

Перевод публикуется с сокращениями, автор оригинальной статьи Reka Horvath.
Независимо от того, знакомитесь ли вы с датасетом или готовитесь опубликовать результаты, визуализация является важным инструментом. Популярная библиотека Pandas предоставляет несколько различных вариантов визуализации с помощью функции .plot().
Настройка среды
Чтобы лучше взаимодействовать с материалом статьи, можно использовать Jupyter Notebook – вы сразу увидите свои графики и сможете поиграть с ними.
Вам также понадобится рабочая среда Python вместе с Pandas. Если она еще не установлена, есть варианты, как это исправить:
- Если у вас есть далекоидущие планы, скачайте дистрибутив Anaconda. Он весит ~500 МБ, но в него включено практически все, что не обходимо для DS.
- Если предпочитаете минимальную установку – ознакомьтесь с Minicond-ой.
- Если любите pip, то установите библиотеки, с помощью pip install pandas matplotlib и Jupyter с помощью
pip install jupyterlab. - Если же не хотите совершать лишних телодвижений, воспользуйтесь Jupyter онлайн.
В статье используются данные ресурса: Economic Guide To Picking A College Major. Как только настроите среду, загрузите набор данных, передав URL-адрес загрузки в pandas.read_csv():
In [1]: import pandas as pd
In [2]: download_url = (
...: "https://raw.githubusercontent.com/fivethirtyeight/"
...: "data/master/college-majors/recent-grads.csv"
...: )
In [3]: df = pd.read_csv(download_url)
In [4]: type(df)
Out[4]: pandas.core.frame.DataFrame
Вызывая read_csv(), вы создадите DataFrame – основную структуру данных в Pandas.
Теперь, когда есть фрейм данных, можно его изучить. Настроим параметр display.max.columns, чтобы убедиться, что Pandas не скрывает никаких столбцов. Просмотреть первые несколько строк данных можно с помощью .head():
In [5]: pd.set_option("display.max.columns", None)
In [6]: df.head()
Вывод должен выглядеть следующим образом:
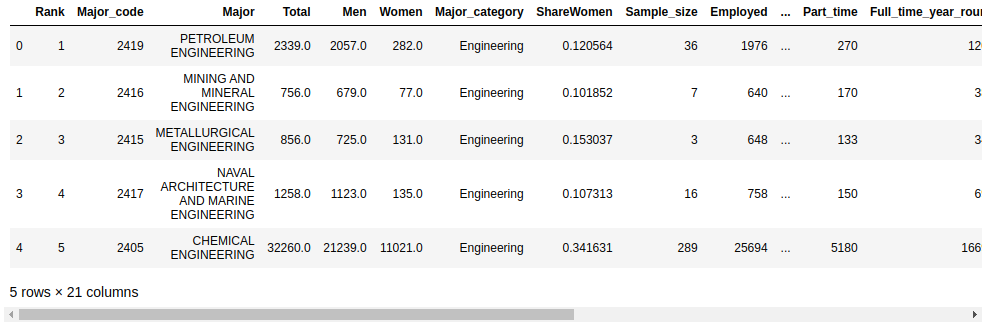
По умолчанию функция .head() отображает пять строк, но в качестве аргумента указывается любое их количество. Например, для отображения первых десяти можно использовать df.head(10).
Создание графика
Набор данных содержит несколько столбцов:
- Median – средний заработок работающих полный день круглый год.
- P25th – 25-й процентиль дохода.
- P75th – 75-й процентиль дохода.
- Rank – ранг по среднему заработку.
Начнем с отображающего эти столбцы графика. Настроим Jupyter с помощью волшебной
команды %matplotlib:
In [7]: %matplotlib
Using matplotlib backend: MacOSX
Эта команда сообщает Jupyter, что далее отображение графиков будет происходить с помощью Matplotlib.
Вы можете изменить бекенд Matplotlib путем передачи аргумента команде %matplotlib. Встроенный (inline) бекенд популярен для Jupyter Notebooks, поскольку он отображает график в самом блокноте, непосредственно под ячейкой, которая его создает:
In [7]: %matplotlib inline
Ознакомиться с другими доступными вариантами бекендов можно на странице IPython.
Теперь создадим график:
In [8]: df.plot(x="Rank", y=["P25th", "Median", "P75th"])
Out[8]: <AxesSubplot:xlabel='Rank'>
.plot() возвращает
линейный график, содержащий данные из каждой строки в DataFrame. По оси X выводится
рейтинг учреждений, а значения отображаются на оси Y.
Если вы не используете Jupyter Notebook или оболочку IPython, возьмите интерфейс pyplot из matplotlib для отображения графика.
