

ИИ-разработка — амбициозная, но вполне достижимая цель для тех, кто готов инвестировать время и усилия в обучение. В этой статье мы рассмотрим пять основных этапов подготовки, от изучения основ программирования и математики до освоения популярных фреймворков и работы с большими данными. Кроме того, вы найдете рекомендации и ресурсы, которые помогут закрепить теорию на практике и уверенно двигаться вперед.
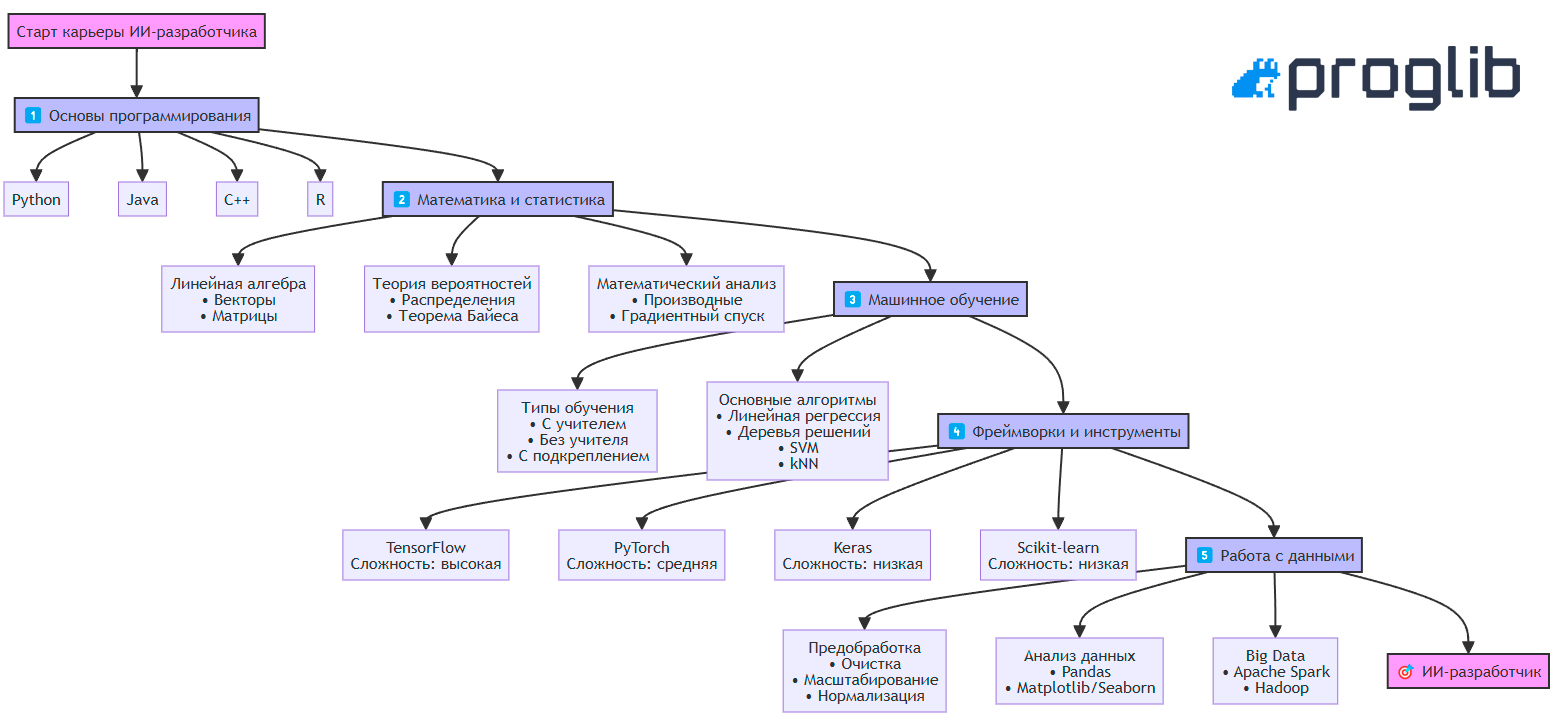
1. Изучите основы программирования
Прежде всего, необходимо выбрать язык программирования и освоить его основы. В разработке ИИ применяются:
- Python. Это самый популярный, к тому же несложный язык. Оптимальный выбор для ИИ.
- Java. Используется для разработки корпоративных систем и масштабируемых решений.
- C++. Часто используется в задачах, критичных к производительности, например, в играх и робототехнике.
- R. Подходит для анализа данных и статистики.
💡Рекомендация: не торопитесь с изучением программирования. Осваивайте теорию поэтапно, не срезая углы и ничего не пропуская. Обязательно закрепляйте теоретические знания практикой – для этого нужно делать небольшие проекты по каждой теме. Подборку идей учебных проектов для начинающих можно посмотреть здесь.

2. Освойте математику и статистику
Математика и статистика необходимы для создания и улучшения моделей. Математические знания позволяют понять, как именно работают ИИ-модели, и помогают сделать их более точными и эффективными. Статистика помогает анализировать данные, находить закономерности и делать прогнозы.
