

Привет исследователям AI!
Меня зовут Марк Конаков, я развиваю NLP в компании Самолет. Мы разрабатываем чат-боты, занимаемся мэтчингом, строим модели для анализа звонков и многим другим. NLP – это только одна из голов DS-гидры Самолета, ребята из моей команды крутят классические модельки на табличках, строят рекомендательные системы, есть направление и по CV.
Конечно же, у меня есть телеграм-канал, где я пишу про NLP и в целом об AI. Приходите, иногда там интересно.
В последнее время я много писал о Langchain - мощном инструменте для создания приложений с использованием больших языковых моделей.
Если вы пропустили эти статьи, можно ознакомиться с ними на хабре: 1, 2, 3. Сегодня я хочу перейти к обсуждению еще одного хорошего проекта, который строится на основе Langchain и предоставляет централизованный интерфейс для связи ваших языковых моделей с внешними данными. Этот проект называется llamaindex.
Lamaindex – это фреймворк, который предоставляет удобные инструменты для работы с большими языковыми моделями. Он позволяет индексировать большие объемы текстовых данных и выполнять по ним эффективный поиск. Это особенно полезно при работе с большими языковыми моделями, которые могут генерировать текст на основе предоставленного контекста.
Основная цель llamaindex – облегчить работу с языковыми моделями, предоставив удобные инструменты для индексирования и поиска. Это позволяет разработчикам сосредоточиться на создании приложений и сервисов, использующих языковые модели, вместо того чтобы тратить время и ресурсы на решение технических проблем.
Я планирую написать несколько статей об этом крутом инструменте. Сегодня будет первое знакомство и helloworld примеры.
Установка и настройка окружения
Прежде чем мы начнем, нам нужно установить llamaindex и подготовить наше виртуальное окружение:
- Создание виртуального окружения с помощью conda: Для создания нового окружения с помощью conda выполните следующую команду:
conda create --name llamaindex_env python=3.10
- Активация виртуального окружения: После создания виртуального окружения, его нужно активировать:
conda activate llamaindex_env
- Установка llamaindex: После активации виртуального окружения, мы можем установить llamaindex с помощью pip:
pip install llama-index
- Регистрация ядра в Jupyter Notebook: Если вы планируете использовать Jupyter Notebook, вам нужно зарегистрировать ваше новое виртуальное окружение как ядро:
pip install jupyterlab ipykernel
python -m ipykernel install --user --name=llamaindex_env
Основные концепции llamaindex
llamaindex основан на концепции Retrieval Augmented Generation (RAG). В основе RAG лежит идея о том, что для генерации ответа на запрос можно использовать не только контекст запроса, но и дополнительные данные, найденные по индексу. Это позволяет генерировать более точные и информативные ответы.

В рамках llamaindex основные элементы RAG представлены следующими модулями:
- Data Connectors: Это модули, которые отвечают за загрузку и обработку данных. Они позволяют загрузить данные, создать из них узлы и построить индекс.
- Retrievers: Это модули, которые отвечают за поиск по индексу. Они позволяют выполнить поиск по индексу и получить наиболее релевантные узлы.
- Query Engines: Это модули, которые отвечают за генерацию ответа на запрос. Они используют информацию, полученную от retrievers, для генерации ответа.
Быстрый старт
Попробуем сразу ворваться в мир llamaindex и оценить возможности
Для начала создадим папку data и поместим туда один файл со стихотворением Пушкина лукоморье:
mkdir data
touch lukomorie.txt
Теперь можно создать список документов на основе нашего файла
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
Как и следовало ожидать, в списке у нас один документ с типом llama_index.schema.Document
Теперь попробуем проиндексировать наш документ в векторной базе, за это отвечает класс ChatGPTRetrievalPluginIndex В нем есть метод для создания индекса на основе списка документов from_documents. Векторных баз доступно множество:
GPTSimpleVectorIndex
GPTFaissIndex
GPTWeaviateIndex
GPTPineconeIndex
GPTQdrantIndex
GPTChromaIndex
GPTMilvusIndex
GPTDeepLakeIndex
GPTMyScaleIndex
Пока используем простой вариант GPTSimpleVectorIndex, но предварительно надо задать ключ API Open AI для использования модели эмбеддингов.
import os
os.environ['OPENAI_API_KEY'] = 'sk-L0xrKrmzb2KufEIi0***'
index = GPTVectorStoreIndex.from_documents(documents)
# переводим индекс в режим поискового движка
query_engine = index.as_query_engine()
# запрос к базе знаний
response = query_engine.query(
'сколько богатырей выходят из моря?'
)
print(response.response)

