

В мире, в котором NFT продаются за миллионы долларов, следующим прибыльным бизнесом может стать создание уникальных виртуальных сущностей, и кто же лучше выполнит эту работу, чем искусственный интеллект? Фактически задолго до бума NFT, в октябре 2018-го, первый портрет, сгенерированный ИИ, был продан за $432.500. С этого момента люди использовали свое глубокое знание передовых алгоритмов для создания потрясающих предметов искусства. Например, Рефик Анадол – художник, использующий ИИ для создания захватывающих картин (ознакомиться с его работами можно по этой ссылке). Другой цифровой художник, Петрос Вреллис, в 2012 году выставил интерактивную анимацию знаменитой работы Ван Гога «Звездная ночь», которая собрала более 1.5 миллиона просмотров за три месяца.
Однако творческие возможности ИИ не ограничиваются живописью. Люди создают интеллектуальные системы, способные писать стихи, песни, сценарии, и, возможно, делать и другую творческую работу. Движемся ли мы к миру, в котором всем творческим людям придется конкурировать с компьютерами? Возможно, но это не то, что я собирался обсудить. Моя цель – погрузиться в принципы работы элегантного алгоритма нейронного переноса стиля (neural style transfer), способного превратить даже ужасных художников вроде меня в виртуозов.
1. Идея нейронного переноса стиля
Любое изображение можно разделить на две составляющие: содержание и стиль. Содержание – это хитросплетение объектов, а стиль – это общая тема. Эти составляющие можно также интерпретировать как локальные и глобальные сущности в изображении. Например, на приведенном ниже изображении содержание – это детализированный дизайн Эйфелевой башни, а тени заднего плана (голубое небо, зеленые деревья и трава) создают стиль (тему).

Идея нейронного переноса стиля (NST) в том, чтобы взять одно изображение и переделать его содержимое в стиле какого-нибудь другого изображения. Перенос темы (стиля) с более привлекательного изображения – такого, как знаменитая картина «Звездная ночь» Ван Гога – может привести к потрясающим переделкам.

Давайте детально обсудим показанную выше трансформацию.
2. Сверточные нейронные сети для переноса стиля
Поскольку мы работаем с изображениями, вас не должно удивлять, что основным механизмом переноса стиля являются сверточные нейронные сети. Также, поскольку множество сверточных нейронных сетей добились прекрасных результатов в задачах обработки изображений, нам не придется обучать отдельную сеть для переноса стиля. Я использую сеть VGG-19 (transfer learning для переноса стиля), но вы можете использовать любую другую предобученную сеть или обучить свою.
Сеть VGG-19 имеет следующую архитектуру:
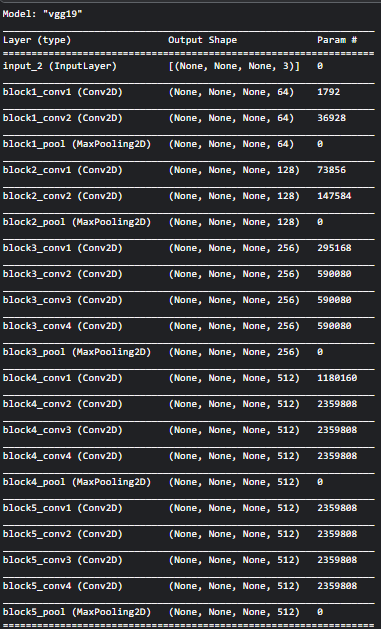
Для начала давайте посмотрим, что распознают некоторые из этих слоев. В каждом слое есть не менее 64 фильтров, выделяющих признаки из изображений. Для простоты мы используем выходы первых десяти слоев, чтобы увидеть, чему они обучаются. Если вы хотите увидеть код, смотрите его на Kaggle либо в GitHub.
