

Если хочешь подтянуть свои знания, загляни на наш курс «Алгоритмы и структуры данных», на котором ты:
- углубишься в решение практических задач;
- узнаешь все про сложные алгоритмы, сортировки, сжатие данных и многое другое.
Ты также будешь на связи с преподавателем и другими студентами.
В итоге будешь браться за сложные проекты и повысишь чек за свою работу 🙂
Другие статьи цикла:
- Часть 1. Основные понятия и работа с массивами
- Часть 2. Стеки, очереди и связные списки
- Часть 3. Деревья
- Часть 4. Графы
- Часть 6. Полезные алгоритмы для веб-разработки
Ассоциативный массив
В плане эффективности ассоциативные массивы превосходят другие структуры данных: все основные операции в них выполняются за константное время O(1). Например, чтобы добавить новый элемент в середину простого массива, вам придется его переиндексировать (мы говорили об этом в первой части). Сложность этой операции – O(n). В ассоциативном массиве вы просто добавляете новый ключ, с которым связано значение.
Хеш-таблицы
Однако у ассоциативных массивов есть своя слабость – их нельзя положить в память компьютера как есть, в отличие от обычного индексированного массива. Для хранения ассоциативных массивов используется специальная структура – хеш-таблица (hash map).
Ассоциативные массивы – это в некотором смысле синтаксический сахар, более удобная надстройка над хеш-таблицей.
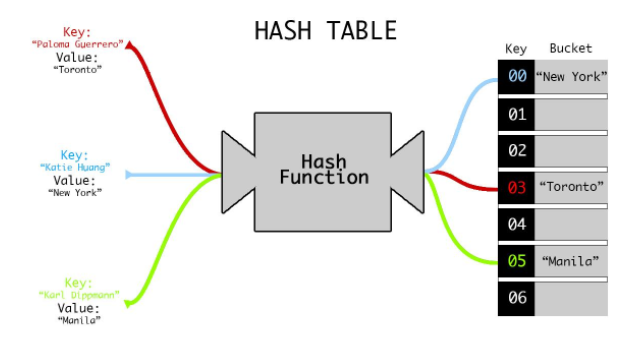
Хеширование
Чтобы превратить ключ ассоциативного массива в индекс обычного, нужно проделать 2 операции:
- Найти хеш (хешировать ключ);
- Привести найденный хеш к индексу результирующего массива.
То есть конечная задача – преобразовать ключ в числовой индекс, но она обычно выполняется в два этапа.
Вычисление хеша
Хеш-функция получает входные данные и преобразует их в хеш – строку или число фиксированной длины. Вы точно слышали о некоторых алгоритмах хеширования: CRC32, MD5 и SHA. Ключ при этом может быть представлен любым типом данных, с которым умеет работать хеш-функция.
0481e0692e2501192d67d7da506c6e70ba41e913. Это хеш, вычисленный для ваших изменений.Реализация хеш-функции может быть самой разной. Например, можно использовать самую простую функцию идентичности, которая принимает входной параметр и возвращает его без изменений:
const hash = key => key;
Если в качестве ключей выступают строки, можно вычислять сумму кодов всех символов:
const hash = string => {
let result = 0;
for (let i = 0; i < string.length; i++) {
result += string.charCodeAt(i);
}
return result;
};
Например, для ключа name хешем будет число 417, а для ключа age – число 301.
Все это не очень хорошие примеры хеш-функций, в реальной жизни они обычно сложнее, но нам важно понять общий принцип. Если вы знаете, с какими данными предстоит работать вашей хеш-таблице, можно подобрать более специфическую хеш-функцию, чем в общем случае.
Важно: для одного и того же входного значения хеш-функция всегда возвращает одинаковый результат.
Приведение к индексу
Обычно размер результирующего массива определяется сразу, следовательно, индекс должен находиться в установленных пределах. Хеш обычно больше индекса, так что его нужно дополнительно преобразовать.