Вот как должно получиться в стандартной оболочке Python (для вызова plt.show() импортируйте модуль pyplot из Matplotlib):
>>> import matplotlib.pyplot as plt
>>> df.plot(x="Rank", y=["P25th", "Median", "P75th"])
>>> plt.show()
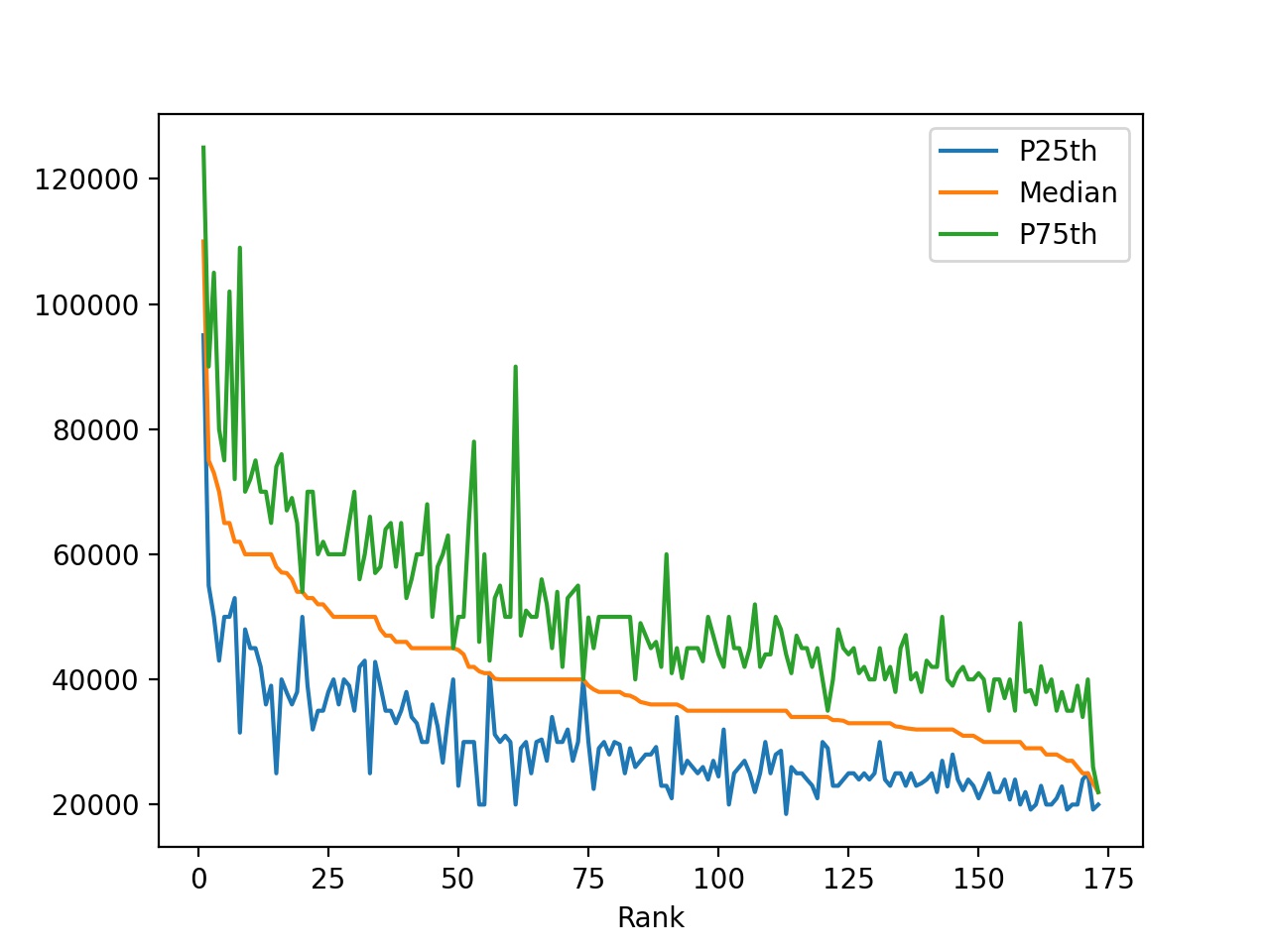
Глядя на график, можно сделать следующие наблюдения:
- Средний доход уменьшается с уменьшением рейтинга. Это ожидаемо, потому что он определяется медианным доходом.
- Некоторые специальности имеют большие промежутки между 25-м и 75-м процентилями. Люди с такими степенями могут зарабатывать значительно меньше или значительно больше, чем средний доход.
- Другие специальности имеют очень небольшие промежутки между 25-м и 75-м процентилями. Люди с такими степенями получают зарплату, очень близкую к среднему доходу.
Некоторые специальности имеют широкий диапазон заработка, а другие – довольно узкий. Чтобы обнаружить и визуализировать эти различия, будем использовать другие типы графиков.
.plot() имеет несколько необязательных параметров, определяющих, какой тип графика создается:
- «area» – графики области;
- «bar» – вертикальные графики;
- «barh» – горизонтальные графики;
- «box» – квадратный график;
- «hexbin» – hexbin участки;
- «hist» – гистограммы;
- «kde» – оценка плотности ядра;
- «density» – псевдоним для «kde»;
- «line» – линейные графики;
- «pie» – круговые диаграммы;
- «scatter» – точечные диаграммы.
Значение по умолчанию – «line». Линейные графики обеспечивают хороший обзор ваших данных. Если не задать параметр для функции .plot(), она создаст линейный график с индексом по оси X и всеми числовыми столбцами по оси Y. Хотя это полезное значение по умолчанию для наборов данных с несколькими столбцами, для нашего датасета и его нескольких числовых столбцов оно выглядит небрежно.
В качестве альтернативы передаче строк параметру kind функции .plot(), объекты DataFrame имеют несколько методов, которые можно использовать для создания различных типов графиков:
По возможности попробуйте эти методы в действии.
Теперь, когда мы создали график, рассмотрим подробнее работу функции .plot().
Что под капотом: Matplotlib
Когда вы вызываете функцию .plot() для объекта DataFrame, Matplotlib создает график.
Чтобы убедиться в этом, воспользуемся двумя фрагментами кода. Создайте график с помощью Matplotlib, используя два столбца DataFrame:
In [9]: import matplotlib.pyplot as plt
In [10]: plt.plot(df["Rank"], df["P75th"])
Out[10]: [<matplotlib.lines.Line2D at 0x7f859928fbb0>]
Сначала импортируется модуль matplotlib.pyplot и переименовывается в plt. Затем вызывается plot() и передается объект «Rank» в качестве первого аргумента, и «P75th» в качестве второго.