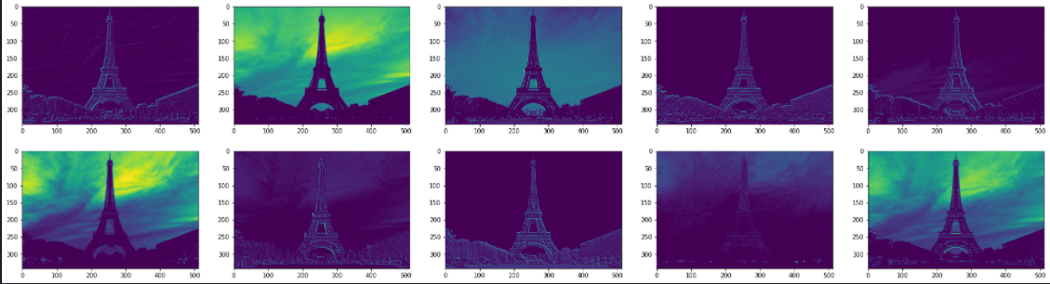
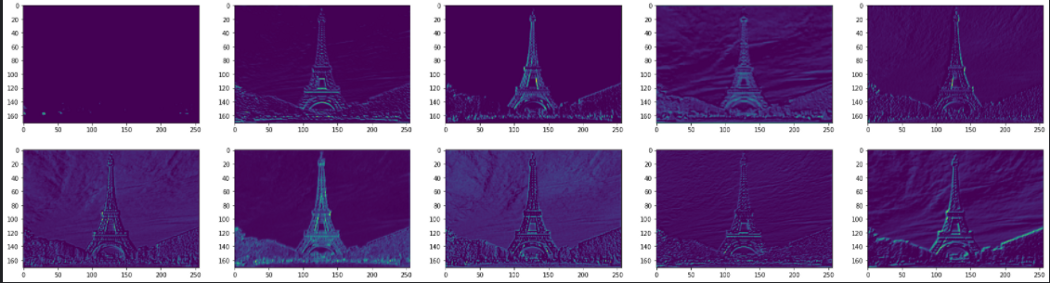

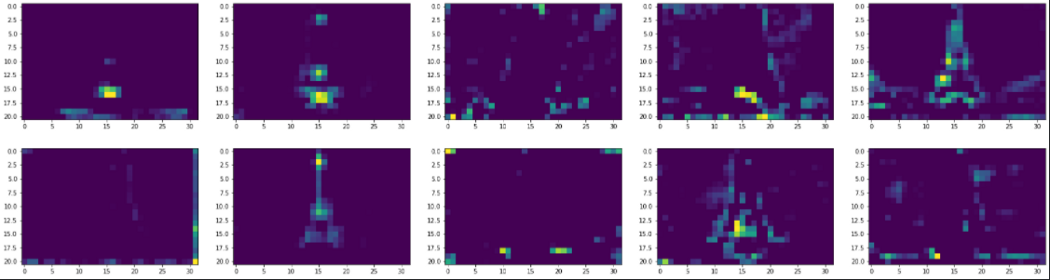
Что мы можем понять из этих схем? Похоже, начальные слои идентифицируют общий контекст изображения (глобальные параметры). Эти слои, похоже, распознают углы и цвета глобально, и поэтому их выводы похожи на исходное изображение. Это похоже на обвод карандашом объектов фотографии на приложенной папиросной бумаге: возможно, вы и не получите точных деталей каждого обведенного объекта, но получите точное представление об этих объектах.
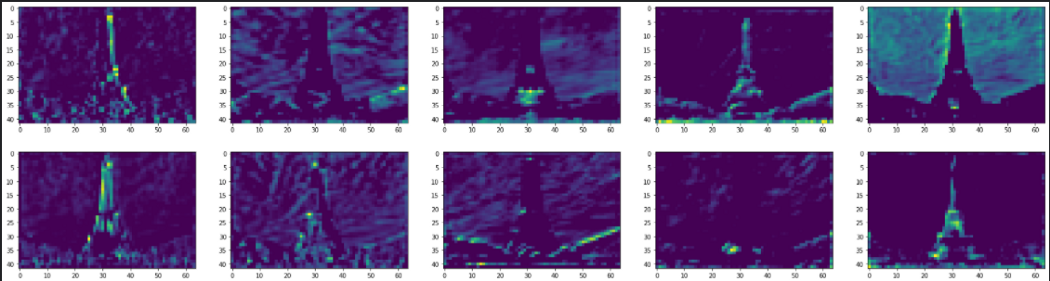
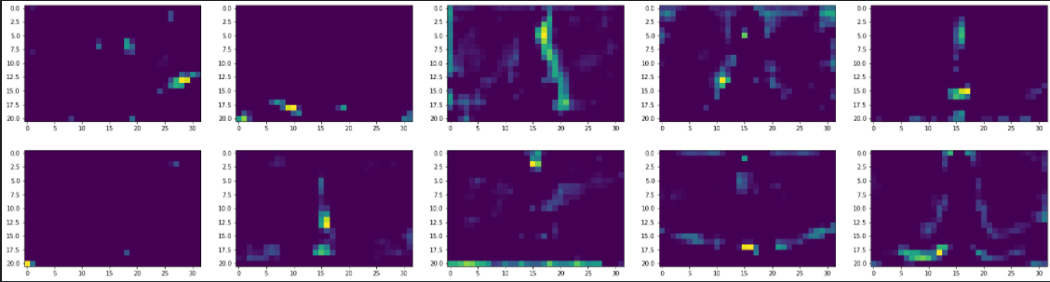
Затем, по мере прохождения изображения по нейронной сети, выходы слоев размываются. Выходы фильтров этих слоев, особенно block_5_conv_2 (последний), фокусируются на конкретных локациях и извлекают информацию о формах различных объектов. Например, два следующих фильтра интересуются мелкими деталями Эйфелевой башни. Возможно, в задаче классификации такие локальные признаки помогли бы сверточной нейронной сети отличить Эйфелеву башню от любого другого здания похожей структуры – например, от опоры ЛЭП.
