
Красочное интерактивное отображение датасета в одну строку? Не проблема с plotly! Разбираемся с построением интерактивных графиков и диаграмм.
Если спросить питонистов, какую библиотеку использовать для визуализации данных, то большинство, несомненно, ответят: matplotlib. Ответят, правда, без особого удовольствия. Многое в matplotlib не так уж очевидно и требует не раз обратиться к StackOverflow. Касается это и таких распространенных ситуаций, как создание дополнительных осей или отображение на них дат.
Нужно понимать, что matplotlib создавался задолго до бурного развития Data Science, и в большей мере ориентировался на отображение массивов NumPy и параметрических функций SciPy. В то же время в Data Science распространен обобщающий тип объектов – датасеты, крупные таблицы с данными. В этой статье мы нырнем в работу с альтернативной библиотекой – plotly – и научимся визуализировать множество самых необходимых вещей.
Весь код доступен на GitHub. Интерактивные графики можно (и нужно) смотреть на NBViewer. Приводимые куски кода будут отображать только минимальную часть, необходимую для визуализации данных. Предподготовка данных – в указанных источниках.
Краткий обзор plotly
Пакет plotly – библиотека с открытым исходным кодом, построенная на plotly.js, которая, в свою очередь, базируется на d3.js. В своих экспериментах с кодом будем использовать обертку над plotly cufflinks. Она упрощает работу с датафреймами pandas. Plotly – это графическая компания, производящая несколько продуктов и инструментов с открытым исходным кодом. Библиотека бесплатна для использования и позволяет создавать неограниченное количество графиков в автономном режиме, а также до 25 диаграмм онлайн.
Вся работа статье была сделана в блокноте Jupyter в связке plotly+cufflinks, которые можно установить стандартным образом с помощью pip:
pip install cufflinks plotly
Соответствующий импорт Python библиотек:
# Стандартное импортирование plotly import plotly.plotly as py import plotly.graph_objs as go from plotly.offline import iplot # Использование cufflinks в офлайн-режиме import cufflinks cufflinks.go_offline() # Настройка глобальной темы cufflinks cufflinks.set_config_file(world_readable=True, theme='pearl', offline=True)
Перейдем к примерам.
Распределение единственной переменной: гистограммы и боксплоты
Построение распределения переменной – стандартный способ начального анализа данных. При помощи plotly легко сделать интерактивное представление гистограмм и прочих распределений. Для тех, кто использовал ранее matplotlib, нужно вместо команды plot просто использовать iplot:
df['claps'].iplot(kind='hist', xTitle='claps',
yTitle='count', title='Claps Distribution')