В результате получается линейный график, который строит 75-й процентиль по оси Y и рейтинг по оси X:
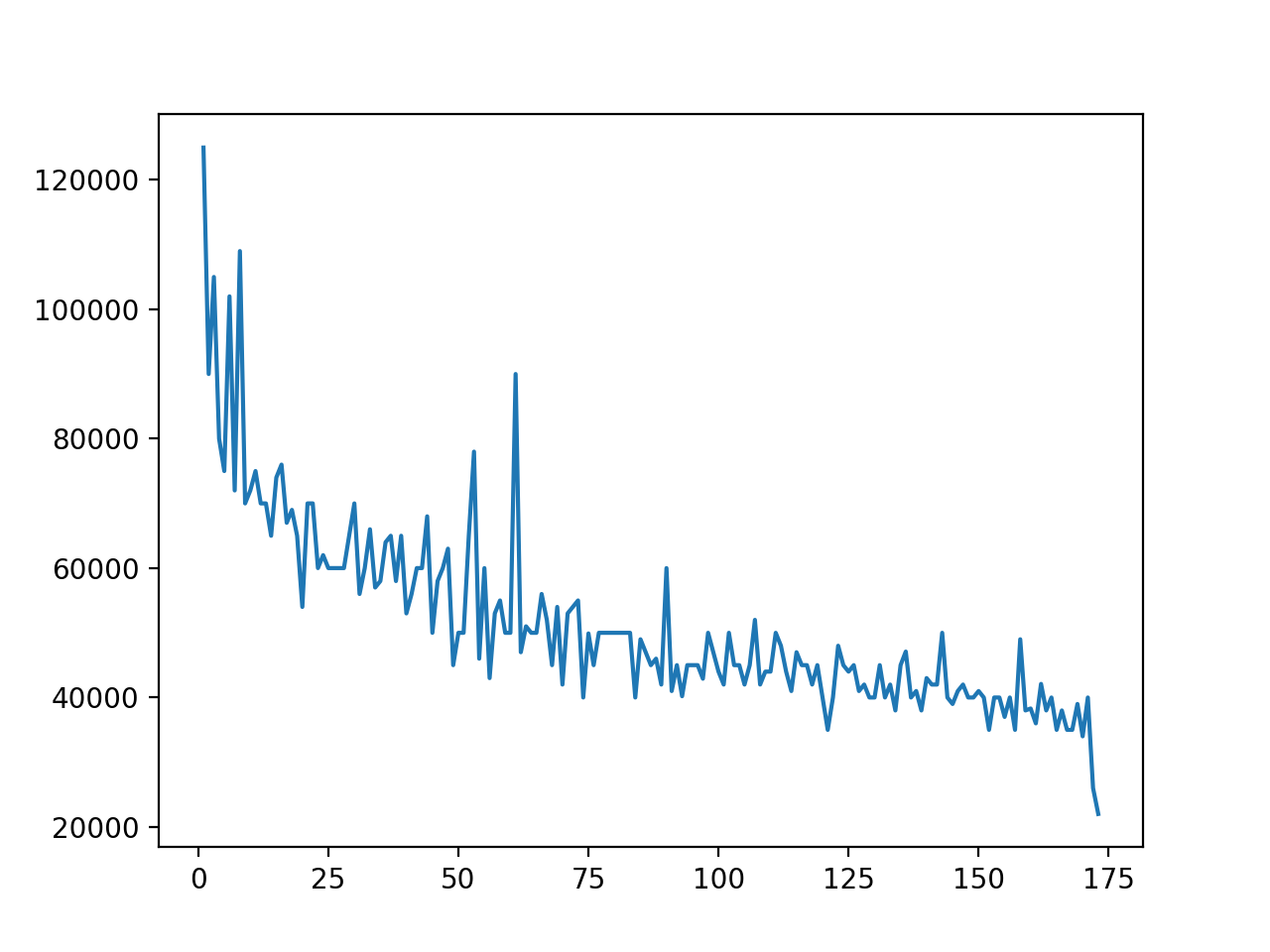
Вы можете создать такой же график, используя метод DataFrame:
In [11]: df.plot(x="Rank", y="P75th")
Out[11]: <AxesSubplot:xlabel='Rank'>
.plot() – это оболочка
для pyplot.plot(). На выходе получается график, идентичный тому, который мы
создали на Matplotlib:
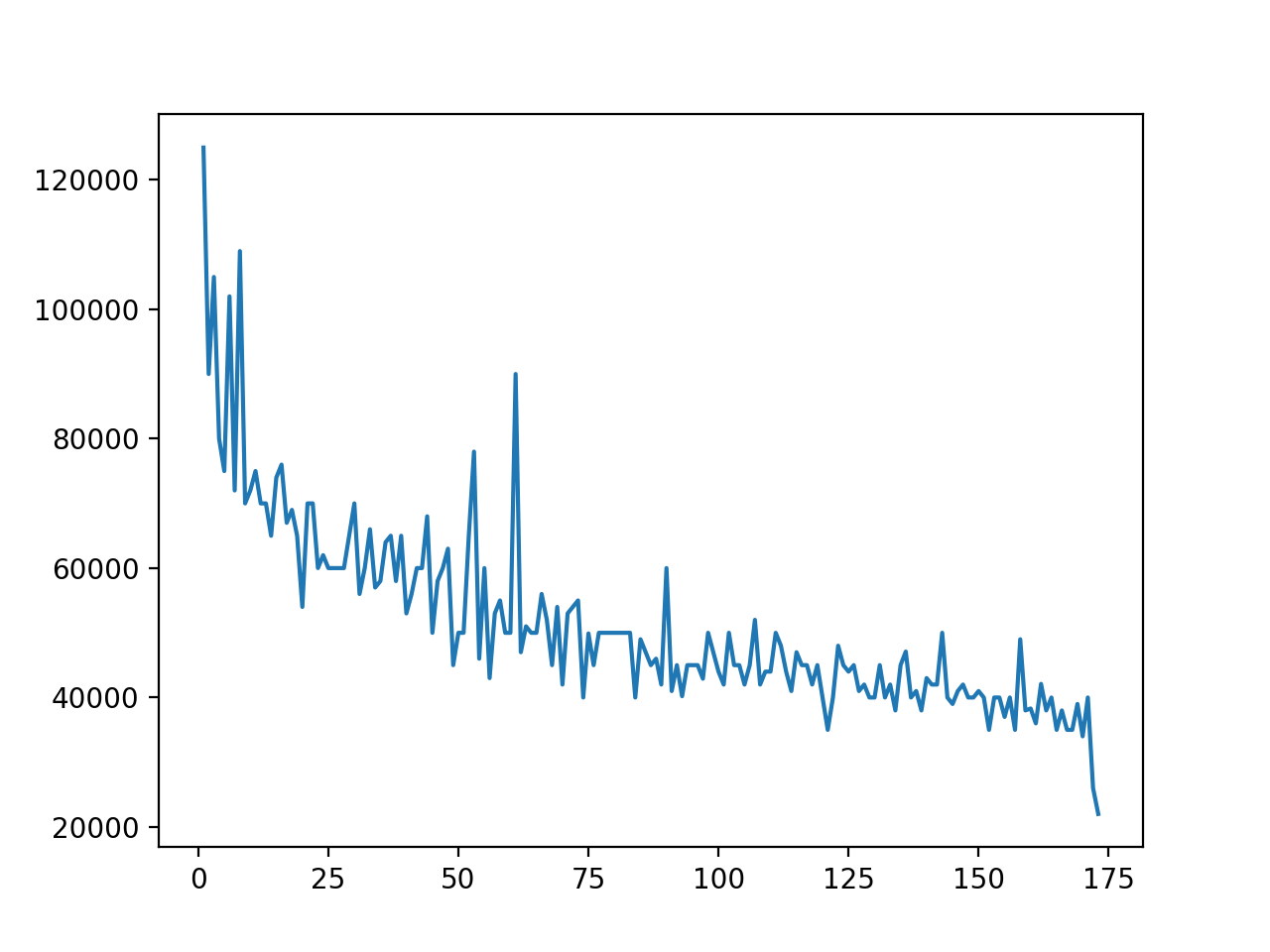
Вы можете использовать как pyplot.plot(), так и df.plot() для создания одного и того же графика. Однако если у вас уже есть экземпляр DataFrame, то df.plot() предлагает более чистый синтаксис.
Теперь приступим к изучению различных типов графиков и способов их создания.
Изучение данных
Следующие графики дадут общий обзор конкретного столбца набора данных. Вы рассмотрите распределение свойств на гистограмме и познакомитесь с инструментами для изучения исключений.
Распределения и гистограммы
