

OpenAI продолжает наводить суету. Количество пользователей ChatGPT перевалило за 100 миллионов, но хайп даже и не думает стихать – кажется, даже бабушки у подъезда шлют ИИ свои вопросы про повышение пенсии. Но сегодня пойдет речь не о правильных вопросах, а о том, как можно использовать модели OpenAI для задачи дедубликации.
Дедубликация (Deduplication), similarity search являются востребованными доменами машинного обучения. В команде новостного мониторинга Сбера я решал эти задачи для потока новостей. Сейчас я работаю в команде Data Science Самолета (это такой застройщик здорового человека) и оказалось, что здесь точек приложения для NLP даже больше чем в банке, в том числе и для мэтчинга.
В этой статье я постараюсь рассказать о подходах к дедубликации текстов, как в этом помогают модели OpenAI, а также приведу пример боевого микросервиса на FastAPI, который будет находить не очень свежие по содержанию посты на Хабре. Мне импонирует исторический подход, поэтому я сначала расскажу про темное прошлое, и постепенно доберемся до золотого века современных языковых моделей.
Старое, доброе, вечное
Давайте сначала разберемся, как вообще можно оценить, что два текста являются похожими. Ну, самое очевидное – посмотреть на общие слова, чем их больше, тем ближе два текста. Собственно эту идею использует мера Жаккара.
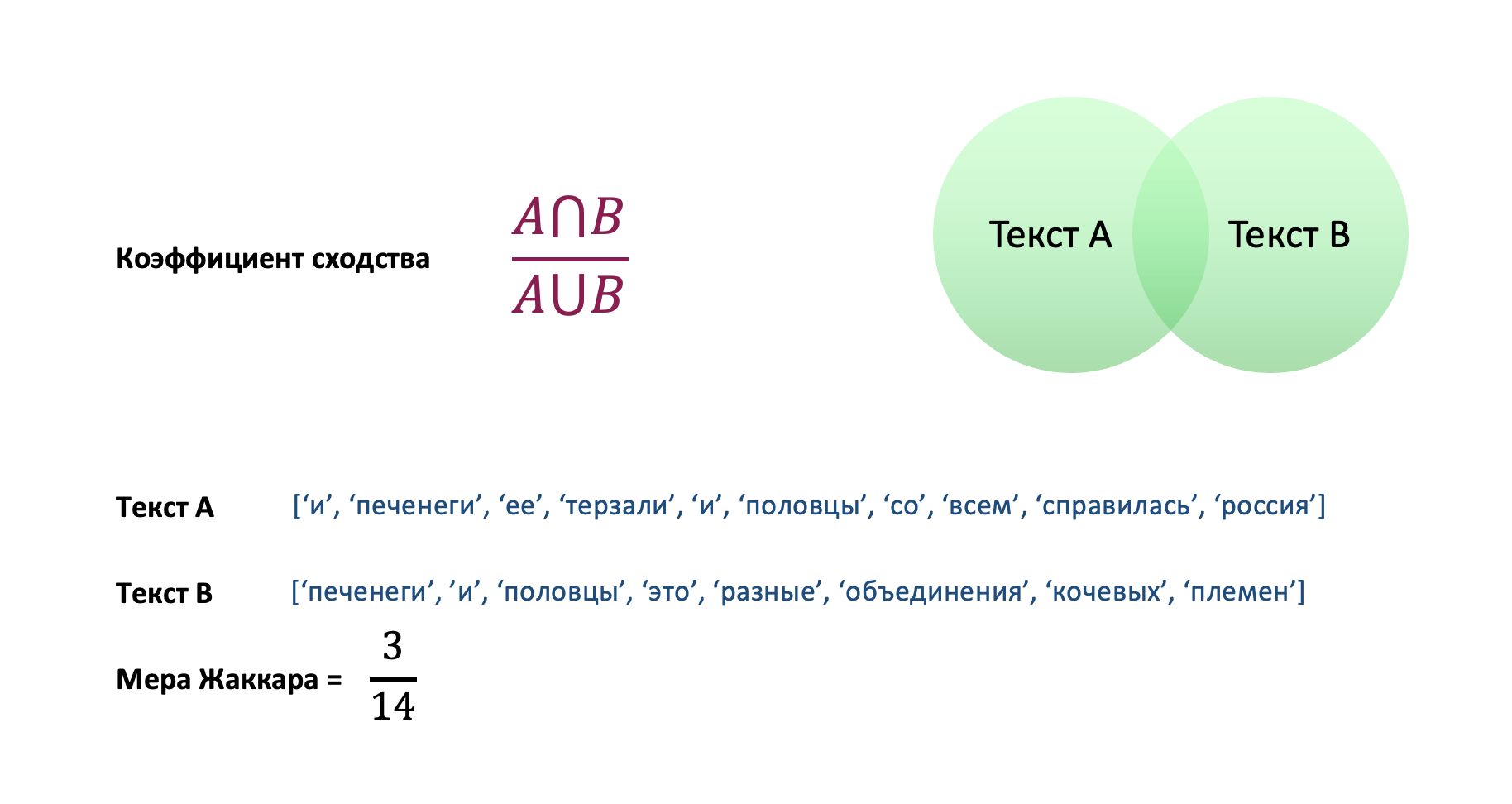
Однако в таком подходе есть свои минусы. Во-первых, он не оптимален с вычислительной точки зрения. Если у вас большой корпус документов, а документы состоят из тысяч слов, то квадратичная сложность может похоронить ваши ресурсы. Во-вторых, отсутствие общих слов еще не означает смыслового отличия.