Основные темы:
1. Линейная алгебра. Изучите векторы, матрицы и операции над ними, так как они являются основой для нейронных сетей. Например, веса в нейросетях представлены в виде матриц.
👉Рекомендуемые ресурсы:
- Что такое линейная алгебра?
- Серия уроков на YouTube от 3Blue1Brown
- Плавное введение в линейную алгебру
2. Теория вероятностей и статистика. Необходимы для понимания, как модели ИИ делают прогнозы и справляются с неопределенностью. Важные темы:
- Распределение вероятностей
- Теорема Байеса
- Проверка гипотез
👉Рекомендуемые ресурсы:
- Теория вероятностей и статистика для Data Science и ИИ
- Продвинутый курс теорея вероятностей и статистики на Python
- Теорема Байеса: геометрия изменения убеждений

3. Математический анализ. Не все разработчики ИИ используют математический анализ ежедневно, но он важен для понимания того, как модели обучаются через оптимизацию (градиентный спуск). Основные темы:
- Производные
- Частные производные
- Цепное правило
👉Рекомендуемые ресурсы:
💡Рекомендация: не бойтесь математики — ИИ построен на ее основе, но не обязательно знать все сразу. Учите шаг за шагом, постепенно улучшая свои навыки. Для этого отлично подойдет YouTube-курс Математика для машинного обучения.
3. Изучите основы машинного обучения
Машинное обучение сосредоточено на том, чтобы научить ИИ-модель подражать человеческому обучению. Это позволяет моделям выполнять задачи автономно и повышать свою точность за счет опыта и работы с большим объемом данных.
Виды машинного обучения
Машинное обучение основано на предоставлении модели большого объема данных, чтобы она могла научиться делать прогнозы, находить закономерности или классифицировать данные. Выделяют три основных типа машинного обучения:
- Обучение с учителем. Модель обучается на размеченных данных, то есть на примерах с правильными ответами. Пример — предсказание стоимости дома на основе данных о прошлых продажах.
- Обучение без учителя. Модель ищет скрытые закономерности в неразмеченных данных. Пример — сегментация клиентов по поведению.
- Обучение с подкреплением. Модель обучается методом проб и ошибок, получая вознаграждение за правильные действия. Пример —обучение робота ходьбе.
👉Рекомендуемые ресурсы:
- Обучение с учителем
- Обучение без учителя
- Обучение с подкреплением
- Сравнение основных типов обучения
- Три типа машинного обучения, о которых нужно знать
Основные алгоритмы машинного обучения
Чтобы уверенно работать в области машинного обучения, важно понимать ключевые алгоритмы, которые используются для решения различных задач:
- Линейная регрессия. Применяется для прогнозирования непрерывных значений на основе линейной зависимости. Пример — прогнозирование прибыли компании.
- Деревья решений. Разделяют данные на группы на основе условий принятия решений. Пример — классификация покупателей на основе их предпочтений.
- Метод опорных векторов. Используется для классификации данных, создавая границу с максимальным отступом между классами. Пример — классификация изображений.
- Метод k-ближайших соседей. Работает путем поиска ближайших точек данных и делает предсказание на их основе. Пример — определение предпочтений пользователя на основе схожих пользователей.
👉Рекомендуемые ресурсы:
- Что такое линейная регрессия?
- Линейная регрессия в машинном обучении
- Деревья решений в машинном обучении
- Алгоритм метода опорных векторов
- Алгоритм метода k-ближайших соседей
- 10 типов алгоритмов машинного обучения
- Самые важные алгоритмы машинного обучения
💡Рекомендация: изучение алгоритмов — ключ к успешному освоению машинного обучения. Начните с простых моделей, постепенно переходя к более сложным.
🤖 Погружение в ML: от основ до практики
Команда Proglib Academy, объединяющая 800 000+ разработчиков, запустила компактный курс по базовым моделям ML: от ансамблевых методов до рекомендательных систем, с практикой на реальных кейсах и подготовкой к собеседованиям в tech-компании.
Ключевые моменты курса:
- Три концентрированных модуля: от ансамблевых методов до архитектур нейросетей.
- Практический подход к рекомендательным системам.
- Сочетание видеолекций и текстовых материалов для эффективного усвоения.
Особенно полезно для:
- Разработчиков, ищущих вход в ML.
- Математиков, готовых к практическому применению знаний.
- Начинающих в IT с интересом к машинному обучению.
4. Освойте фреймворки и вспомогательные инструменты для разработки ИИ
Для создания ИИ-систем необходимо освоить популярные фреймворки и инструменты: они помогают упростить процессы построения, обучения и развертывания моделей машинного обучения.
TensorFlow
- Язык: Python (основной), также поддерживаются C++, JavaScript (TensorFlow.js), Java, Go и Swift.
- Сложность: высокая
- Сайт: tensorflow.org
TensorFlow — мощный фреймворк для глубокого обучения, разработанный компанией Google. Он широко используется для построения и развертывания моделей машинного обучения, особенно в продакшене. TensorFlow обеспечивает гибкость, масштабируемость и обширную экосистему для полного цикла работы с моделями.