DataFrame – не единственный класс в pandas с методом .plot(). Объект Series предоставляет аналогичную функциональность. Вы можете получить каждый столбец DataFrame как объект Series. Вот пример использования столбца «Median»:
In [12]: median_column = df["Median"]
In [13]: type(median_column)
Out[13]: pandas.core.series.Series
Гистограммы – это хороший способ визуализации распределения значений по набору данных. Они группируют значения в ячейки и отображают количество точек данных, значения которых находятся в определенной ячейке.
Создадим гистограмму для столбца «Median»:
In [14]: median_column.plot(kind="hist")
Out[14]: <AxesSubplot:ylabel='Frequency'>
Вызывается функция .plot() в median_column и передается строк в «hist» параметру kind. На выходе должно получиться следующее:
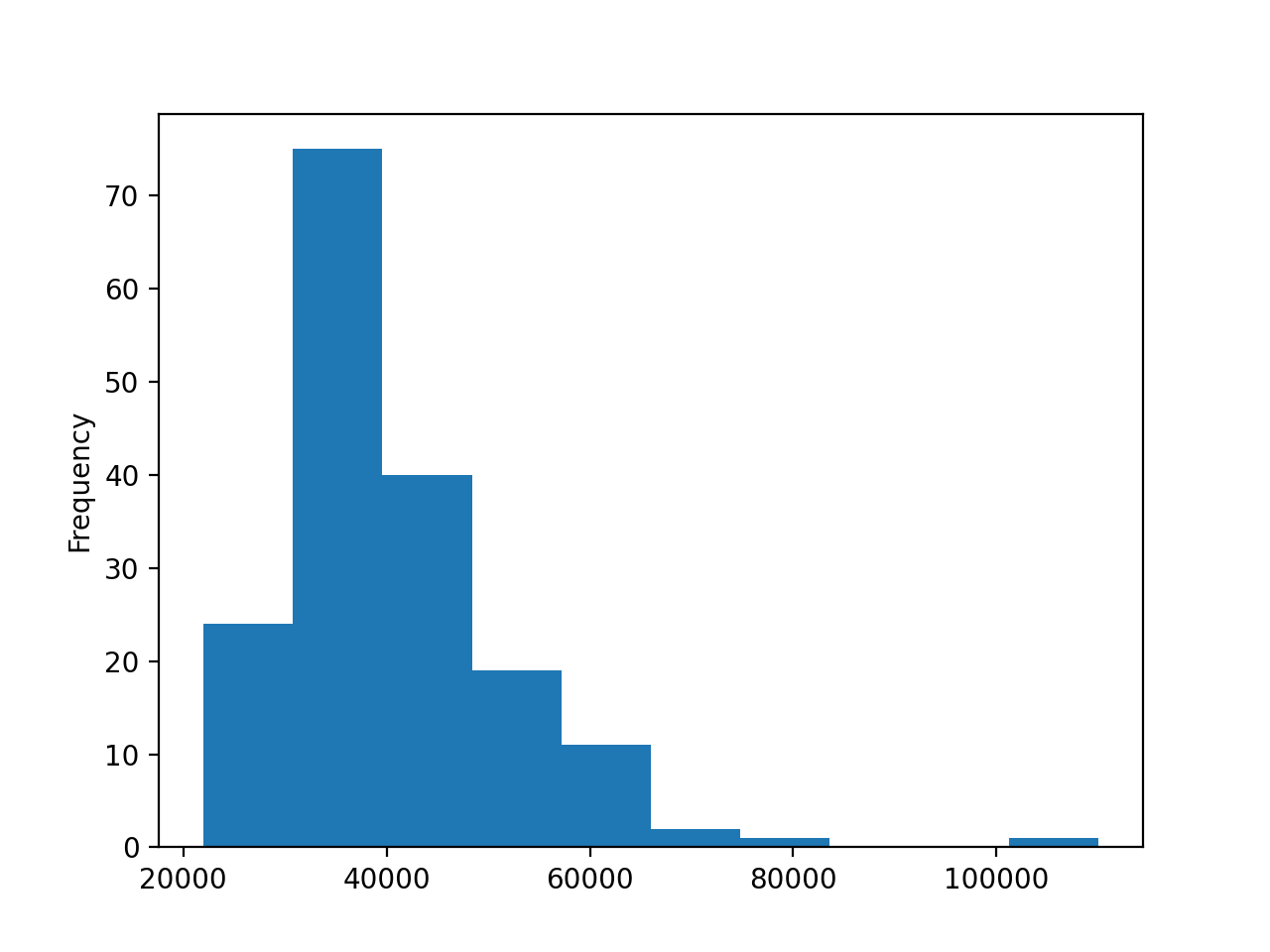
Гистограмма показывает данные, сгруппированные в десять ячеек в диапазоне от $20 000 до $120 000 с шагом в $10 000.