doc А = 'Цена нефти бренд выросла из-за опасений возможности столкновения между США и Ираном'
doc B = 'Стоимость североморской нефти растет на ожидании обострения конфликта Пентагона и Ирана’
В данном случае мера Жаккара будет около 0.1
Обойти первую проблему поможет связка minhash + lsh. Minhash-подход заключается в случайной перестановке слов (на самом деле кусочков слов – шинглов) и хешировании. То есть текст любой длины превращается в набор таких хешей (сигнатура): было 10 тыс. слов, а легким движением руки хеш-функции все превратится в сигнатуру длины 200. Ну а дальше вы уже сравниваете такие сигнатуры. Это пока не избавляет от квадратичной сложности, но зато поможет быстрее просчитывать близость. А вот LSH (local sensitive hashing) как раз позволит искать дубли не по всему корпусу, а по ограниченному подмножеству. В питоне есть уже готовая реализация этого метода в виде библиотеки datasketch. Что касается второй проблемы, то… придется читать дальше.
Расскажи мне про эмбеддинги
Эмбеддинг является краеугольным камнем всего NLP, да, прямо как четвертьфунтовый чизбургер в питании. Эмбеддинг – это векторное представление какой-то сущности: слова, предложения, абзаца и даже всего текста. На самом деле векторизовать можно все что угодно. Сигнатура документа из текста выше тоже, по сути, является вектором, но эмбеддингом лучше это не называть, т. к. эмбеддинг это «хороший» вектор, для которого операции (сумма, разность, скалярное произведение) являются осмысленными. Картинка ниже уже набила оскомину, но она хорошо иллюстрирует операции над эмбеддингами. Картинка иллюстрирует классический word2vec из далекого 2013 года.
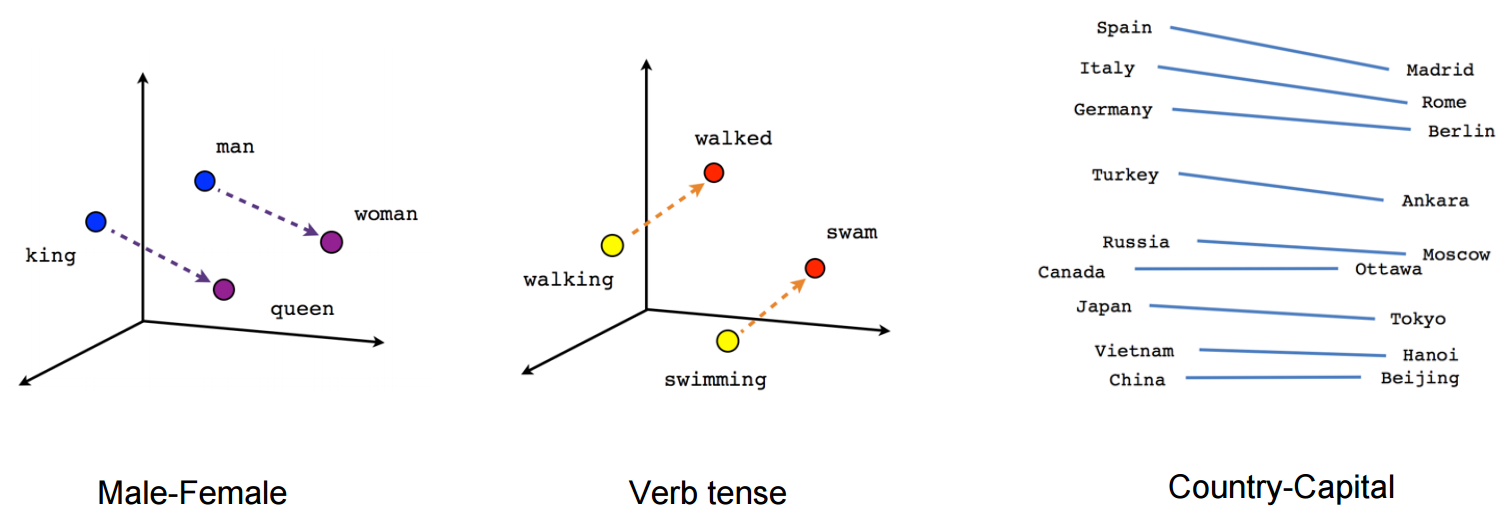
Текущие векторные представления уже настолько круты, что, например, можно из вектора футболки с короткими рукавами вычесть вектор короткого рукава, потом прибавить вектор длинного рукава и наконец – получить картинку футболки с длинными рукавами.
