

Ниже представлен сжатый обзор 25 инструментов для самых разнообразных приложений науки о данных. Быстрый скрапинг веб-страниц и визуализация, анализ поведения клиентов и безопасное хранение ключей, работа в команде и развертывание моделей на облачных GPU.
В комментариях к публикации предлагаем поделиться своими любимыми библиотеками и инструментами.
Обзор DS инструментов:
- Airtable: электронная таблица с мощью базы данных, альтернатива Google Sheets или Microsoft Excel. Отлично работает с Pandas, благодаря Python API. То что нужно для демонстрации результатов.
- Orange: open source платформа, заточенная под машинное обучение и визуализацию данных, для которой не нужно уметь кодить. Качественная альтернатива Tableau или Power BI.
- MarkDown: приложение для заметок на Node.js, полноценно работающее в офлайне с возможностью размещения на своём сервере.
- Deepnote: приложение на базе Jupyter Notebook, созданное для совместной работы в реальном времени.
- Dash by Plotly: JavaScript инструмент визуализации данных с открытым исходным кодом. Запустите готовую модель на Python или R, а Dash позаботится об остальном. Идеально подходит для создания мелких веб-приложений для показа клиенту.
- KeeWeb: средство для безопасного хранения API-ключей и паролей.
- MLxtend (сокр. от Machine Learning Extensions) – библиотека Python инструментов для повседневных задач обработки данных. Создатель – автор книги «Машинное обучение на Python» Себастьян Рашка.
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import itertools
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import EnsembleVoteClassifier
from mlxtend.data import iris_data
from mlxtend.plotting import plot_decision_regions
# Initializing Classifiers
clf1 = LogisticRegression(random_state=0)
clf2 = RandomForestClassifier(random_state=0)
clf3 = SVC(random_state=0, probability=True)
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3],
weights=[2, 1, 1], voting='soft')
# Loading some example data
X, y = iris_data()
X = X[:,[0, 2]]
# Plotting Decision Regions
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10, 8))
labels = ['Logistic Regression', 'Random Forest',
'RBF kernel SVM', 'Ensemble']
for clf, lab, grd in zip([clf1, clf2, clf3, eclf],
labels,
itertools.product([0, 1],
repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y,
clf=clf, legend=2)
plt.title(lab)
plt.show()
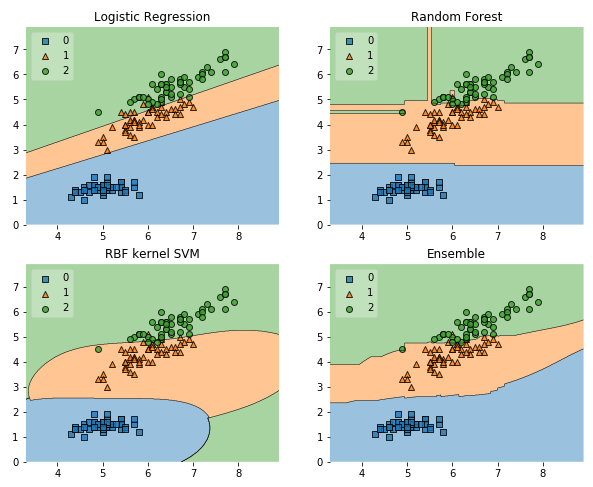
- Lifetimes: библиотека для анализа поведения клиентов, прогнозирования прибыли и оттока
- GitLab: альтернативное GitHub хранилище репозиториев с возможностью скрывать групповые репозитории. Удобно для закрытой командной работы и группового участия в ML-соревнованиях.
- Draw.io: создания диаграмм для планирования проекта.
- Spider: простой скраппер для веб-страниц в виде расширения Chrome. Можно скачивать страницы в CSV/JSON формате.
- Simple Scraper: превратите любой сайт в API.
- Airbnb Knowledge repo: ресурс для обмена знаниями между специалистами в области обработки данных и других технических профессий. Был создан для решения проблемы распространения знаний в рамках растущей команды.
- Kyso: сервис помогает создать привлекательное и структурированное портфолио аналитика данных. Вы сможете просматривать чужие портфолио, увидите, как другие представляют себя и свои данные. Бесплатный период 14 дней.