Исключения
В правой части графика виднеется маленькая ячейка – специалисты в этой области получают большую зарплату по сравнению со всеми категориями. Хотя это не основная цель, гистограмма может помочь обнаружить такие исключения. Исследуем эту штуку подробнее:
- какие специальности представляет это исключение?
- где его граница?
В отличие от первого графика, мы хотим сравнить несколько точек данных и увидеть более подробную информацию о них. Для этого вертикальный график является отличным инструментом. Выберем пять специальностей с самым высоким средним доходом. Необходимо выполнить два шага:
- Для сортировки по столбцу «Median» используйте функцию .sort_values() и укажите имя столбца, а также направление ascending=False.
- Чтобы получить первые пять пунктов списка, используйте функцию .head().
Создадим новый DataFrame top_5:
In [15]: top_5 = df.sort_values(by="Median", ascending=False).head()
Создадим гистограмму, показывающую основные специальности, учитывая ТОП-5 зарплат:
In [16]: top_5.plot(x="Major", y="Median", kind="bar", rot=5, fontsize=4)
Out[16]: <AxesSubplot:xlabel='Major'>
Мы используем параметры rot и fontsize для поворота и изменения размера меток оси X, чтобы они были видны:
Этот график показывает, что средняя зарплата специалистов нефтегазового направления более чем на $20 000 выше остальных. Заработки занявших 2-4 места специальностей относительно близки друг к другу.
Если у вас есть точки данных с гораздо более высокими/низкими значениями, чем остальные, необходимо этот момент исследовать: можно просмотреть столбцы, содержащие связанные данные.
Рассмотрим все
специальности, средняя зарплата которых превышает $60 000. Отфильтруем их по
маске df[df["Median"]
> 60000] и создадим график с тремя столбцами:
In [17]: top_medians = df[df["Median"] > 60000].sort_values("Median")
In [18]: top_medians.plot(x="Major", y=["P25th", "Median", "P75th"], kind="bar")
Out[18]: <AxesSubplot:xlabel='Major'>
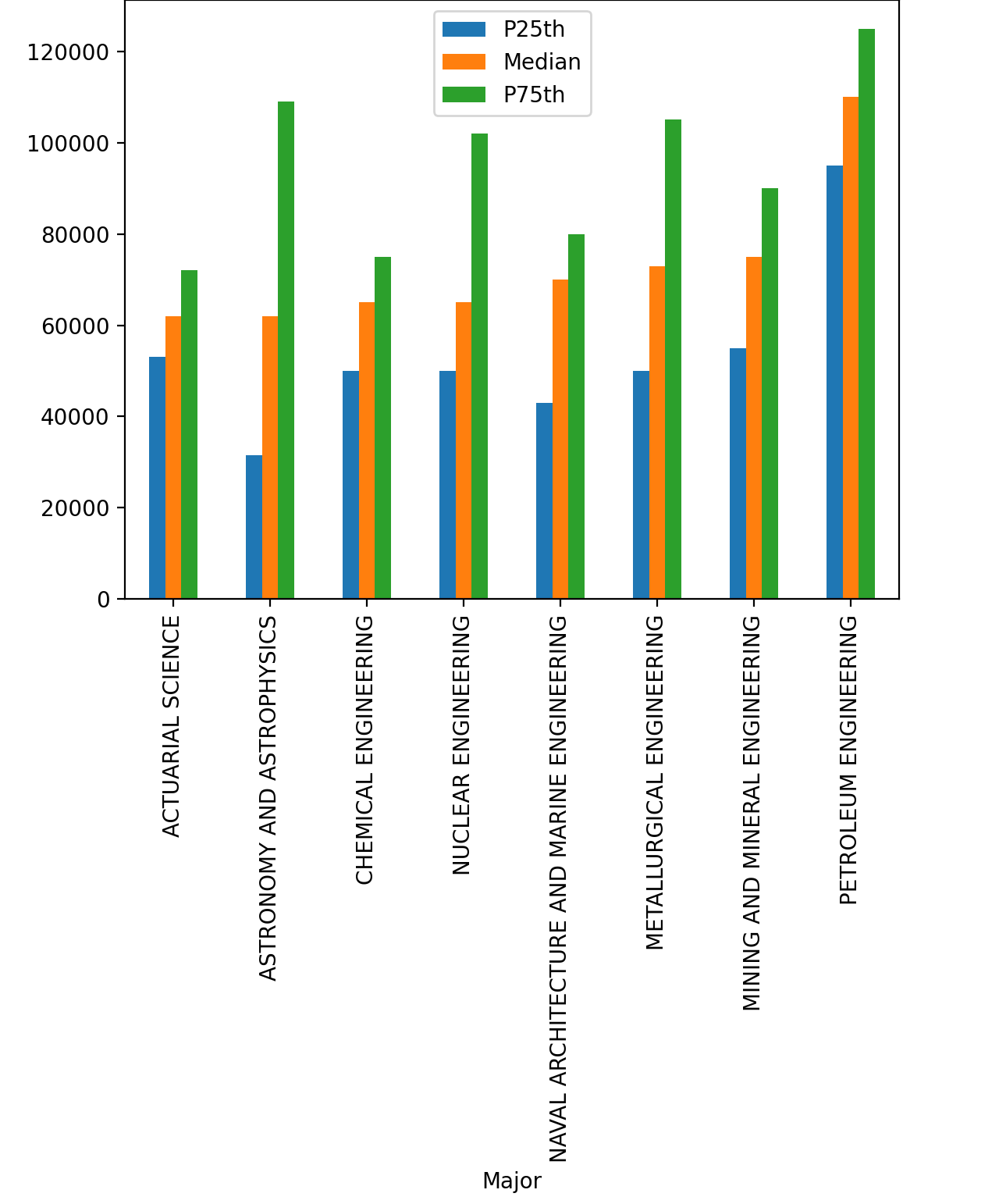
25-й и 75-й процентили подтверждают, что нефтяники самые высокооплачиваемые работники.