В word2vec вы получаете вектора для отдельных слов, и они фиксированные. В предложениях «Ключ для замка» и «Эти мерзавцы лишили меня родового замка», слово «замок» будет иметь одно и то же векторное представление.
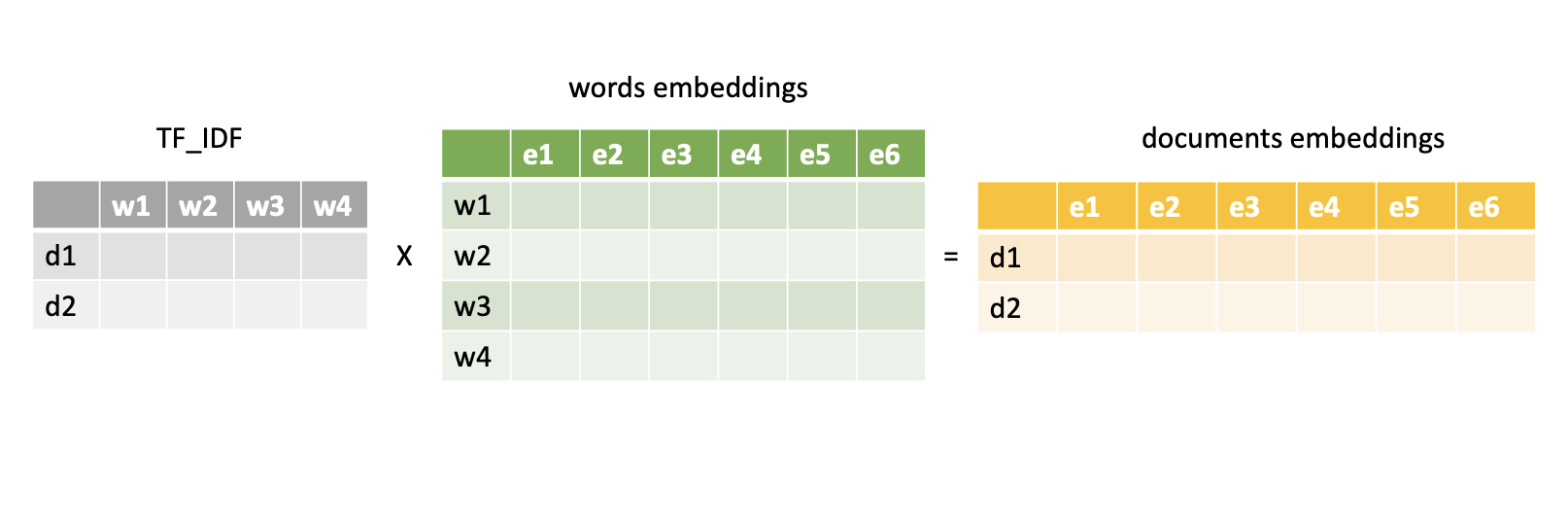
Для сравнения текстов из сотен и тысяч слов вам придется придумать способ объединения векторов в один. Можно, конечно, просто усреднить, но так можно потерять очень много информации. Другой подход – это складывать отдельные вектора с весами, а веса взять из матрицы TF-IDF.
Когда у вас есть вектора для документов, то найти их похожесть можно с помощью косинусной близости. Когда в 8 классе вы решали примеры на скалярное произведение, то как раз и высчитывали эту метрику. Чем она меньше, тем больше похожесть.