Запрос под капотом
В llamaIndex, query_engine - это объект, который управляет процессом поиска в индексе. Индекс представляет собой структуру данных, которая хранит "узлы" (Nodes). Узел соответствует фрагменту текста из документа. LlamaIndex принимает объекты документов и внутренне разбивает их на объекты узлов.
В нашем случае он ищет только по одной ноде, тк мы не разбивали наш текст на узлы.
Когда вы вызываете query_engine.query('ваш запрос'), вы задаете вопрос ('ваш запрос'), и query_engine ищет наиболее релевантные узлы в индексе, которые могут ответить на ваш вопрос. Это делается путем сравнения вашего запроса с каждым узлом в индексе и выбора наиболее релевантных узлов.

Важно отметить, что "релевантность" здесь определяется моделью, которая обучена понимать, какие узлы могут быть релевантными для определенного запроса. Это может включать в себя анализ семантического содержания запроса и узлов, а также другие факторы.
В результате query_engine.query('ваш запрос') возвращает ответ на ваш запрос, который сгенерирован на основе наиболее релевантных узлов.
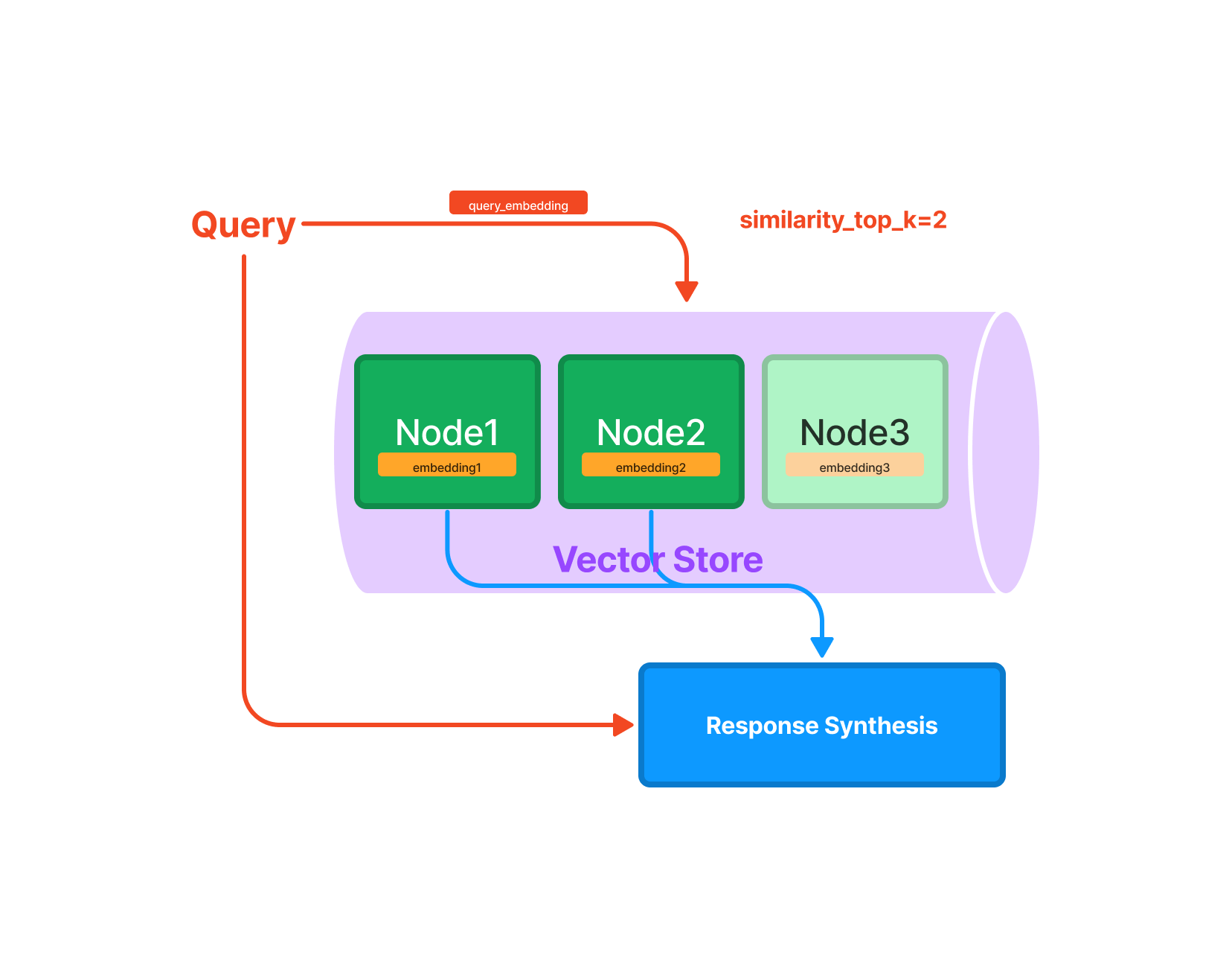
В LlamaIndex есть разные типы индексов, каждый из которых работает немного по-разному. Например, индекс векторного хранилища (VectorStoreIndex) хранит каждый узел и соответствующее ему векторное представление, и при поиске возвращает топ-k наиболее похожих узлов. Другой тип индекса, индекс таблицы ключевых слов (KeywordTableIndex), извлекает ключевые слова из каждого узла и строит отображение от каждого ключевого слова к соответствующим узлам этого ключевого слова. При поиске он извлекает релевантные ключевые слова из запроса и ищет соответствующие узлы.
Генерация ответа
После извлечения релевантной ноды данные попадают в Response Synthesis. Этот процесс берет данные из выбранных узлов и использует языковую модель для генерации окончательного ответа. Это может включать в себя и объединение информации из разных узлов, переформулирование информации, чтобы она была более понятной и т. д.
Процесс Response Synthesis может варьироваться в зависимости от конкретной конфигурации.
default: В этом режиме для каждого узла делается отдельный вызов языковой модели. Это позволяет создавать и уточнять ответ, последовательно проходя через каждый узел. Этот режим хорош для более подробных ответов.compact: В этом режиме во время каждого вызова языковой модели "упаковывается" максимальное количество текстовых блоков узлов, которые могут поместиться в пределах максимального размера запроса. Если блоков слишком много, чтобы поместить их в один запрос, ответ "создается и уточняется", проходя через несколько запросов.tree_summarize: В этом режиме, учитывая набор узлов и запрос, рекурсивно строится дерево и в качестве ответа возвращается корневой узел.