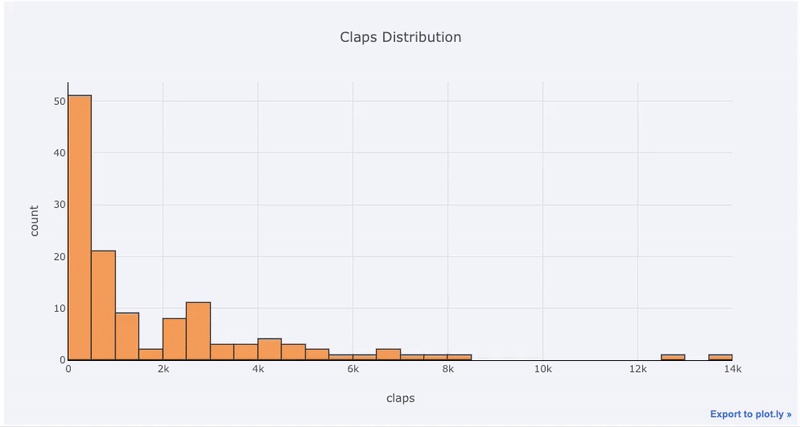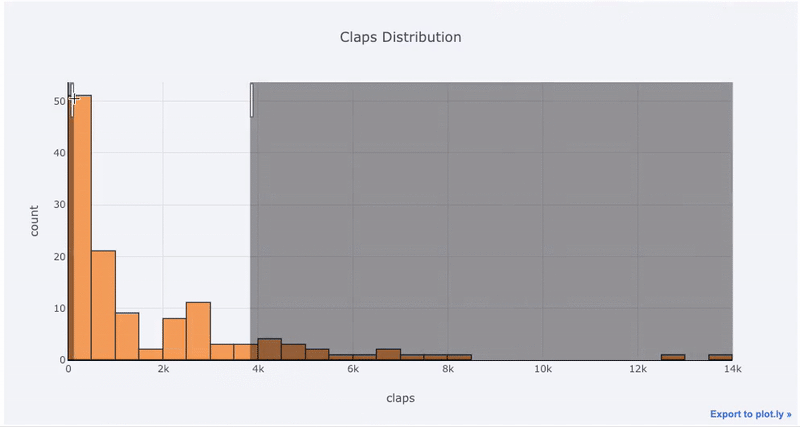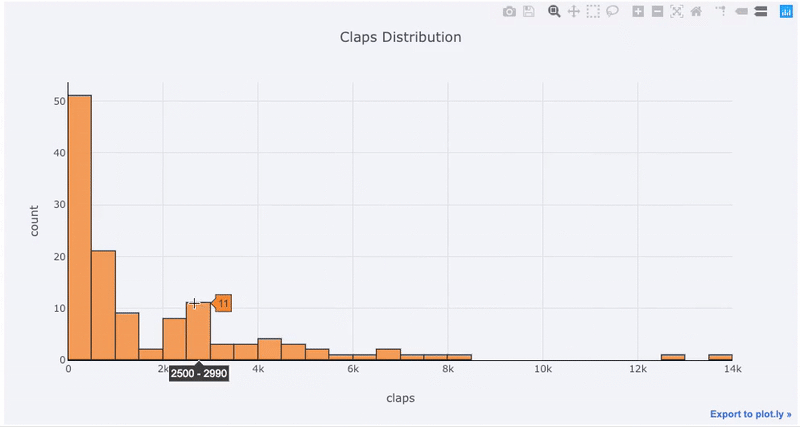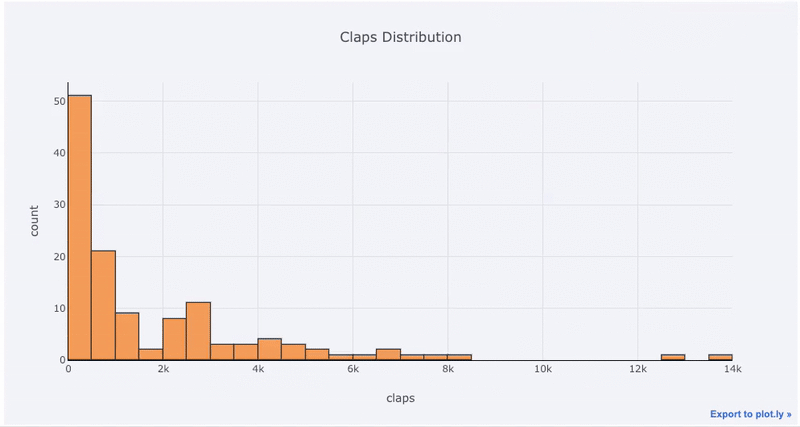
Если мы хотим сравнить распределение двух переменных, можем наложить две гистограммы друг на друга:
df[['time_started', 'time_published']].iplot(
kind='hist',
histnorm='percent',
barmode='overlay',
xTitle='Time of Day',
yTitle='(%) of Articles',
title='Time Started and Time Published')
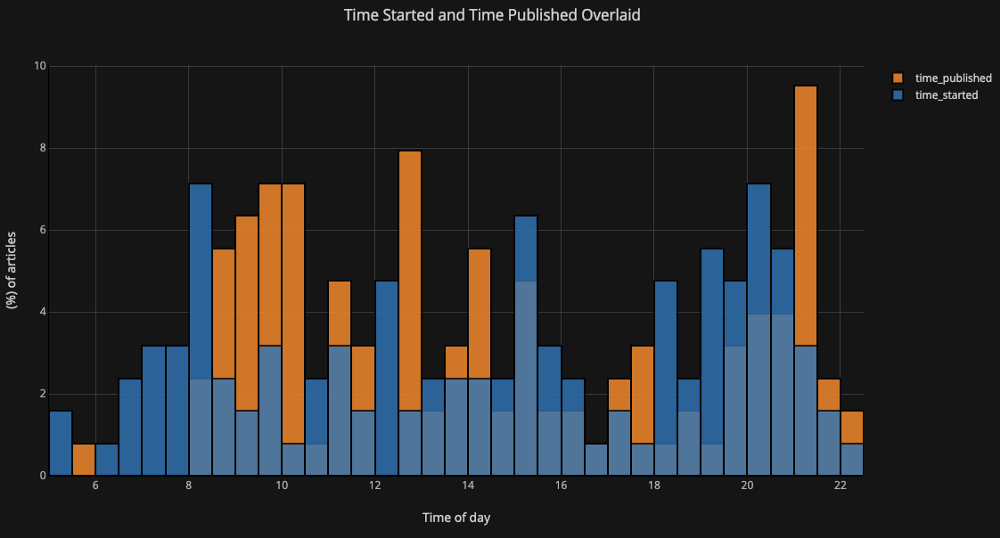
Проведя некоторые манипуляции в pandas, получаем диаграмму с распределением относительно времени:
df2 = df[['view','reads','published_date']].\
set_index('published_date').\
resample('M').mean()
df2.iplot(kind='bar', xTitle='Date', yTitle='Average',
title='Monthly Average Views and Reads')
Комбинируя мощь pandas и plotly, легко получать интерактивные сводные диаграммы:
df.pivot(columns='publication', values='fans').iplot(
kind='box',
yTitle='fans',
title='Fans Distribution by Publication')
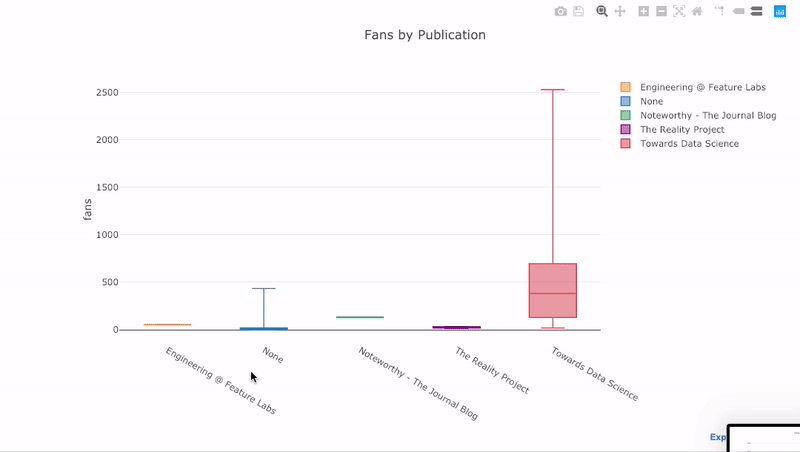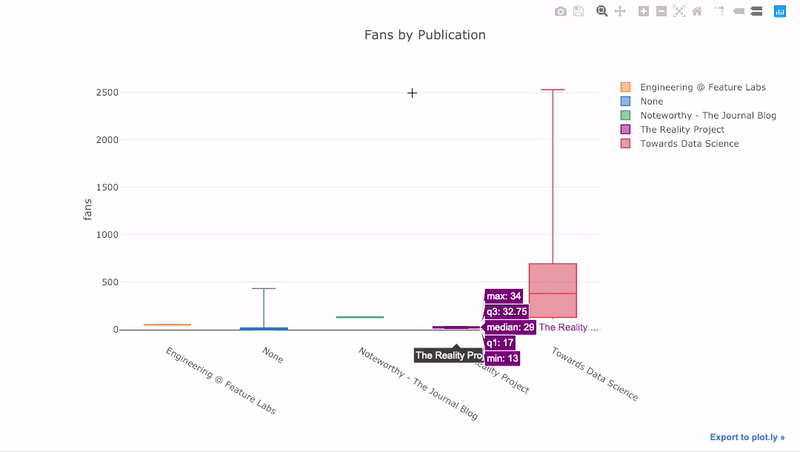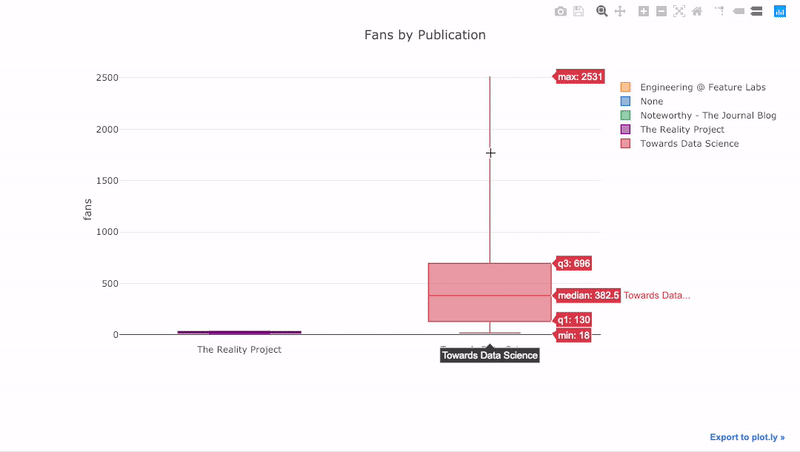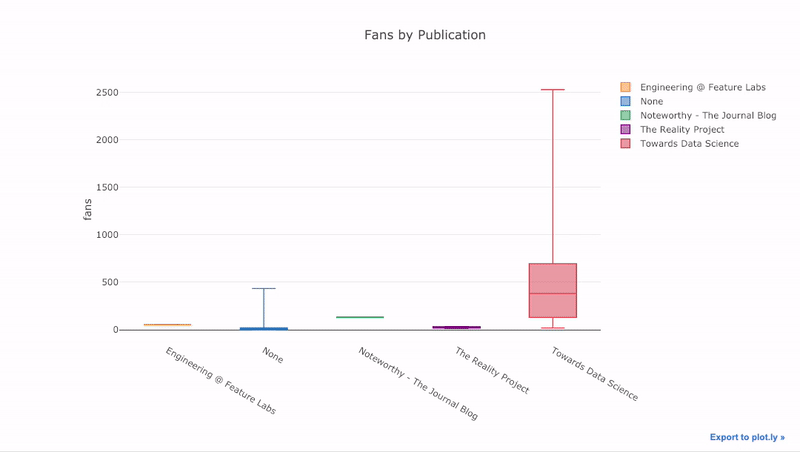
Интерактивное представление позволяет не загромождать исходный график избыточной информацией, обращаясь к ней по необходимости.
Временные ряды
Одна из распространенных задач – отображение данных относительно временной шкалы. Здесь актуальна возможность выбора интересующего интервала для отслеживания тренда.