Разделимость глобальных и локальных компонентов изображения при обработке с помощью сверточных нейронных сетей – именно то, что лежит в основе передачи стиля. Авторы нейронного алгоритма художественного стиля и оригинальной статьи о нейронной передаче стиля (Гейтис и пр.) сообщают, что поскольку глубокие слои хорошо идентифицируют детализированные признаки, они используются для получения содержимого изображения. Аналогично, начальные слои, способные хорошо усваивать контуры объектов, используются для получения стиля изображения (темы или глобальных признаков).
3. Создание нового изображения
Наша цель – создание нового изображения, сочетающего содержимое одного изображения и стиль другого. Давайте сначала разберемся с содержимым.
3.1. Информация о содержимом
В прошлом разделе мы установили, что выходы глубоких слоев нейронной сети помогают определить содержимое изображения. Теперь нам нужен алгоритм для получения этого содержимого. Для этого мы используем уже знакомые математические методы: функции потерь (loss) и обратное распространение (backpropagation).

Рассмотрим приведенное выше изображение, состоящее из шума (X). Для простоты примем, что сверточная нейронная сеть, которую мы выбрали для передачи стиля, состоит всего из двух слоев, A1 и A2. Передавая целевое изображение (Y) через сеть и используя выходы A2, A2(A1(Y)), мы получаем информацию о его содержимом. Чтобы изучить/выделить эту информацию, мы передаем X через ту же сеть. Поскольку X состоит из случайно распределенных значений пикселей, A2(A1(X)) также будет случайным. Затем мы определяем функцию потерь содержимого как:
Здесь i и j – обозначения индексов массива изображения (размеры целевого изображения с содержимым и изображения с шумом должны быть одинаковыми). Фактически, если результирующие массивы A2(A1(X)) и A2(A1(Y)) имеют размерность (m, n), функция потерь вычисляет их разницу в каждой точке, возводит ее в квадрат, а потом суммирует все эти квадраты. С помощью такой функции потерь мы заставляем X стать таким изображением, которое выдает такую же информацию о содержимом, что и Y. Мы можем минимизировать потери с помощью обратного распространения, как мы делали это в любой нейронной сети, но есть небольшая разница. В нашем случае обучаемые параметры – не веса нейронной сети, а сам массив X. Вот как выглядит финальное уравнение:
Мы можем расширить эту идею до сети любого размера и выбрать любой подходящий слой, выходы которого мы будем считать содержимым.
3.2. Информация о стиле
Получение информации о стиле сложнее, чем получение информации о содержимом. Оно требует понимания матриц Грама.
3.2.1. Матрицы Грама
Рассмотрев архитектуру VGG-19 (см. пункт 2), вы можете увидеть, что выход слоя block_1_conv_1 имеет размерность (m, n, 64). Для простоты примем, что m,n = 3,2, и количество фильтров тоже равно 2, а не 64.