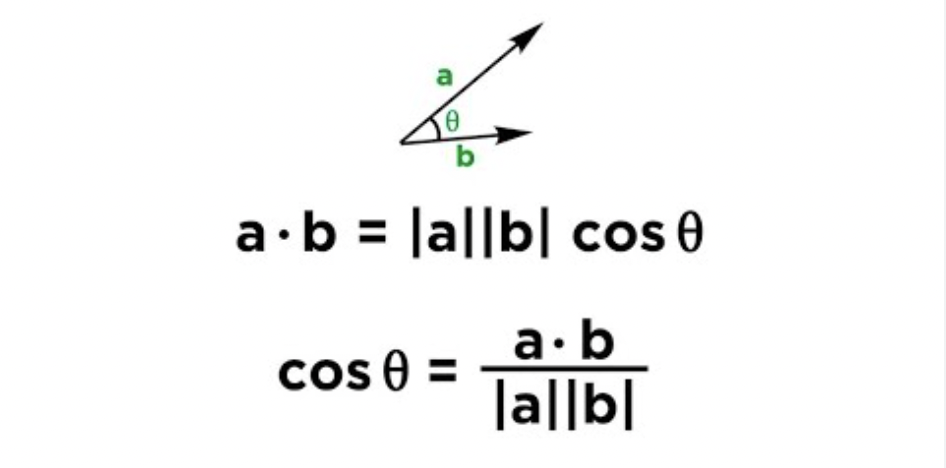
Мощь трансформеров
Вектора word2vec или их более современные аналоги типа fasttext страдают отсутствием контекстуальности. Также эти эмбеддинги существуют только на уровне отдельных слов (токенов), а нам нужен эмбединг всего документа.
Вот тут и приходят на помощь трансформеры. Я не буду рассказывать про их крутость и магию, происходящую под капотом, тем более читатель недоумевает и наверняка ждет, когда же я все-таки начну рассказывать про ChatGPT.
Самое главное, что из энкодера трансформера можно вытащить как отдельные эмбеддинги слов (при чем здесь они будут уже контекстно-зависимыми), так и векторное представление предложения.
На практике очень хорошо себя показал фреймворк SentenceTransformers. С его помощью можно векторизовать ваш документ несколькими строчками кода:
from sentence_transformers import SentenceTransformer
# импортируем мультиязычную модель
model = SentenceTransformer('distiluse-base-multilingual-cased-v2')
sentence = 'Мама мыла раму'
# получаем эмбеддинг
embedding = model.encode(sentence)
SentenceTransformers отличная штука, но, как и все хорошее, имеет свои изъяны. Главный из них – ограничение на длину последовательности. По умолчанию это 128 токенов. Можно в принципе увеличить это значение вплоть до 512, но этого все равно не хватит, чтобы векторизовать большой текст. Пример ниже показывает, что при этом происходит.
sentence_1 = 'Мама мыла раму' * 64
sentence_2 = 'Мама мыла раму' * 128
embeddings = model.encode([sentence_1, sentence_2])
print((embeddings[0] == embeddings[1]).all())
True
На сцену выходит OpenAI
Наконец-то мы добрались до основного блюда. Команда OpenAI помимо web-интерфейса, также открыла доступ к API своих моделек. В том числе можно задействовать и те, что создают текстовые эмбеддинги. Логика тут такая же, как и в SentenceTransformers, но мы предполагаем, что такие векторайзеры задействует гораздо больший контекст.
Если обратиться к документации, то можно увидеть, что максимальная длина входной последовательности существенно выше, чем у SentenceTransformers.

Пора посмотреть, как они справятся с задачей поиска дублей.
- Создадим виртуальное окружение под этот проект
conda create --name open_ai
conda activate open_ai
- Устанавливаем необходимые библиотеки
pip install openai tiktoken juputer scipy pandas fastapi uvicorn
Для работы с openai нам понадобится токен авторизации.
import tiktoken
import openai
from scipy.spatial.distance import cosine
# Устанавливаем значение ключа
openai.api_key = 'sk-7FUL3uCuviG7F...Kc08xiSoFidB9Us'
# Примеры предложений
sentence_1 = 'мама мыла раму'
sentence_2 = 'мама моет окно'
# Версия модели(это наиболее современная)
model = 'text-embedding-ada-002'
# Создаем эмбеддинги
embedding_1 = openai.Embedding.create( input=sentence_1, model=model)
embedding_2 = openai.Embedding.create( input=sentence_2, model=model)
# Смотрим на близость, в данном случае считается как 1-cos
distance = cosine(embedding_1['data'][0]['embedding'], embedding_2['data'][0]['embedding'])
print(distance)
0.11193540954120007
Посмотрим, как она справляется с длинными последовательностями.
sentence_1 = '''
В январе Генеральная прокуратура Германии в рамках расследования диверсии на газопроводах «Северный поток» проводила обыск
на подозрительном судне, которое предположительно перевозило взрывчатку, пишет Die Welt со ссылкой на заявление ведомства.