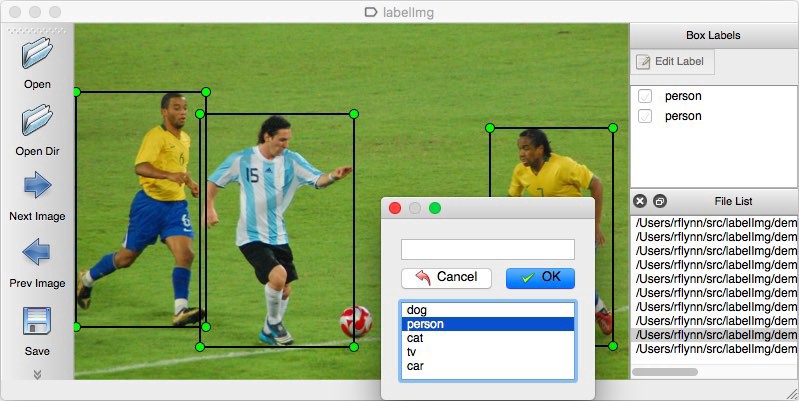
- LabelImg: графический инструмент для разметки объектов на картинках, добавление подписей и тегов изображений.
- Reveal.js: фреймворк для создания HTML-презентаций. Многие аналитики используют его на своих выступлениях.
- PythonAnywhere: простой способ развернуть онлайн лёгкий ML-проект на Python и сопутствующих библиотеках, если пока требуется лишь проверить гипотезу. В случае успеха легко перенести на AWS (руководство).
- Sheety: превратите Google Sheet в API и моделируйте данные в реальном времени.
- Jupyterthemes: устали от текущей темы Jupyter Notebook? Есть много других.
- Light GBM: одна из популярных библиотек для односторонней выборки на основе градиента. В последние годы приобрела большую популярность, особенно на Kaggle.
- Machine Learning A-Z: Practice Datasets and Codes: большое собрание данных и кода на Python и R, охватывающее популярные алгоритмы машинного обучения.