Для вычисления индекса можно использовать остаток от деления хеша на размер массива:
const index = Math.abs(hash) % 5;
Важно помнить, что чем больше длина массива, тем больше места он занимает в памяти.
Воспользуемся нашей хеш-функцией и преобразуем ассоциативный массив в обычный:
// ассоциативный массив
const user = {
name: 'John',
age: 23
};
// обычный массив с длиной 5
[
undefined,
['age', 23],
['name', 'John'],
undefined,
undefined
]
Ключу name соответствует индекс 2, а ключу age – 1.
Мы храним в результирующем массиве не только значения, но и исходные ключи. Зачем это нужно, узнаем очень скоро.
Если теперь мы захотим получить элемент массива с ключом name, то нужно вновь выполнить хеширование этого ключа, чтобы узнать, под каким индексом в массиве располагается связанный с ним элемент.
Коллизии
Вы уже видите слабое место подобных преобразований?
Есть два распространенных варианта решения коллизий.
Открытая адресация
Предположим, что мы передали хеш-функции какой-то ключ ассоциативного массива (key1) и получили от нее 2 – индекс обычного массива, который соответствует этому ключу.
[ undefined, undefined, [key1, value1], undefined, undefined, undefined, undefined ]
Затем мы передаем ей другой ключ – key2 – и вновь получаем 2 – произошла коллизия. Мы не можем записать новые данные под тем же индексом, поэтому мы просто начинаем искать первое свободное место в массиве. Это называется линейное пробирование. Следующий после 2 индекс – 3 – свободен, записываем новые данные в него:
[ undefined, undefined, [key1, value1], [key2, value2], undefined, undefined, undefined ]
Для третьего ключа key3 хеш-функция возвращает индекс 3 – но он уже занят ключом key2, поэтому нам приходится снова искать свободное место.
[ undefined, undefined, [key1, value1], [key2, value2], [key3,value3], undefined, undefined ]
С записью понятно, но как в такой хеш-таблице найти нужный ключ, например, key3? Точно так же, сначала прогоняем его через хеш-функцию и получаем 3. Проверяем элемент массива под этим индексом и видим, что это не тот ключ, который мы ищем. Потому мы и храним исходный ключ в хеш-таблице, чтобы можно было убедиться, что найденный элемент именно тот, который нам нужен. Мы просто начинаем двигаться дальше по массиву, перебирая каждый элемент и сравнивая его с искомым ключом.
Чем плотнее заполнена хеш-таблица, тем больше итераций нужно сделать, чтобы обнаружить ключ, который оказался не на своем месте.
Метод цепочек
В этом подходе значения, соответствующие одному индексу, хранятся в виде связного списка. каждому индексу массива соответствует не один элемент, а целый список элементов, для которых хеш-функция вычислила один индекс. При возникновении коллизии новый элемент просто добавляется в конец списка.
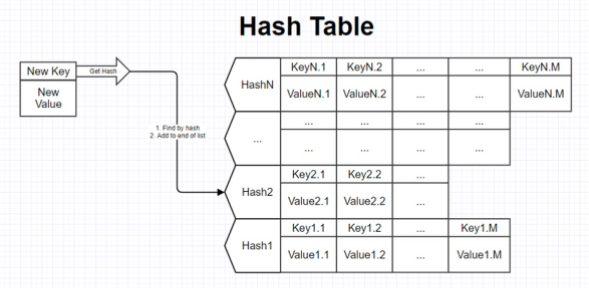
При поиске элемента с конкретным ключом в такой хеш-таблице мы сначала вычисляем его хеш, определяем нужный индекс массива, а затем просматриваем весь список, пока не найдем искомый ключ.
Такая реализация позволяет с легкостью удалять элементы из таблицы, ведь в связном списке операция удаления занимает константное время.
Реализация хеш-таблицы на JavaScript
Хеш-таблица должна реализовывать интерфейс ассоциативного массива, то есть предоставлять три основных метода:
- добавление новой пары ключ-значение;
- поиск значения по ключу;
- удаление пары по ключу.