Подробностей, кто и зачем перевозил ее, ведомство не приводит. В ответ на запрос ТАСС в Генпрокуратуре указали, что продолжают
анализировать улики и не могут говорить о причастности к подрыву какого-либо государства. Судно, по данным ведомства,
было арендовано у компании из ФРГ, но ее сотрудники вне подозрений.
Ранее газета Die Zeit сообщила, что немецкие следственные органы идентифицировали яхту,
которая, вероятно, использовалась при совершении взрыва на «Северных потоках» 26 сентября прошлого года.
'''
sentence_2 = '''
Власти ФРГ инициировали обыск корабля, предположительно имеющего отношение к диверсиям на газопроводах «Северный поток»
и «Северный поток – 2». Об этом 8 марта сообщает агентство DPA со ссылкой на Генеральную прокуратуру в Карлсруэ.
Согласно информации ведомства, судно могло быть использовано для перевозки взрывчатых веществ.
«С 18 по 20 января 2023 года федеральная прокуратура обыскала судно в связи с подозрительной его арендой.
Есть подозрение, что рассматриваемое судно могло использоваться для перевозки взрывных устройств,
взорвавшихся 26 сентября 2022 года на газопроводах «Северный поток» 1 и 2 в Балтийском море»,
— сообщили в прокуратуре агентству «РИА Новости».
Отмечается, что на данный момент изъят ряд вещдоков, проводится их проверка. Личности преступников
и их мотивы являются предметом продолжающихся расследований.
«Достоверных доказательств по этому поводу, особенно по вопросу государственного контроля,
в настоящее время нет. Никаких подозрений в отношении сотрудников немецкой компании,
сдавшей судно в аренду, нет», — заключили в прокуратуре.
'''
# Энкодер для подсчета количества токенов
encoding = tiktoken.get_encoding('cl100k_base')
num_tokens_1 = len(encoding.encode(sentence_1))
num_tokens_2 = len(encoding.encode(sentence_2))
embedding_1 = openai.Embedding.create(
input=sentence_1,
model=model
)
embedding_2 = openai.Embedding.create(
input=sentence_2,
model=model
)
distance = cosine(
embedding_1['data'][0]['embedding'],
embedding_2['data'][0]['embedding']
)
print(
f'sentence_1 num tokens: {num_tokens_1}\\n'
f'sentence_2 num tokens: {num_tokens_2}\\n'
f'cos distance: {distance}'
)
sentence_1 num tokens: 347
sentence_2 num tokens: 492
cos distance: 0.06688715737425832
Для похожих по смыслу новостей, но с разной лексикой и разным размером, модель выдает адекватное значение косинусного расстояния. Что ж, видимо, ребята из Калифорнии все-таки не зря едят свой хлеб со смузи.
По коням
Пора собирать работающий пайплайн. Необходимые ингридиенты:
- Корпус уникальных текстов. Чтобы проверить наш пример на уникальность, мы будем сравнивать его с каждым документом из корпуса. Парсить ничего не будем, возьмем готовый датасет с huggingface.
- Код для поиска потенциальных дублей.
- API-интерфейс для работы с нашим микросервисом.
На вход мы будем подавать список примеров, на выходе оценка уникальности:
api_input = {
"ITEMS": [
doc1,
doc2,
doc3
]
}
api_output = [
{
"estimation": 1,
"score": 0.3,
"duplicates": []
},
{
"estimation": 0,
"score": 0.03,
"duplicates": [original1, original2]
},
{
"estimation": 1,
"score": 0.41,
"duplicates": []
},
]
Датасет
Скачанный архив весит 3.5 ГБ. Это может оказаться серьезным вызовом для вашей оперативки, кроме того, поиск в большом корпусе будет занимать слишком много времени (сейчас пока пропустим возможные способы оптимизации этого процесса). Сейчас наша задача выкатить MVP (minimal viable product), поэтому ограничимся батчем в 10к постов.
import pandas as pd
import pickle
# Создаем итератор для побатчевой загрузки, возможно потребуется установка стандарта zstd(pip install zstandard)
habr = pd.read_json(
'habr.jsonl.zst',
lines=True,
chunksize=10**4,
compression='zstd'
)
# Забираем первый батч
habr_chunk = next(habr)
print(habr_chunk.shape)
(10000, 22)

В сете 22 колонки, но нам столько не понадобится. Наиболее важные для нас:
text_markdown– собственно сам текст поста.lead_markdown– хедер поста (первые несколько предложений).title– заголовок.
Для поиска дубликатов пока можно ограничиться только text_markdown, в дальнейшем можно будет задействовать и другие поля.