tds = df[df['publication'] == 'Towards Data Science'].\
set_index('published_date')
tds[['claps', 'fans', 'title']].iplot(
y='claps', mode='lines+markers', secondary_y = 'fans',
secondary_y_title='Fans', xTitle='Date', yTitle='Claps',
text='title', title='Fans and Claps over Time')
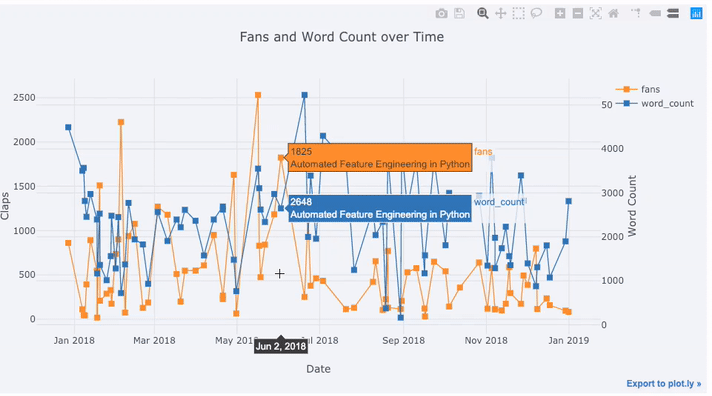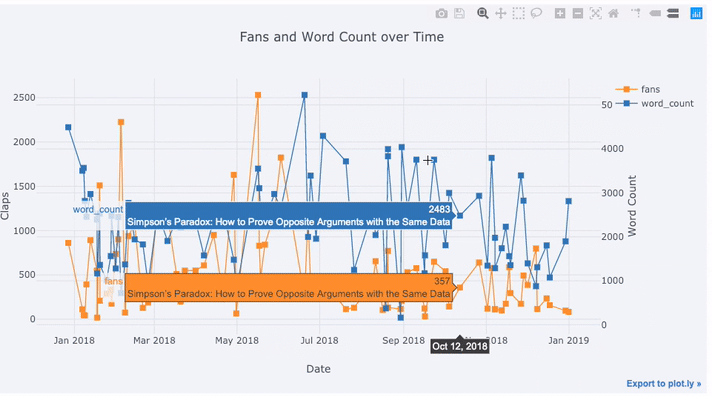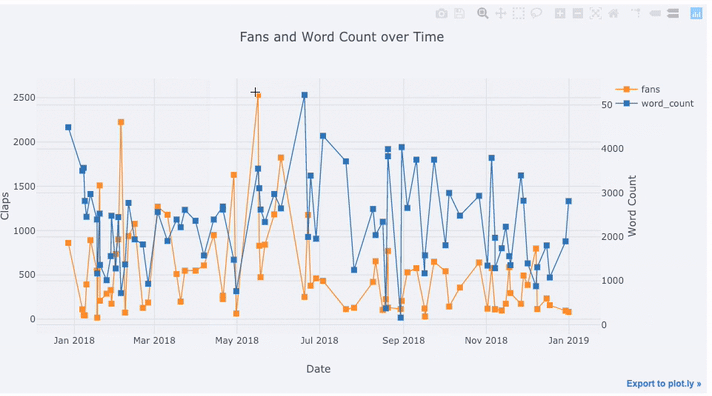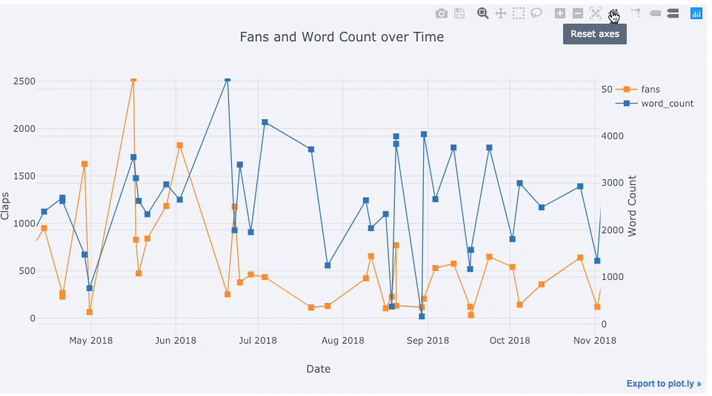
В одной строке были сделаны сразу несколько вещей:
- Задание формата оси абсцисс.
- Создание дополнительной оси ординат, так как исследуемые данные имеют разный масштаб величин (secondary_y = 'fans').
- Добавление заголовков статей к каждой точке, отображаемых при наведении курсора (рассматривается датафрейм публикации статей (text='title')).
Чтобы создать к каждой точке текстовые аннотации, используем режим lines+markers+text:
tds_monthly_totals.iplot(
mode='lines+markers+text',
text=text,
y='word_count',
opacity=0.8,
xTitle='Date',
yTitle='Word Count',
title='Total Word Count by Month')
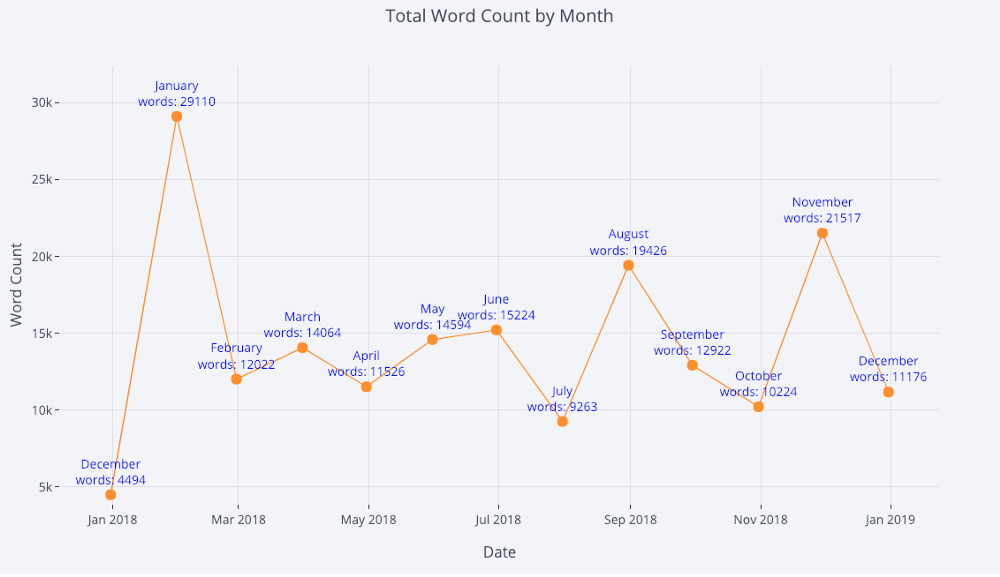
Легко сочетать и различные типы отображения. Например, использовать цвет для дополнительной переменной.