Почему исключения так важны? Если вы студент – все очевидно, но исключения интересны с точки зрения анализа. Неверные данные могут быть вызваны ошибками или погрешностями.
Корреляция
Часто требуется проверить, связаны ли столбцы набора данных. Например, связан ли высокий оклад с вероятностью не получить работу. В качестве первого шага создайте точечную диаграмму с этими столбцами:
In [19]: df.plot(x="Median", y="Unemployment_rate", kind="scatter")
Out[19]: <AxesSubplot:xlabel='Median', ylabel='Unemployment_rate'>
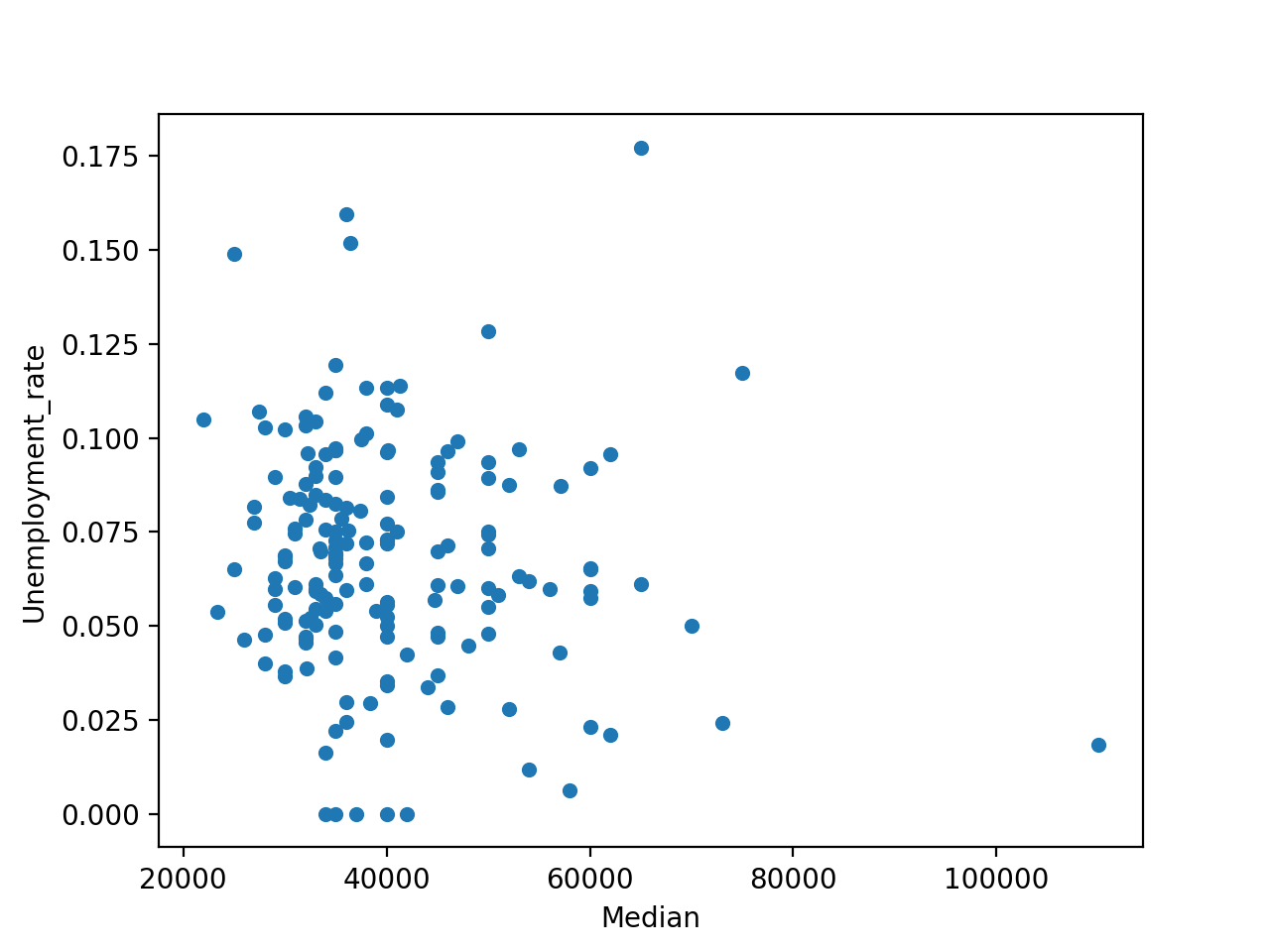
Можно заметить, что существенной корреляции между доходами и уровнем безработицы нет.
Хотя точечная диаграмма
является отличным инструментом для получения первого впечатления о возможной
корреляции, она не является окончательным доказательством связи – для этого
подойдет функция .corr().
Однако имейте в виду, что даже если существует корреляция между двумя значениями, не факт, что изменение одного приведет к изменению другого.
