
fig.show()
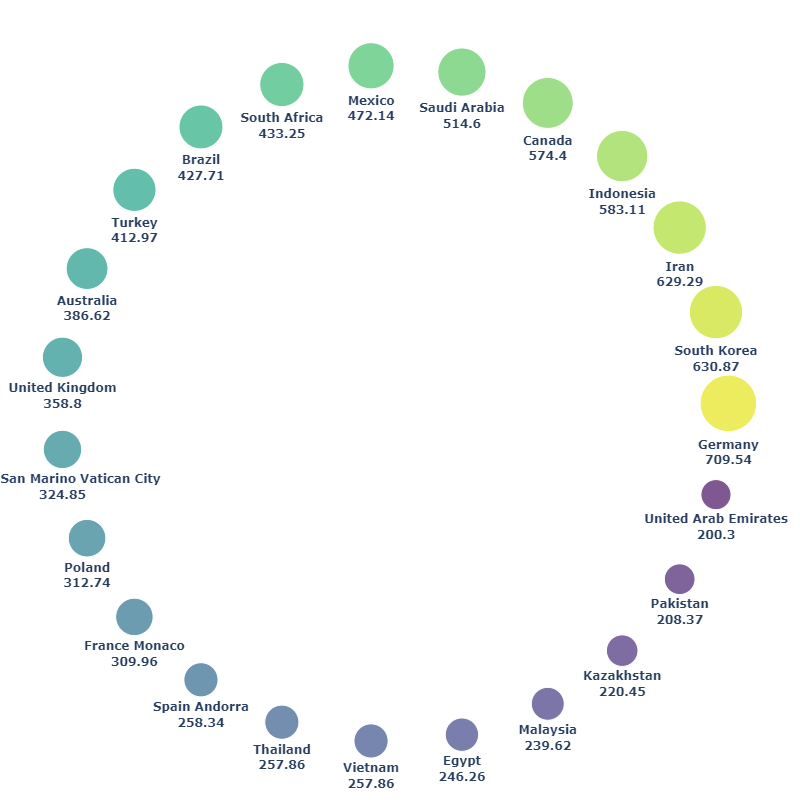
Можно заметить, что чем сложнее мы располагаем пузыри, тем больше места они занимают. Вертикальная или горизонтальная пузырьковые диаграммы помогут сэкономить пространство для других визуализаций.
9. Размещаем пузыри с Упаковкой круга
Наконец, давайте сгруппируем пузыри без перекрытий. Упаковка круга – это хорошая идея для рисования пузырей, не тратя лишнего пространства. Нам нужно рассчитать позиции и размеры каждого пузыря. К счастью, существует библиотека circlify, делающая эти расчеты простыми.
Недостаток Упаковки круга в том, что может быть трудно определить разницу между кругами, имеющими похожие размеры. Его можно устранить, помечая каждый круг его значением.
import circlify
# Рассчитываем позиции кругов:
circles = circlify.circlify(df_s['emission_2018'].tolist(),
show_enclosure=False,
target_enclosure=circlify.Circle(x=0, y=0)
)
circles.reverse()
Нарисуем круг, упакованный кругами.
fig, ax = plt.subplots(figsize=(14, 14), facecolor='white')
ax.axis('off')
lim = max(max(abs(circle.x)+circle.r, abs(circle.y)+circle.r,) for circle in circles)
plt.xlim(-lim, lim)
plt.ylim(-lim, lim)
# Рисуем круги
for circle, label, emi, color in zip(circles, df_s['countries'], df_s['emission_2018'], pal_vi):
x, y, r = circle
ax.add_patch(plt.Circle((x, y), r, alpha=0.9, color = color))
plt.annotate(label +'\n'+ format(emi, ","), (x,y), size=15, va='center', ha='center')
plt.xticks([])
plt.yticks([])
plt.show()
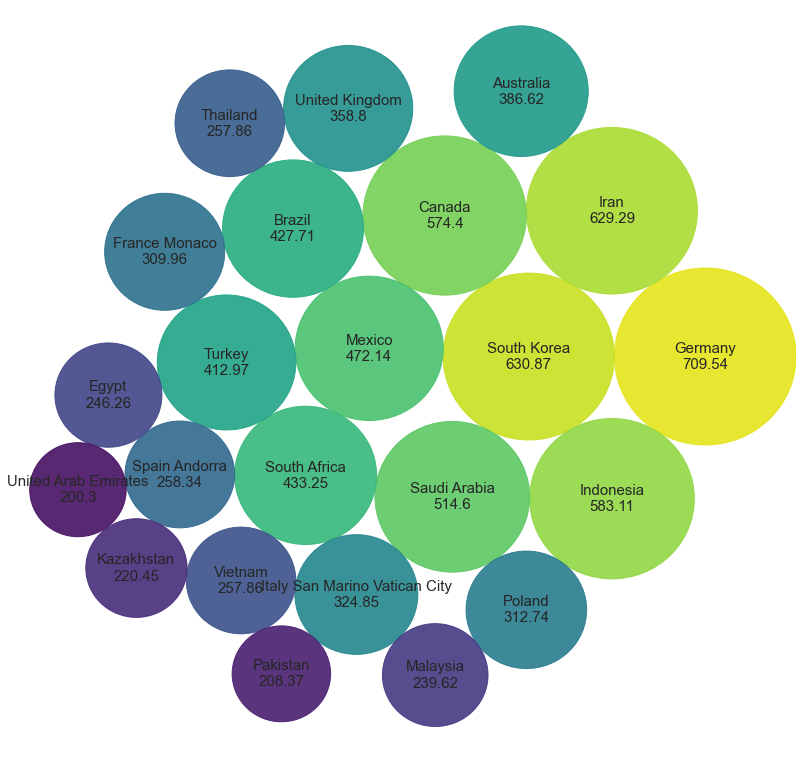
Заключение
В гистограммах нет ничего плохого. Они просты в понимании, и их легко построить. Однако разные виды графиков лучше подходят для различных целей. Иногда визуализация данных создается с целью привлечь внимание – например, при создании инфографики, и для этой цели гистограммы не очень подходят.
В этой статье показаны девять видов визуализации, использующих те же данные, на основе которых мы построили гистограмму, но привлекающих намного больше внимания. У этих видов также есть свои недостатки. Имейте в виду, что их может быть сложно интерпретировать, и они могут не годиться для официального отчета.
Спасибо за внимание!
Комментарии