df.pivot_table(
values='views', index='published_date',
columns='publication').cumsum().iplot(
mode='markers+lines',
size=8,
symbol=[1, 2, 3, 4, 5],
layout=dict(
xaxis=dict(title='Date'),
yaxis=dict(type='log', title='Total Views'),
title='Total Views over Time by Publication'))
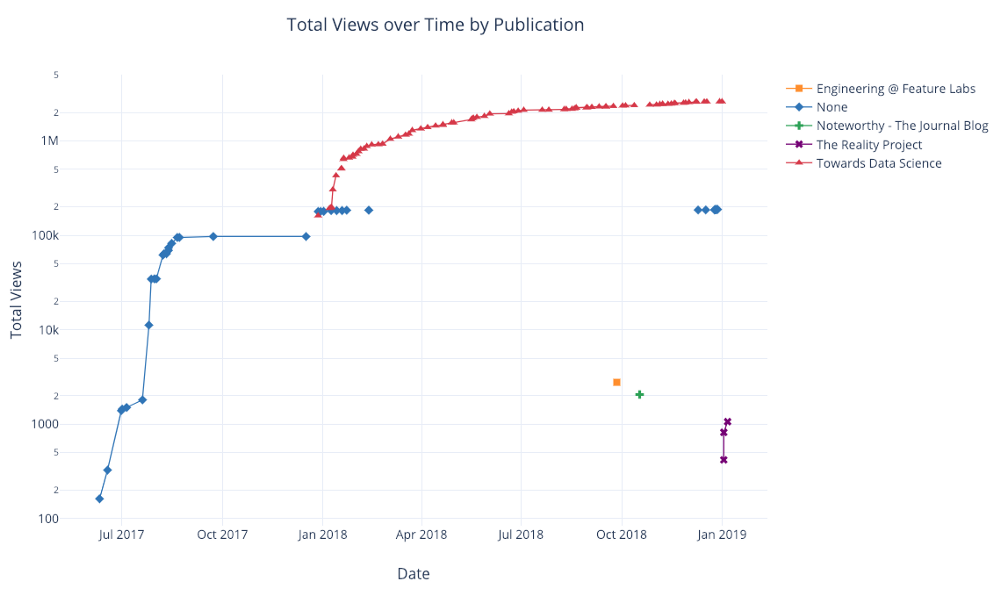
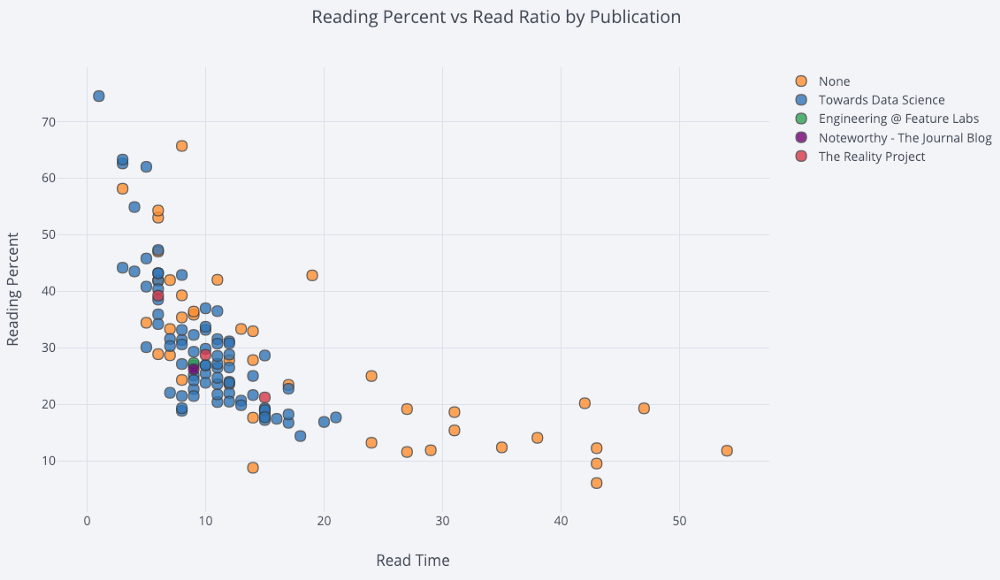
Диаграммы рассеяния
Совместим данные двух переменных (для рассматриваемого датасета это время чтения и процент прочитанного). Для третьего параметра (тематика статьи) используем цвет:
df.iplot(
x='read_time',
y='read_ratio',
# Specify the category
categories='publication',
xTitle='Read Time',
yTitle='Reading Percent',
title='Reading Percent vs Read Ratio by Publication')
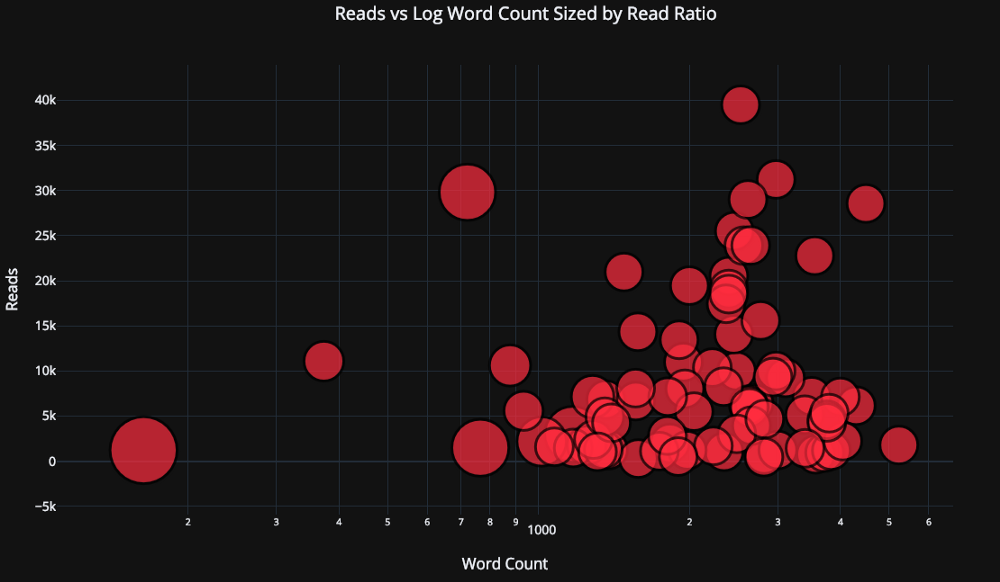
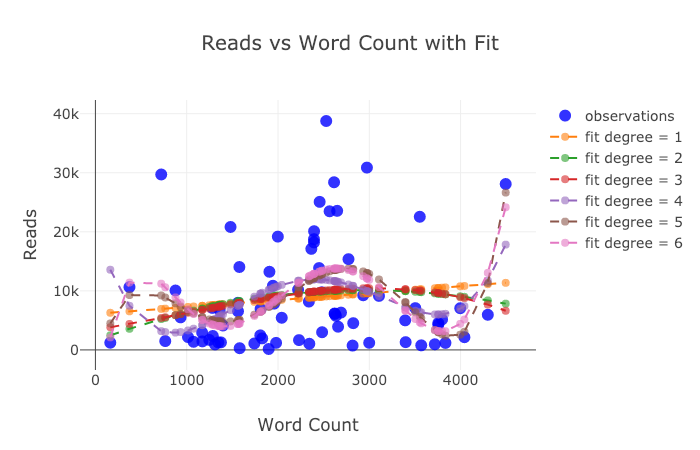