Эти режимы могут быть комбинированы с другими параметрами запроса, такими как required_keywords и exclude_keywords, которые позволяют фильтровать узлы на основе наличия или отсутствия определенных ключевых слов.
Модифицируем ответ
Попробуем теперь модифицировать ответ на наш вопрос. Для этого нам понадобится инструмент ServiceContext.
ServiceContext в LlamaIndex – это утилитный контейнер, который используется индексами и классами запросов и позволяет настроить различные аспекты работы LlamaIndex, включая то, какие модели и методы используются для обработки запросов и генерации ответов. Он содержит следующие компоненты:
llm_predictor: Это объект LLMPredictor, который используется для предсказания ответов языковой моделью.prompt_helper: Это объект PromptHelper, который помогает формировать запросы к языковой модели.embed_model: Это объект BaseEmbedding, который используется для создания векторных представлений узлов.node_parser: Это объект NodeParser, который используется для разбиения документов на узлы.llama_logger: Это объект LlamaLogger, который используется для логирования различных аспектов работы LlamaIndex.chunk_size_limit: Это ограничение на размер блока, которое определяет максимальное количество токенов, которые могут быть включены в один запрос к языковой модели.
Вы можете создать ServiceContext, используя метод from_defaults.
from llama_index import ServiceContext
from llama_index.llms import OpenAI
# Изменим модель
llm = OpenAI(temperature=0, model='gpt-3.5-turbo')
service_context = ServiceContext.from_defaults(llm=llm)
index = GPTVectorStoreIndex.from_documents(
documents,
service_context=service_context
)
engine = index.as_query_engine()
response = engine.query('сколько богатырей выходят из моря?')
print(response)

Видно, что ответ модели немного изменился. Вывод также можно менять через параметр temperature при инициализации LLM.


Заключение
Вводную часть можно завершать. В этой статье мы рассмотрели основные концепции и возможности llamaIndex, включая его ключевые компоненты, такие как узлы, индексы и движок запросов. Мы также рассмотрели, как настроить LlamaIndex и как он обрабатывает запросы и генерирует ответы. В следующих частях погрузимся глубже в детали работы с фреймворком и рассмотрим более продвинутые темы. В качестве учебного кейса рассмотрим создание чат-бота по собственной базе договоров.
Спасибо за внимание!
Комментарии