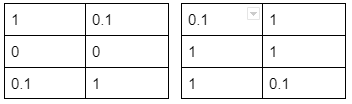
Как вы знаете, фильтры сверточной нейронной сети обучаются распознавать различные пространственные признаки вроде краев/линий, интенсивности цветов и т.д. Давайте скажем, что приведенные выше фильтры распознают оттенки красного и синего цветов в разных локациях. То есть, значение пикселей (от 0 до 1) в каждой ячейке фильтра 1 представляет интенсивность красного цвета в этой локации, а в фильтре 2 – интенсивность синего цвета. Теперь склеим оба выходных массива вместе и умножим результат на его же транспонированное значение. Что мы получим в результате?

Итоговый результат – это матрица корреляции между атрибутами, выделяемыми двумя фильтрами. Если вы проверите выходы наших двух слоев, то увидите, что в локациях, в которых красный цвет более интенсивный, интенсивность синего цвета ниже. Поэтому не-диагональные значения матрицы корреляции (корреляция между красным и синим цветами) меньше. Если мы сейчас изменим пиксели так, чтобы синий и красный цвета встречались вместе, не-диагональные значения вырастут.

Следовательно, матрица Грама, в контексте сверточных сетей – это матрица корреляции между всеми признаками, извлекаемыми всеми фильтрами слоя. Давайте посмотрим, как они помогают в переносе стиля.
3.2.2. Стиль и комбинированные потери

Предположим, мы хотим передать стиль из приведенного выше изображения. Заметьте, что наличие множества полос (вертикальных и горизонтальных линий) голубого цвета, переходящего в белый. Матрицы Грама двух фильтров, обнаруживающих линии и светло-голубой цвет, покажут высокую корреляцию между этими признаками. Следовательно, алгоритм обеспечит, чтобы в реконструированном изображении эти два признака встречались вместе, что прекрасно послужит для передачи стиля. В реальности каждый слой сверточной сети имеет множество фильтров, что приводит к огромным матрицам Грама, но идея остается все той же. Например, матрица Грама для выходов слоя block_1_conv_1 в VGG19, будет матрицей корреляции между 64 признаками.
Затем нам нужно определить функцию потерь для стиля. Предположим, что пропустив наше целевое изображение через block_1_conv_1, мы получили матрицу Грама G. Мы пропускаем через тот же слой наше зашумленное изображение X и рассчитываем ее матрицу Грама P. Тогда потери стиля можно рассчитать так:
Здесь (i,j) – обозначения индексов в матрицах Грама. Минимизируя эту функцию, мы обеспечиваем, что матрица X будет иметь такую же корреляцию между признаками, как наше целевое изображение со стилем.
Заметим, что, в отличие от потерь содержимого, которые рассчитывались для одного слоя, потери стиля рассчитываются для нескольких слоев. Гейтис и пр. использовали для этой цели пять слоев. Таким образом, итоговые потери стиля будут рассчитываться так:
W – это веса, назначенные потерям каждого слоя. Это гиперпараметры, которые можно настраивать, чтобы увидеть, как изменится итоговая композиция. Мы обсудим результаты изменения этих весов, а также использование единственного слоя для передачи стиля в последнем разделе.
Комбинированная функция потерь – это сумма потерь стиля и потерь содержимого. Опять-таки, каждая из этих потерь имеет свой вес. Назначение большего веса потерям стиля заставит результирующее изображение захватывать больше стиля, и наоборот.
4. Изменение гиперпараметров
Наконец, когда мы уже обсудили всю теорию, давайте поэкспериментируем с передачей стиля при разных гиперпараметрах. Код можно найти в блокнотах по ссылкам, приведенным выше. Для справки, функция переноса стиля вызывается со следующими параметрами:
- Путь к изображению с содержимым.
- Список путей к изображениям со стилями.
- Вес потерь содержимого.
- Вес потерь стиля.
- Количество итераций (обратного распространения).
- Список весов для изображений стиля – если вы хотите передать стиль из нескольких изображений, нужно передать вес для каждого изображения стиля.
- Список весов для слоев стиля – веса, назначенные каждому слою, используемые в функции потерь.