Если величина меняется в широком диапазоне логично использовать логарифмические оси. В примере ниже представлен код с логарифмической осью абсцисс (команда type='log'). Третья переменная показывается при помощи размера маркеров (size='read_ratio').
tds.iplot(
x='word_count',
y='reads',
size='read_ratio',
text=text,
mode='markers',
layout=dict(
xaxis=dict(type='log', title='Word Count'),
yaxis=dict(title='Reads'),
title='Reads vs Log Word Count Sized by Read Ratio'))
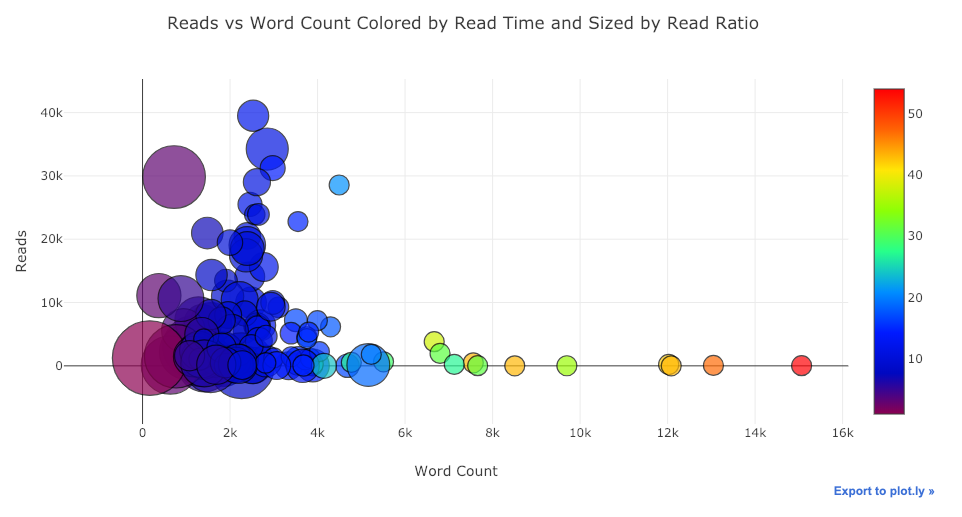
Описанные стратегии отображения дополнительной переменной можно использовать для одновременной визуализации четырех переменных: двух – при помощи координат, и еще двух – за счет использования цвета и размера. Результат представлен на рисунке ниже.
Другие формы представления
Для следующих форм представления данных будем использовать модуль plotly.figure_factory.