Получение эмбеддингов
Выше я указывал, что модель способна принимать на вход свыше 8k токенов, однако если ваш текст превысит это значение, то API упадет с ошибкой. Перед отправкой будем производить подсчет и обрезать наши тексты.
def get_embeddings(
texts: list,
model: str = 'text-embedding-ada-002',
chunksize: int = 100,
max_tokens: int = 8192,
cut_coef: float = 0.8
) -> list:
"""
Функция принимает список текстов и возвращает список эмбеддингов, используя модель от OpenAI. Список разбивается на куски размером chunksize, а затем функция вычисляет количество токенов каждого текста, используя энкодер cl100k_base. Если количество токенов превышает max_tokens,текст укорачивается на cut_coef.
Аргументы:
df (pd.DataFrame): pandas DataFrame, содержащий текстовые данные
model (str по умолчанию text-embedding-ada-002): модель векторизации
chunksize(int по умолчанию 100): размер кусков, на которые разбиваются входные данные
max_tokens (int по умолчанию 8192): максимальное количество токенов, разрешенное на один текст
cut_coef (float по умолчанию 0.8): коэффициент, используемый для определения количества текста для обрезки, если оно превышает max_tokens
Возвращает:
список эмбеддингов
"""
embeddings_all = []
encoding = tiktoken.get_encoding('cl100k_base')
@retry(wait=wait_random_exponential(min=1, max=10), stop=stop_after_attempt(5)) # обработчик запросов
def api_request(texts, model):
return openai.Embedding.create(input=texts, model=model)
for i in range(0, len(texts), chunksize):
processed_texts = []
texts_chunk = texts[i:i + chunksize]
for text in texts_chunk:
if not text:
text = 'default'
num_tokens = len(encoding.encode(text))
if num_tokens > max_tokens:
len_text = len(text)
cut_trh = int(max_tokens / num_tokens * len_text * cut_coef)
text = text[:cut_trh]
processed_texts.append(text)
embeddings = api_request(processed_texts, model)
for embedding in embeddings['data']:
embeddings_all.append(embedding['embedding'])
if (i % 1000 == 0) & (i != 0):
print(f'processed {i} texts')
return embeddings_all
Эмбеддинги записываем в датасет и сохраняем.
embeddings_all = get_embeddings(habr_chunk.text_markdown.values.tolist())
habr_chunk['embedding'] = embeddings_all
with open('habr_chunk.pickle', 'wb') as f:
pickle.dump(habr_chunk[['text_markdown', 'embedding']], f
База данных уникальных постов у нас есть. Правда, мы никак не проверили их на уникальность. Пока отправим эту задачу в бэклог.
Поиск дублей
def find_duplicates(candidates: list, df: pd.DataFrame, n_similar: int = 5, thrh: float = 0.1) -> list:
'''
Функция находит дубликаты текстовых фрагментов для списка candidates на основе сходства эмбеддингов, вычисленных с помощью функции get_embeddings, и базы данных в виде pandas.DataFrame. Функция возвращает список, содержащий оценку, близость и список похожих фрагментов для каждого текстового фрагмента из candidates.
Аргументы:
candidates (list): список текстовых фрагментов для поиска дубликатов
df (pd.DataFrame): база данных в формате pandas.DataFrame, содержащая эмбеддинги и текстовые фрагменты для сравнения с candidates
n_similar (int, по умолчанию 5): количество похожих фрагментов, которые будут возвращены для каждого текста candidates
thrh (float, по умолчанию 0.1): пороговое значение, используемое для определения того, что два эмбеддинга достаточно похожи.
Возвращает:
список словарей с оценкой, косинусной близостью и списком дубликатов.
'''
embeddings = get_embeddings(candidates)
processed_candidates = []
for embedding in embeddings:
checked_candidat = {
"estimation": 0,
"score": None,
"duplicates": []
}
distances = np.array(
[cosine(embedding, e) for e in df.embedding.values]
)
under_treshold = distances < thrh
if under_treshold.sum() == 0:
processed_candidates.append(checked_candidat)
else:
checked_candidat["estimation"] = 1
checked_candidat["score"] = min(distances)
checked_candidat["duplicates"] = df.iloc[
under_treshold
].text_markdown.values[:n_similar].tolist()
processed_candidates.append(checked_candidat)
return processed_candidates
Микросервис крутится
Все детальки микросервиса готовы, осталось соединить их вместе и передать FastAPI. Для удобства создадим пакет utils, в него поместим код для получения векторов и поиска по постам.
mkdir utils
touch utils/__init__.py utils/search.py app.py
В search.py скопируем код для эмбеддингов и поиска, в app.py приложение FastAPI, оно предельно простое.