👉Рекомендуемые ресурсы:
PyTorch
- Язык: Python с частичной поддержкой C++
- Сложность: средняя
- Сайт: pytorch.org
PyTorch — популярный фреймворк для глубокого обучения с открытым исходным кодом, разработанный компанией Facebook (принадлежит экстремистской организации Meta, запрещенной на территории РФ). Он широко используется исследователями и учeными благодаря своей гибкости и динамическому вычислительному графу, который позволяет легко экспериментировать и отлаживать модели. PyTorch применяют:
- Для исследований и прототипирования новых архитектур нейронных сетей.
- В случаях, когда необходима гибкость и контроль над процессом обучения.
- При разработке сложных моделей, требующих частых изменений.
👉Рекомендуемые ресурсы:
Keras
- Язык: Python
- Сложность: низкая
- Сайт: keras.io
Keras — высокоуровневый API для быстрого прототипирования и простого использования нейронных сетей. Работает поверх TensorFlow и упрощает процесс создания, обучения и развертывания нейронных сетей. Keras идеально подходит для начинающих, может использоваться для решения широкого спектра задач машинного обучения — от классификации изображений до обработки естественного языка.
👉Рекомендуемые ресурсы:
- Официальная документация на keras.io
- Курс по основам глубокого обучения на Python, TensorFlow и Keras
Scikit-learn
- Язык: Python
- Сложность: низкая
- Сайт: scikit-learn.org
Scikit-learn — мощная библиотека для классического машинного обучения:
- Включает реализации многих популярных алгоритмов машинного обучения (деревья решений, метод опорных векторов, ближайших соседей и др.)
- Выполняет масштабирование, нормализацию и кодирование данных.
- Предоставляет инструменты для перекрестной проверки, подбора гиперпараметров и метрик оценки.
👉Рекомендуемые ресурсы:
5. Изучите все этапы обработки и анализа данных
Предварительная обработка данных
Перед тем как использовать данные в ИИ-моделях, важно правильно их подготовить. В сыром виде данные часто содержат ошибки, пропущенные значения и шум; предварительная обработка позволяет привести их в чистый и структурированный вид, готовый к использованию.
Основные этапы предварительной обработки:
- Обработка пропущенных значений — удаление или замена отсутствующих данных (например, средним значением или медианой).
- Масштабирование и нормализация данных — приведение данных к единому масштабу для улучшения работы моделей. Популярные методы — минимакс и стандартизация.
- Разделение данных — деление данных на обучающую и тестовую выборки (например, в пропорции 80/20 или 70/30) для оценки качества модели.
👉Рекомендуемые ресурсы:
- Предварительная обработка данных в машинном обучении: шаги и лучшие практики
- Полное руководство по обработке данных
Разведочный анализ данных (Exploratory Data Analysis, EDA)
EDA помогает понять структуру, закономерности и взаимосвязи внутри данных, что важно для выбора подходящих признаков и построения модели.
Основные аспекты EDA:
- Анализ с использованием библиотеки Pandas. Это мощный инструмент для работы с данными в Python, позволяющий вычислять статистические показатели, фильтровать и анализировать большие массивы данных.
- Визуализация данных — помогает выявить тренды, выбросы и зависимости между переменными с помощью графиков (гистограмм, диаграмм рассеяния, тепловых карт и т.д.) Популярные библиотеки — Matplotlib и Seaborn.
- Выявление закономерностей — анализ сезонности, трендов и корреляций (например, связь между временем подготовки и оценками студентов).
👉Рекомендуемые ресурсы:
- Что такое разведывательный анализ данных?
- Подробный туториал по решению задач Data Science на Python и Pandas
- Полный курс по основам Data Science и работе с Matplotlib
Инструменты для работы с большими данными
Если объем данных слишком велик для обработки традиционными инструментами, используются специализированные системы и фреймворки для работы с большими данными.
Основные инструменты:
- Apache Spark — распределенная система обработки данных, поддерживающая машинное обучение, потоковую обработку и пакетную аналитику. Подходит для анализа данных в реальном времени.
- Hadoop — фреймворк для распределенного хранения и обработки данных с использованием модели MapReduce. Менее популярен в ML, но часто используется для базового хранения данных.
Эти инструменты особенно полезны для работы с веб-аналитикой, системами рекомендаций, анализом социальных сетей, и обнаружением мошенничества, где объемы данных измеряются в терабайтах и петабайтах.
👉Рекомендуемые ресурсы:
В заключение
В 2025 году спрос на специалистов в области искусственного интеллекта продолжит расти, открывая новые карьерные возможности. Главное — подойти к обучению системно: освоить программирование, углубиться в математику, изучить ключевые алгоритмы машинного обучения и овладеть популярными инструментами. Начните с малого, ставьте перед собой реальные задачи, обязательно закрепляйте знания разработкой проектов и не бойтесь пробовать новые подходы — так вы сможете не только развить свои навыки, но и, возможно, внести вклад в будущее ИИ.
Комментарии