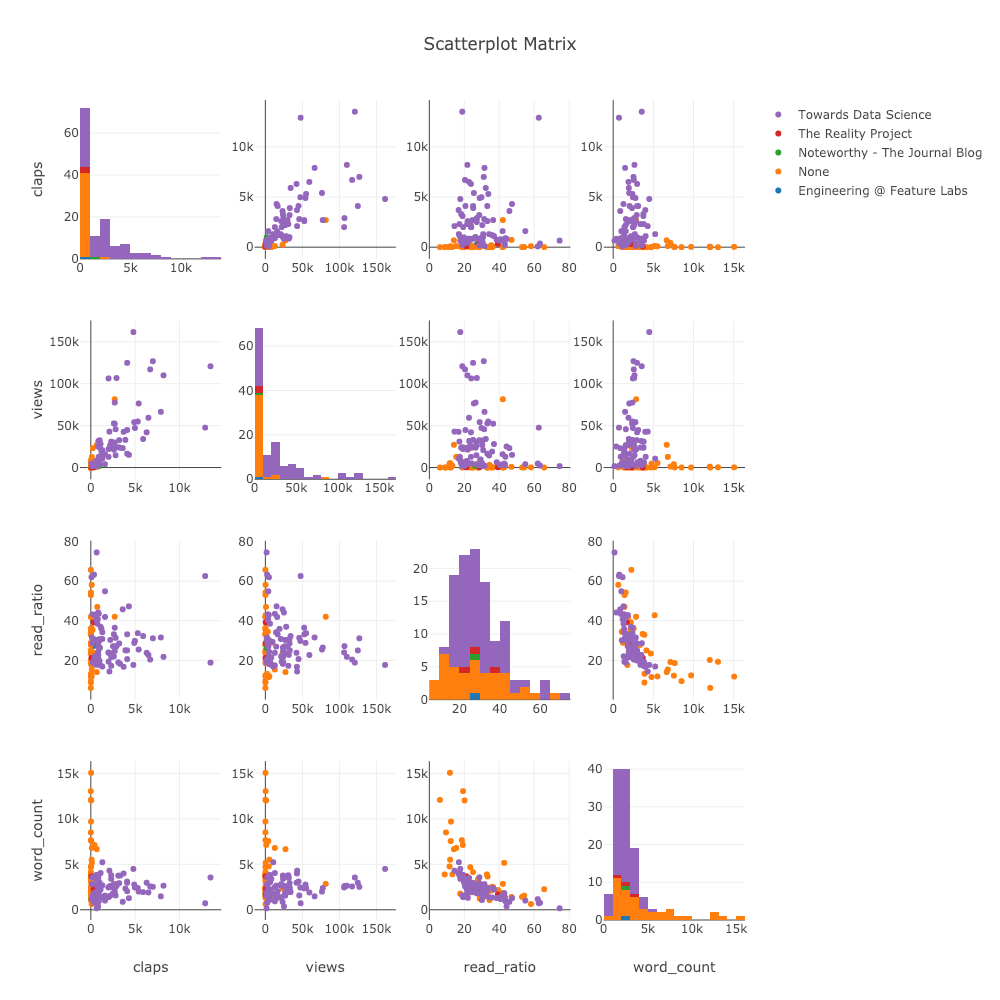
Матрица диаграмм рассеяния
Показать взаимосвязь между параметрами поможет матрица диаграмм рассеяния. В качестве диагонального отображения единственной переменной используем гистограммы (diag='histogram'). Заметим, что и здесь мы можем использовать цвет в качестве дополнительной переменной.
import plotly.figure_factory as ff
figure = ff.create_scatterplotmatrix(
df[['claps', 'publication', 'views',
'read_ratio','word_count']],
diag='histogram',
index='publication')
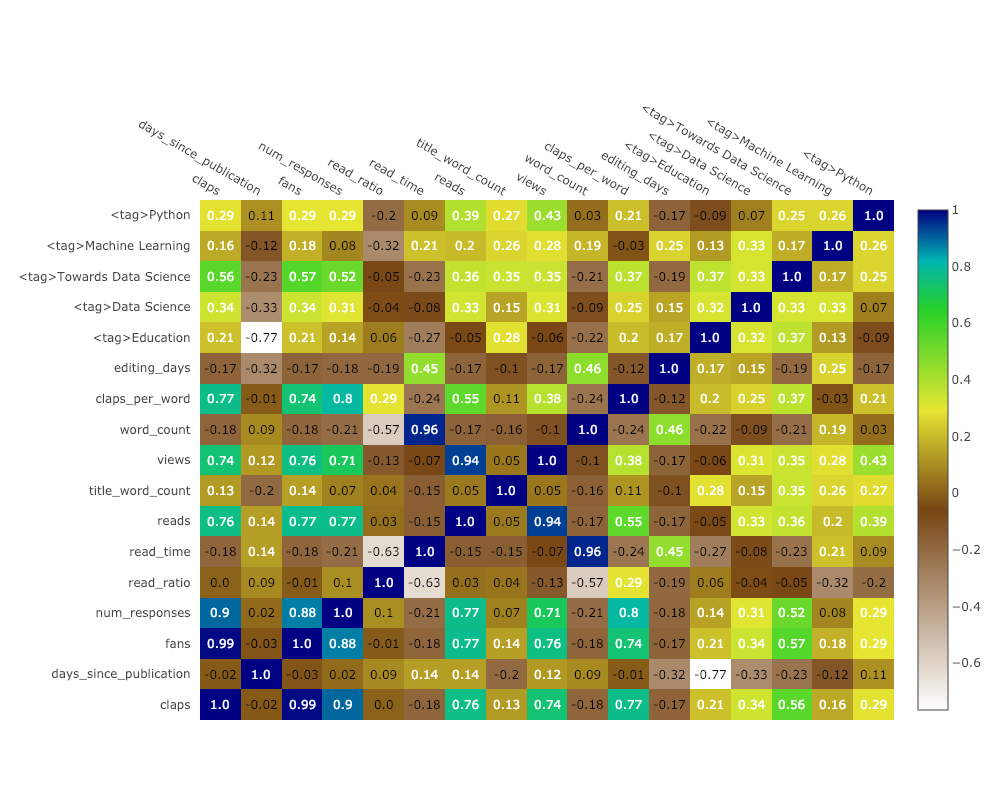
Цветовая карта распределения
Другой способ, удобный для большого количества переменных – цветовая карта распределения величины. Такой подход удобен, например, для корреляционной матрицы параметров датасета df.corr():
corrs = df.corr()
figure = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
Приятной особенностью cufflinks является возможность выбора стиля отображения данных с помощью различных тем. Ниже представлены отображения в темах space и ggplot:
Есть возможность визуализации в трехмерном пространстве:
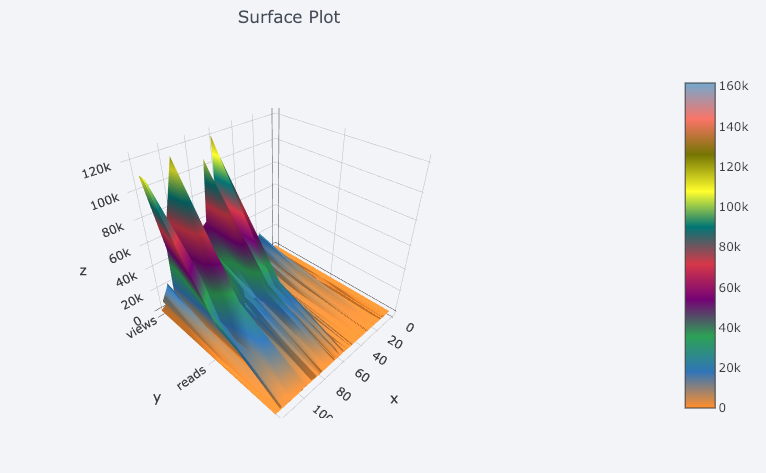
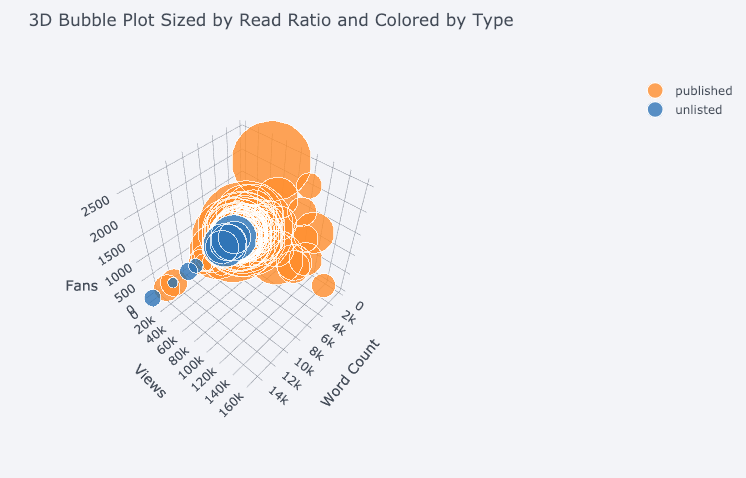