import os
import pickle
from fastapi import FastAPI
from pydantic import BaseModel
import openai
from utils.search import find_duplicates
# Устанавливаем значение ключа(так лучше не хранить!!!)
openai.api_key = 'sk-7F...idB9Us'
# Название файла с уникальными постами
habr_masters_path = 'habr_chunk.pickle'
# Создаем экземпляр fastapi
app = FastAPI(title='Deduplication App')
# Для валидации данных создаем модель данных
class Candidat(BaseModel):
ITEM: list
# Подгружаем датафрейм с постами
with open(os.path.join(os.path.dirname(__file__), habr_masters_path), 'rb') as f:
df = pickle.load(f)
# Обработчик для входящих сообщений
@app.post('/predict')
async def make_predictions(request: Candidat):
if not request.ITEM:
request.ITEM.append('dafault')
processed_candidates = find_duplicates(request.ITEM, df)
return processed_candidates
Done!
Чтобы запустить приложение, запускаем сервер uvicorn.
uvicorn app:app --reload
В случае успеха вы должны увидеть что-то похожее на это:
INFO: Will watch for changes in these directories: ['/Users/m.konakov/Desktop/search_duplicates']
INFO: Uvicorn running on <http://127.0.0.1:8000> (Press CTRL+C to quit)
INFO: Started reloader process [24198] using StatReload
INFO: Started server process [24200]
INFO: Waiting for application startup.
INFO: Application startup complete.
Крутость FastAPI не только в быстроте, но и в удобстве отладки. Перейдя по адресу http://127.0.0.1:8000/docs, вы должны попасть в swagger. Swagger – это фреймворк, предоставляющий возможность не только просматривать спецификацию RESTful API интерактивно, но и отправлять запросы и проверять ответы.
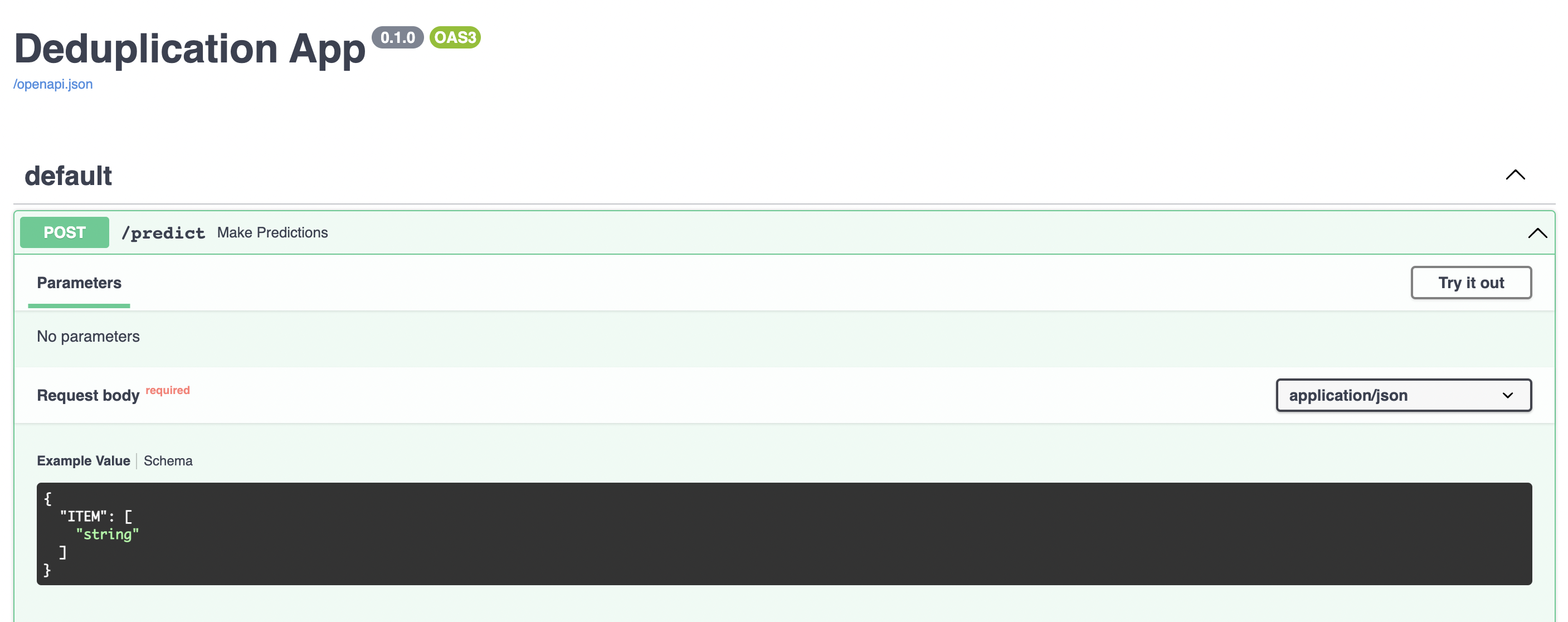
В список ITEM можно помещать своих кандидатов на дубли. Возьмем, для примера, хедер какого-нибудь поста. По-хорошему, стоит ждать, что модель должна нам вернуть полный текст в качестве дубликата.