Мы используем для своих экспериментов следующие изображения:

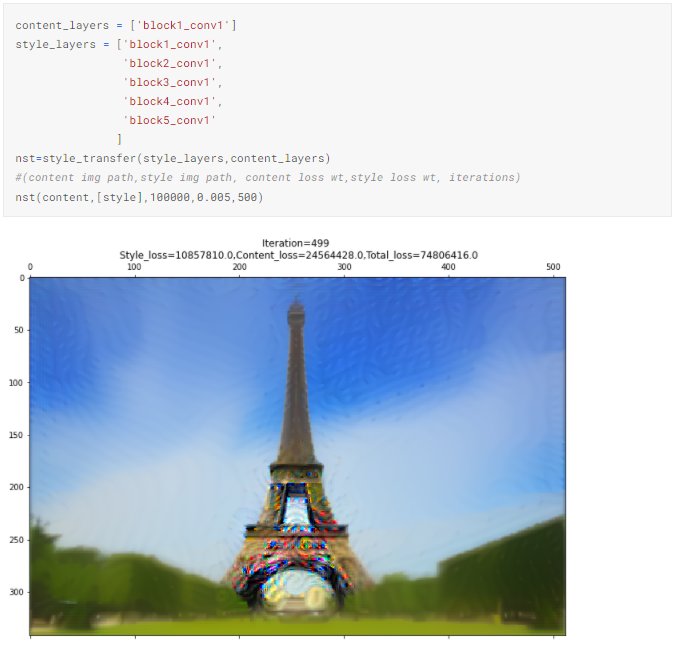
4.1. 5 слоев с одинаковыми весами потерь, 1 слой содержимого
Мы используем это изображение в качестве базового, чтобы сравнить результат изменения гиперпараметров.
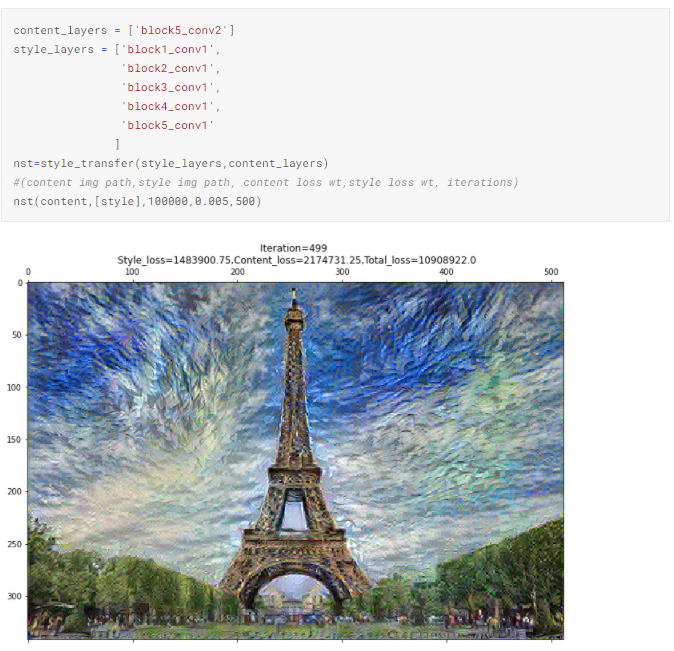
4.2. Повышаем вес функции потерь стиля с 0.005 до 0.1
Как и ожидалось, повышение этого веса заставило алгоритм уделять стилю больше внимания. Поэтому воссозданное изображение содержит лучшую комбинацию желтого и синего цветов.
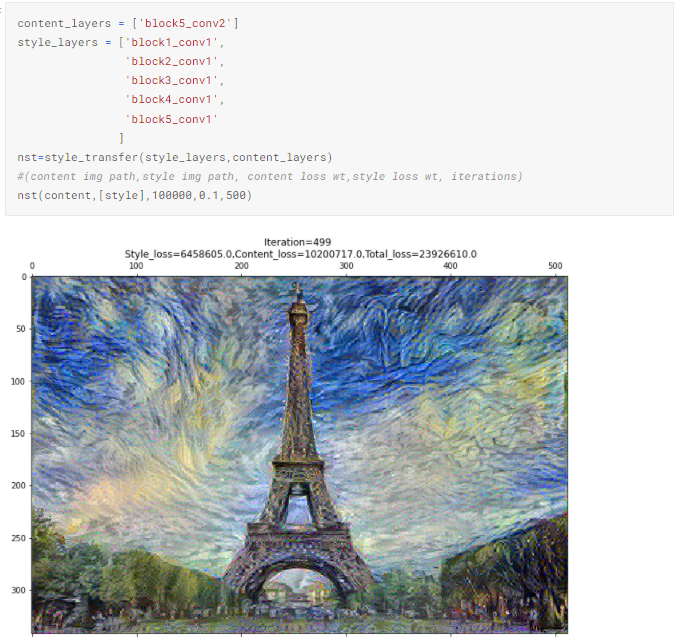
4.3. Используем один слой для стиля
Использование всего одного слоя для потерь стиля не приводит к получению захватывающих изображений. Возможно, из-за того, что стиль состоит из различных теней и пространственных признаков, для его передачи нужны фильтры из разных слоев.