- Gradient by Paperspace: запускайте блокноты Jupyter бесплатно на облачной машине, оснащённой графическими процессорами.
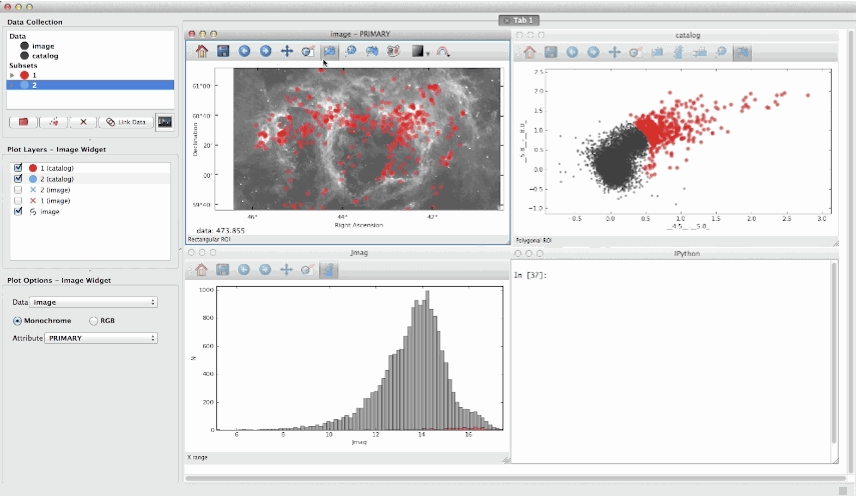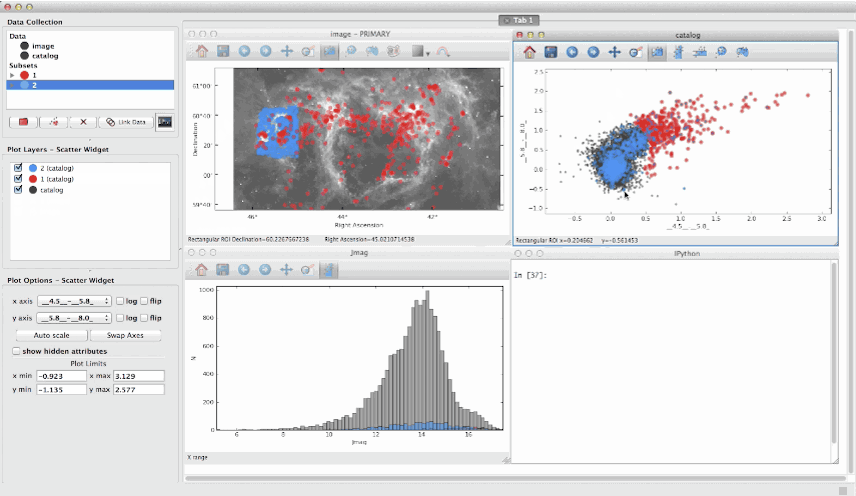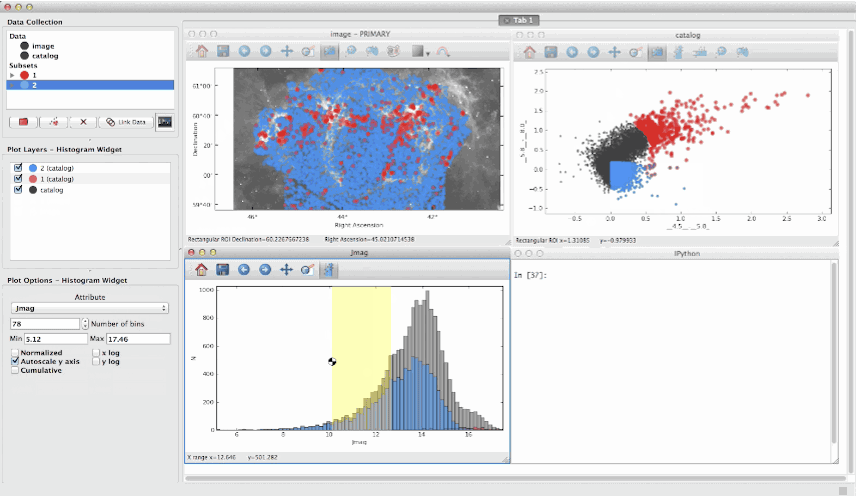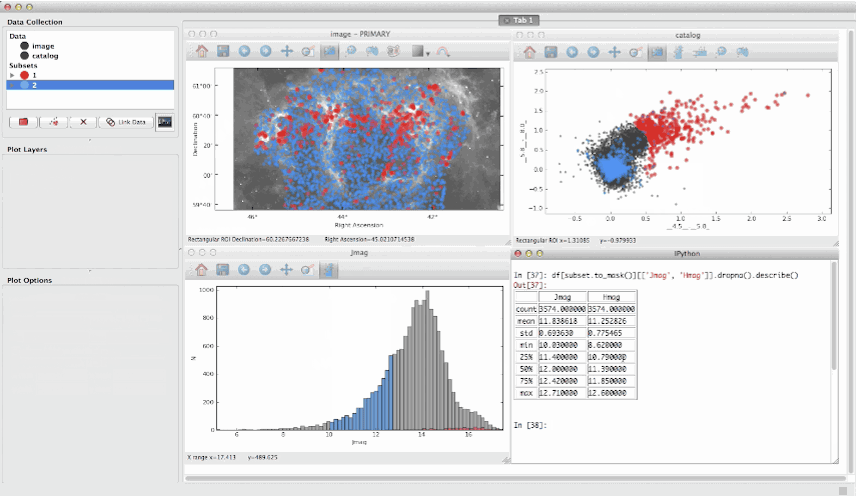
- Glueviz: визуализируйте многомерные наборы данных. Бесплатный инструмент на основе Python (поставляется с Anaconda). Отлично подходит для поиска связей между наборами данных.
- Hot dog or not hot dog?: мануал, не требующий знаний AI, машинного обучения и даже программирования. Руководство о том, как с IBM Watson написать программу для проверки, является ли объект хот-догом 🌭 или нет. Самый важный ресурс в подборке ;-)
- FloydHub Workspaces: облачная среда разработки для глубокого обучения. Можно запускать блокноты Jupyter, скрипты Python, использовать терминал и многое другое.
Комментарии