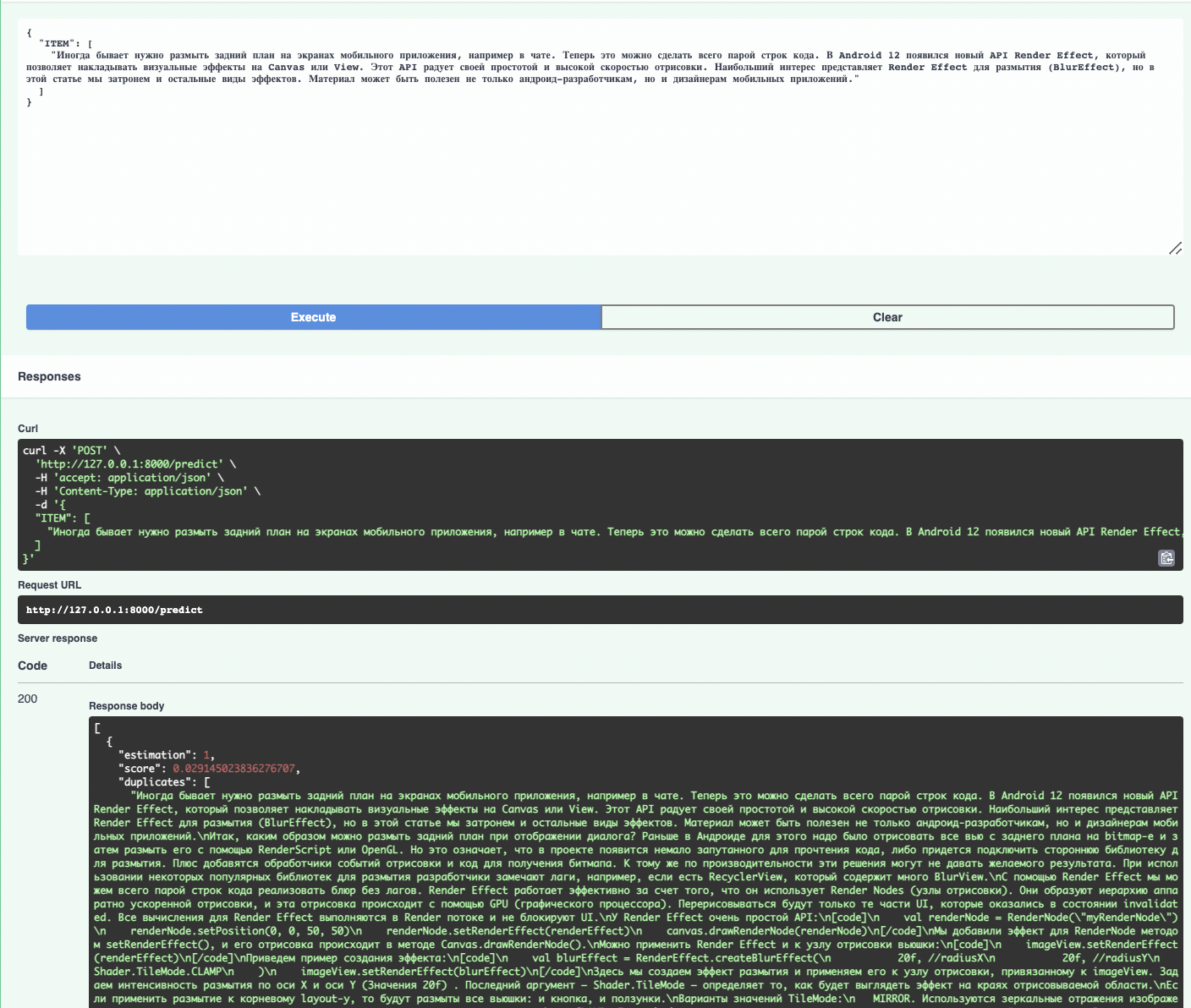
К счастью, наши ожидания не оказались нашими проблемами.
Заключение
Дедубликация понятная и на первый взгляд довольно простая проблема. Но решая ее, можно открыть для себя множество крутых и ценных идей, которые будут полезны во множестве других задач. В статье я постарался раскрыть базовые подходы, без существенного погружения в детали, но надеюсь, что кого-то это вдохновит к собственным поискам. Спасибо за внимание!
Комментарии