Анализ категориальных данных
Чтобы обрабатывать большие куски информации, удобно сортировать ее по категориям. Здесь мы познакомимся с инструментами для оценки категорий и проверки ее валидности.
Многие наборы данных уже содержат явную или неявную категоризацию – в нашем примере 173 специальности разделены на 16 категорий.
Группировка
Основное использование
категорий – группирование и агрегирование. Можно использовать функцию .groupby()
для определения популярности каждой из категорий в основном датасете:
In [20]: cat_totals = df.groupby("Major_category")["Total"].sum().sort_values()
In [21]: cat_totals
Out[21]:
Major_category
Interdisciplinary 12296.0
Agriculture & Natural Resources 75620.0
Law & Public Policy 179107.0
Physical Sciences 185479.0
Industrial Arts & Consumer Services 229792.0
Computers & Mathematics 299008.0
Arts 357130.0
Communications & Journalism 392601.0
Biology & Life Science 453862.0
Health 463230.0
Psychology & Social Work 481007.0
Social Science 529966.0
Engineering 537583.0
Education 559129.0
Humanities & Liberal Arts 713468.0
Business 1302376.0
Name: Total, dtype: float64
С помощью функции .groupby() создадим объект DataFrameGroupBy. С помощью .sum() получим Series.
Нарисуем горизонтальную диаграмму со значениями cat_totals:
In [22]: cat_totals.plot(kind="barh", fontsize=4)
Out[22]: <AxesSubplot:ylabel='Major_category'>
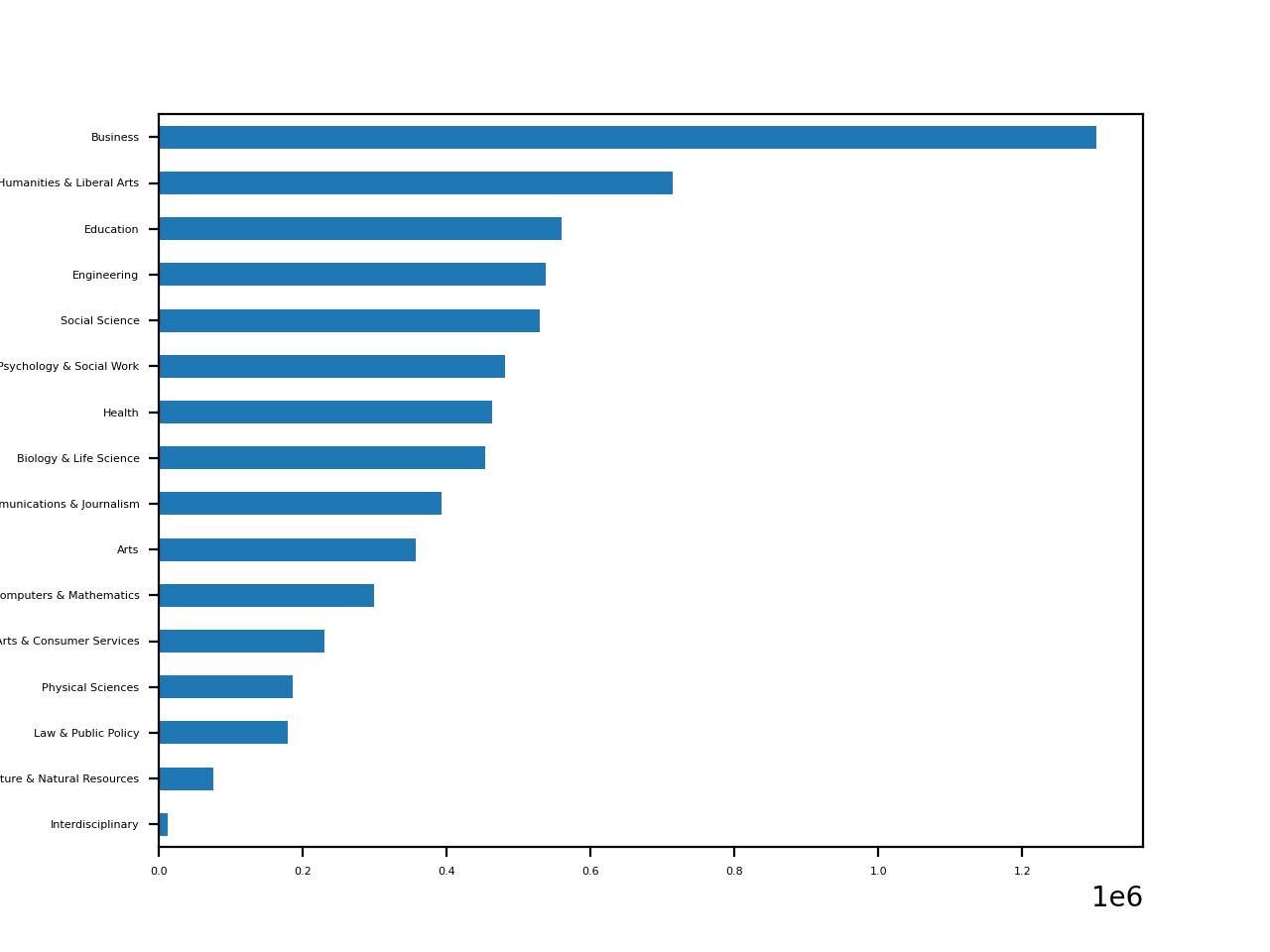
Определение коэффициентов
Если необходимо
визуализировать соотношения, пригодятся круговые графики. Поскольку cat_totals
содержит несколько маленьких категорий, создание кругового графика с помощью
cat_totals.plot(kind="pie") приведет к появлению крошечных фрагментов
с перекрывающимися метками.
