

В каких задачах используется?
Благодаря своей гибкости Random Forest применяется для решения практически любых проблем в области машинного обучения. Сюда относятся классификации (RandomForestClassifier) и регрессии (RandomForestRegressor), а также более сложные задачи, вроде отбора признаков, поиска выбросов/аномалий и кластеризации.
Основным полем для применения алгоритма случайного дерева являются первые два пункта, решение других задач строится уже на их основе. Так, для задачи отбора признаков мы осуществляем следующий код:
import pandas as pd
from sklearn.ensemble import RandomForestClassfier
from sklearn.feature_selection import SelectFromModel
X_train,y_train,X_test,y_test = train_test_split(data,test_size=0.3)
sel = SelectFromModel(RandomForestClassifier(n_estimators = 100))
sel.fit(X_train, y_train)
Здесь мы на основе классификации просто добавляем метод для отбора признаков.
Порядок действий в алгоритме
- Загрузите ваши данные.
- В заданном наборе данных определите случайную выборку.
- Далее алгоритм построит по выборке дерево решений.
- Дерево строится, пока в каждом листе не более n объектов, или пока не будет достигнута определенная высота.
- Затем будет получен результат прогнозирования из каждого дерева решений.
- На этом этапе голосование будет проводиться для каждого прогнозируемого результата: мы выбираем лучший признак, делаем разбиение в дереве по нему и повторяем этот пункт до исчерпания выборки.
- В конце выбирается результат прогноза с наибольшим количеством голосов. Это и есть окончательный результат прогнозирования.
Теоретическая составляющая алгоритма случайного дерева
По сравнению с другими методами машинного обучения, теоретическая часть алгоритма Random Forest проста. У нас нет большого объема теории, необходима только формула итогового классификатора a(x):
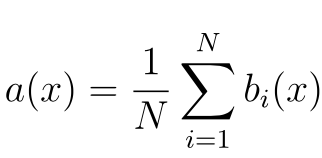
Где
- N – количество деревьев;
- i – счетчик для деревьев;
- b – решающее дерево;
- x – сгенерированная нами на основе данных выборка.
Стоит также отметить, что для задачи классификации мы выбираем решение голосованием по большинству, а в задаче регрессии – средним.
Реализация алгоритма Random Forest
Реализуем алгоритм на простом примере для задачи классификации, используя библиотеку scikit-learn:
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_split=1e-07, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)
Работаем с алгоритмом по стандартному порядку действий, принятому в scikit-learn. Вычисляем AUC-ROC (площадь под кривой ошибок) для тренировочной и тестовой частей модели, чтобы определить ее качество:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import roc_auc_score
# далее - (X, y) - для обучения, (X2, y2) - для контроля
# модель - регрессор
model = RandomForestRegressor(n_estimators=10,
oob_score=True,
random_state=1)
model.fit(X, y) # обучение
a = model.predict(X2) # предсказание
print ("AUC-ROC (oob) = ", roc_auc_score(y, model.oob_prediction_))
print ("AUC-ROC (test) = ", roc_auc_score(y2, a))
Необходимые параметры алгоритма
Число деревьев – n_estimators
Часто при большом увеличении n_estimators качество на обучающей выборке может даже доходить до 100%, в то время как качество на тесте выходит на асимптоту, что сигнализирует о переобучении нашей модели. Лучший способ избежать этого – прикинуть, сколько деревьев вам достаточно, зафиксировав момент, когда качество теста еще не становится стабильно-неизменным.
Критерий расщепления – criterion
gini и entropy. Они соответствуют классическим критериям расщепления: джини и энтропии.В свою очередь, для задач регрессии реализованы два критерия (mse и mae), которые являются функциями ошибок Mean Square Error и Mean Absolute Error соответственно. Практически во всех задачах используется критерий mse.
Простой метод перебора поможет выбрать, что использовать для решения конкретной проблемы.
Число признаков для выбора расщепления – max_features
При увеличении max_features увеличивается время построения леса, а деревья становятся похожими друг на друга. В задачах классификации он по умолчанию равен sqrt(n), в задачах регрессии – n/3.
Минимальное число объектов для расщепления – min_samples_split
Второстепенный по своему значению параметр, его можно оставить в состоянии по умолчанию.
Ограничение числа объектов в листьях – min_samples_leaf
Аналогично с min_samples_split, но при увеличении данного параметра качество модели на обучении падает, в то время как время построения модели сокращается.
Максимальная глубина деревьев – max_depth
Чем меньше максимальная глубина, тем быстрее строится и работает алгоритм случайного дерева.
Неглубокие деревья рекомендуется использовать в задачах со значительным количеством шумовых объектов (выбросов).
Преимущества алгоритма

- Имеет высокую точность предсказания, которая сравнима с результатами градиентного бустинга.
- Не требует тщательной настройки параметров, хорошо работает из коробки.
- Практически не чувствителен к выбросам в данных из-за случайного семплирования (random sample).
- Не чувствителен к масштабированию и к другим монотонным преобразованиям значений признаков.
- Редко переобучается. На практике добавление деревьев только улучшает композицию.
- В случае наличия проблемы переобучения, она преодолевается путем усреднения или объединения результатов различных деревьев решений.
- Способен эффективно обрабатывать данные с большим числом признаков и классов.
- Хорошо работает с пропущенными данными – сохраняет хорошую точность даже при их наличии.
- Одинаково хорошо обрабатывает как непрерывные, так и дискретные признаки
- Высокая параллелизуемость и масштабируемость.
Недостатки алгоритма

- Для реализации алгоритма случайного дерева требуется значительный объем вычислительных ресурсов.
- Большой размер моделей.
- Построение случайного леса отнимает больше времени, чем деревья решений или линейные алгоритмы.
- Алгоритм склонен к переобучению на зашумленных данных.
- Нет формальных выводов, таких как p-values, которые используются для оценки важности переменных.
- В отличие от более простых алгоритмов, результаты случайного леса сложнее интерпретировать.
- Когда в выборке очень много разреженных признаков, таких как тексты или наборы слов (bag of words), алгоритм работает хуже чем линейные методы.
- В отличие от линейной регрессии, Random Forest не обладает возможностью экстраполяции. Это можно считать и плюсом, так как в случае выбросов не будет экстремальных значений.
- Если данные содержат группы признаков с корреляцией, которые имеют схожую значимость для меток, то предпочтение отдается небольшим группам перед большими, что ведет к недообучению.
- Процесс прогнозирования с использованием случайных лесов очень трудоемкий по сравнению с другими алгоритмами.
Заключение
Метод случайного дерева (Random Forest) – это универсальный алгоритм машинного обучения с учителем. Его можно использовать во множестве задач, но в основном он применяется в проблемах классификации и регрессии.
Вы можете использовать случайный лес, если вам нужны чрезвычайно точные результаты или у вас есть огромный объем данных для обработки, и вам нужен достаточно сильный алгоритм, который позволит вам эффективно обработать все данные.
Дополнительные материалы:
- Метод k-ближайших соседей (k-nearest neighbour)
- Numpy, Pandas, matplotlib – необходимый минимум для старта в Machine Learning
- Генеративная состязательная сеть (GAN) для чайников – пошаговое руководство
- Вариационные автоэнкодеры (VAE) для чайников – пошаговое руководство
- Четыре научные статьи о глубоком обучении, которые стоит прочитать в феврале 2021
Комментарии