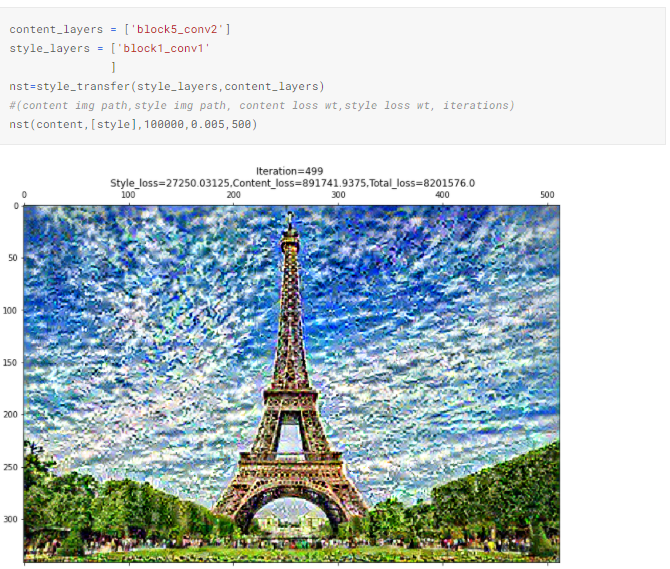
4.4. Используем другой слой в функции потерь содержимого
Использование слоя block_1_conv_1 для информации содержимого заставляет сеть забирать глобальные признаки из целевого изображения содержимого. Это, вероятно, интерферирует с глобальными признаками из изображения стиля, и передача стиля получается ужасной. По-моему, результат демонстрирует, почему для нейронной передачи стиля рекомендуется выбирать глубокие слои. Они концентрируются исключительно на локальных деталях, относящихся к важнейшим объектам в изображении содержимого, что обеспечивает беспрепятственную передачу темы изображения стиля.
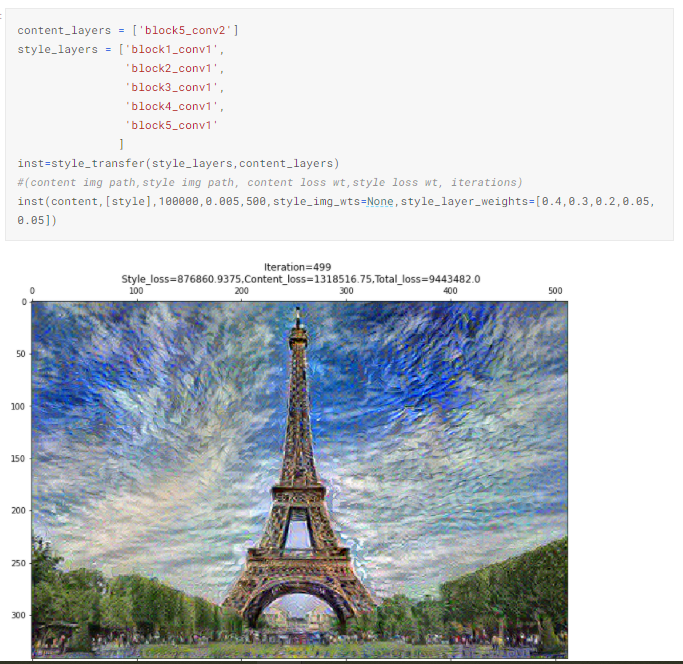
4.5. Назначаем веса слоев стиля вручную [0.4, 0.3, 0.2, 0.05, 0.05]
Хотя разница между изображением из п. 4.1 и этим невелика, мне кажется, что это изображение имеют общую светлую тень. Возможно, это следствие большего веса, назначенного слою block_1_conv_1, что, в соответствии с п. 4.3, генерирует белый тон из картины «Звездная ночь».