Чтобы решить проблему, следует объединить более мелкие категории в одну группу. Например, категории с общим числом менее 100 000 в категорию «Другое». Теперь создадим круговую диаграмму:
In [23]: small_cat_totals = cat_totals[cat_totals < 100_000]
In [24]: big_cat_totals = cat_totals[cat_totals > 100_000]
In [25]: # Adding a new item "Other" with the sum of the small categories
In [26]: small_sums = pd.Series([small_cat_totals.sum()], index=["Other"])
In [27]: big_cat_totals = big_cat_totals.append(small_sums)
In [28]: big_cat_totals.plot(kind="pie", label="")
Out[28]: <AxesSubplot:>
Обратите внимание, что мы использовали label="". По умолчанию Pandas добавляет метку с именем столбца. Это часто имеет смысл, но в данном случае будет только отвлекать. На выходе получим следующий результат:
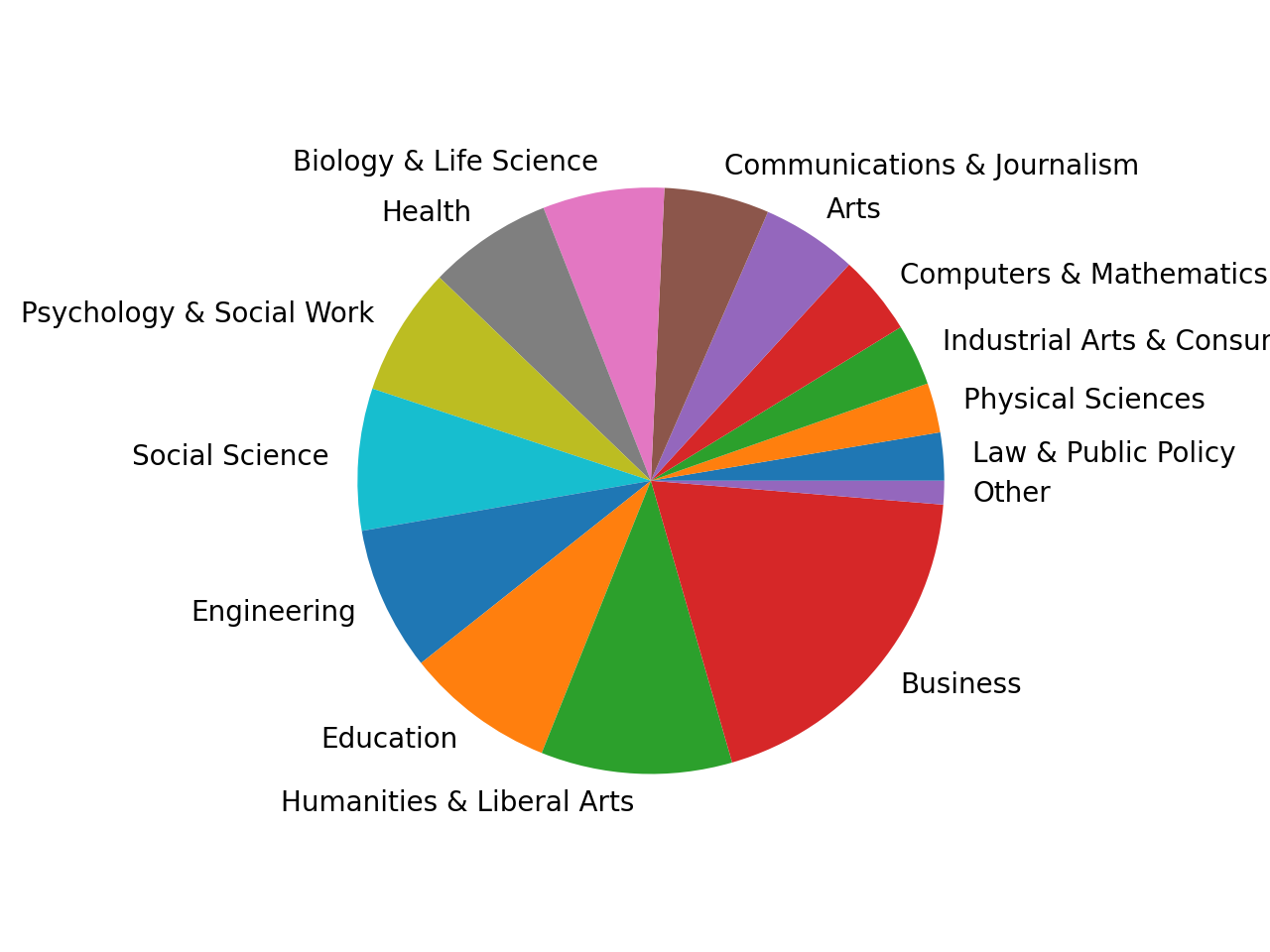
Заключение
Этот материал направлен на изучение процесса визуализации набора данных с помощью Python и библиотеки Pandas.
Из него вы узнали, как сделать множество вещей:
- получить распределение вашего набора данных с помощью гистограммы;
- произвести корреляцию с точечной диаграммой;
- анализировать категории с гистограммами и их соотношениями с круговыми диаграммами;
- определить, какой график больше подходит для текущей задачи;
- используя функцию .plot() и небольшой DataFrame, эффективно управлять визуализацией ваших данных.
Используя эти знания, вы можете открывать для себя еще более интересные визуализации. Удачи!
На Python создают прикладные приложения, пишут тесты и бэкенд веб-приложений, автоматизируют задачи в системном администрировании, его используют в нейронных сетях и анализе больших данных. Язык можно изучить самостоятельно, но на это придется потратить немало времени. Если вы хотите быстро понять основы программирования на Python, обратите внимание на онлайн-курс «Библиотеки программиста». За 30 уроков (15 теоретических и 15 практических занятий) под руководством практикующих экспертов вы не только изучите основы синтаксиса, но и освоите две интегрированные среды разработки (PyCharm и Jupyter Notebook), работу со словарями, парсинг веб-страниц, создание ботов для Telegram и Instagram, тестирование кода и даже анализ данных. Чтобы процесс обучения стал более интересным и комфортным, студенты получат от нас обратную связь. Кураторы и преподаватели курса ответят на все вопросы по теме лекций и практических занятий.
Комментарии