Есть и все, что привычно видеть в стандартном наборе построения диаграмм. Но даже круговые диаграммы выглядят здесь более стильно, чем в matplotlib:
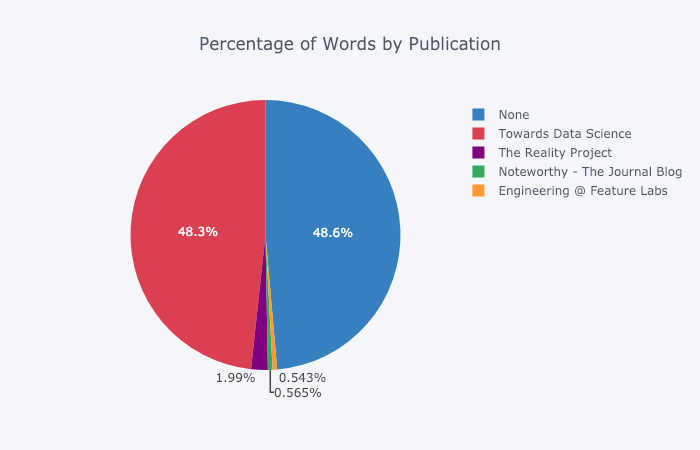
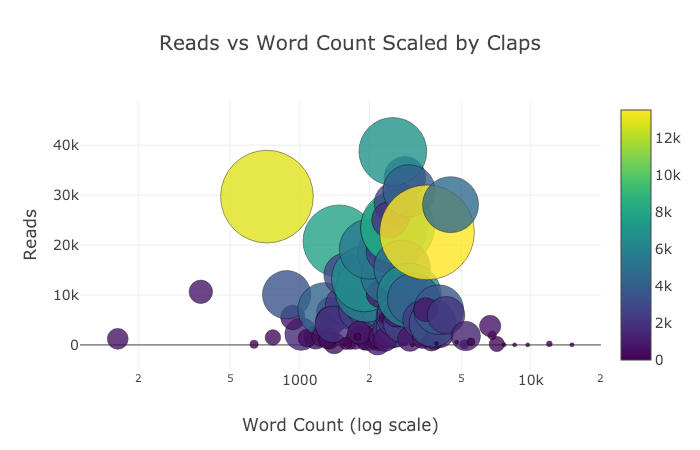
Chart Studio
Если вы запускали скрипты в Jupyter-блокноте, вы могли заметить небольшую ссылку в правой части графика Export to plot.ly. Нажав на нее, вы перенесетесь в Chart Studio, где можно дополнительно подготовить диаграмму для конечной презентации. Вы можете добавить аннотацию, изменить цвета и пр. Ниже представлены две диаграммы, подготовленные в Chart Studio.
Даже все вышепредставленное не описывает всех возможностей описываемых библиотек. Чтобы увидеть больше красочных примеров, изучите документации plotly и cufflinks.
Заключение
Итак, что мы имеем:
- Однострочный код для красочной визуализации датасетов.
- Интерактивные элементы для выделения и исследования данных.
- Возможность существенной детализации отображаемой информации.
- Простая настройка отображения для презентации с использованием преднастроенных шаблонов.
Таким образом, plotly в связке с cufflinks позволяет с минимальными усилиями быстро создавать интерактивное отображение датасетов.
Комментарии