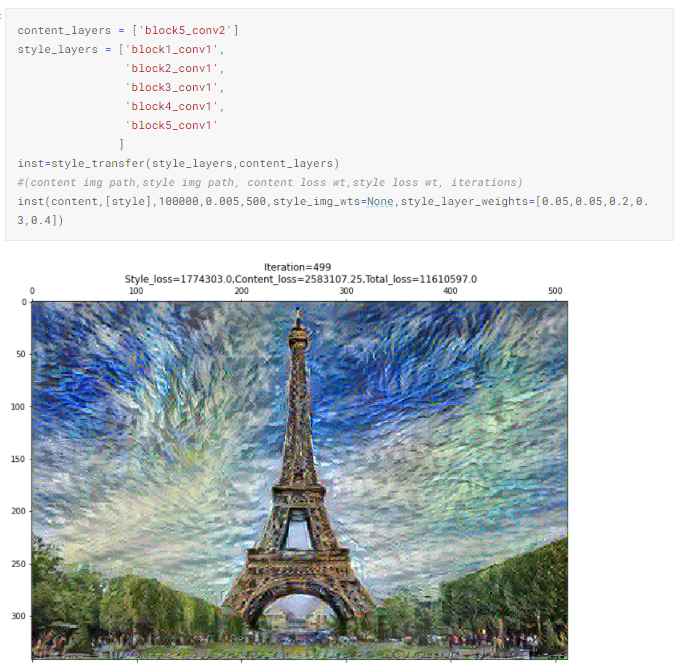
4.6. Назначаем веса слоев стиля вручную [0.05, 0.05, 0.2, 0.3, 0.4]
Это куда более удачная комбинация цветов, чем 4.5. Назначение больших весов глубоким слоям обеспечивает гораздо более привлекательные результаты. Возможно, матрицы Грама для этих слоев вычисляют корреляцию между более доминантными глобальными признаками из «Звездной ночи».
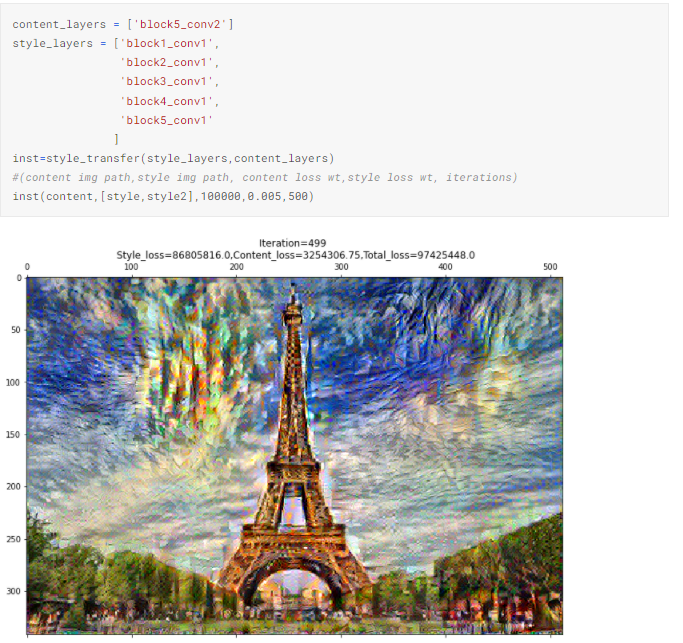
4.7. Передача стиля из нескольких изображений
Наконец, давайте применим стили сразу из нескольких изображений, чтобы получить более красивые комбинации. Для этого придется внести небольшие изменения в функцию потерь. Потеря стиля для каждого изображения остается такой же, как в п. 3.2.2:
Однако, общая функция потерь выглядит вот так:
Теперь, как мы уже делали, назначим веса потерям стиля для каждого изображения и просуммируем их.
5. Заметки
На этом я заканчиваю статью. Приглашаю вас провести больше экспериментов с приведенным кодом. Кроме того, я реализовал этот алгоритм с нуля, и должен существовать более эффективный вариант. Лучший оптимизатор точно должен улучшить качество. Надеюсь, генерация изображений с помощью нейронных сетей вас развлекла. Комбинация передачи стиля с генеративными состязательными сетями – заманчивое предложение, и я надеюсь рассмотреть эту тему в будущем.
Комментарии