Чем меньше размер хеш-таблицы (длина массива), тем чаще будут происходить коллизии. Мы возьмем для примера небольшое число – 32. На практике для размера хеш-таблицы часто используются простые числа (которые делятся только на единицу и на себя). Считается, что при этом возникает меньше коллизий.
Для разрешения коллизий будем использовать метод цепочек. Для этого нам потребуется класс связного списка LinkedList, который мы реализовывали во второй статье цикла.
const hashTableSize = 32;
class HashTable {
constructor() {
this.buckets = Array(hashTableSize).fill(null);
}
hash(key) {
let hash = Array.from(key).reduce((sum, key) => {
return sum + key.charCodeAt(0);
}, 0);
return hash % hashTableSize;
}
set(key, value) {
// вычисляем хеш для ключа
let index = this.hash(key);
// если для данного хеша еще нет списка, создаем
if (!this.buckets[index]) {
this.buckets[index] = new LinkedList();
}
let list = this.buckets[index];
// проверяем, не добавлен ли ключ ранее
let node = list.find((nodeValue) => {
nodeValue.key === key;
});
if (node) {
node.value.value = value; // обновляем значение для ключа
} else {
list.append({ key, value }); // добавляем новый элемент в конец списка
}
}
get(key) {
// вычисляем хеш для ключа
let index = this.hash(key);
// находим в массиве соответствующий список
let list = this.buckets[index];
if (!list) return undefined;
// ищем в списке элемент с нужным ключом
let node = list.find((nodeValue) => {
return nodeValue.key === key;
});
if (node) return node.value.value;
return undefined;
}
delete(key) {
let index = this.hash(key);
let list = this.buckets[index];
if (!list) return;
let node = list.find((nodeValue) => nodeValue.key === key);
if (!node) return;
list.delete(node.value);
}
}
Эффективность основных операций в хеш-таблице
Основные операции в хеш-таблице состоят из двух этапов:
- вычисление хеша для ключа и проверка элемента, соответствующего этому хешу в итоговом массиве.
- перебор других элементов, если нужный не нашелся сразу.
Первый этап всегда занимает константное время, второй – линейное, то есть зависит от количества элементов, которые нужно перебрать.
Эффективность хеш-таблицы зависит от трех основных факторов:
- Хеш-функция, которая вычисляет индексы для ключей. В идеале она должна распределять индексы равномерно по массиву;
- Размер самой таблицы – чем он больше, тем меньше коллизий;
- Метод разрешения коллизий. Например, метод цепочек позволяет свести операцию добавления нового элемента к константному времени.
В конечном итоге, чем меньше коллизий, тем эффективнее работает таблица, так как не требуется перебирать много элементов, если искомый не нашелся сразу по хешу. В целом, эффективность хеш-таблицы выше, чем у других структур данных.
Использование хеш-таблиц
В JavaScript хеш-таблицы в чистом виде используются довольно редко. Обычно всю их работу успешно выполняют обычные объекты (ассоциативные массивы) или более сложные Map. При этом на более низком уровне(интерпретация программы) для представления объектов как раз используются хеш-таблицы.
Объекты и хеш-таблицы часто используются в качестве вспомогательных структур при оптимизации различных действий. Например, для подсчета количества вхождений разных символов в строку.
function countSymbols(string) {
const hash = {};
[...string].forEach(s => {
let symbol = s.toLowerCase();
if (!(symbol in hash)) hash[symbol] = 0;
hash[symbol]++;
});
return hash;
}
countSymbols('Hello, world!');
/*
{ " ": 1, "!": 1, ",": 1, d: 1, e: 1, h: 1, l: 3, o: 2, r: 1, w: 1 }
*/
Хеширование, кодирование и шифрование
В ряде случаев нам требуется двустороннее преобразование. Например, вы хотите оставить другу секретное сообщение, которое никто, кроме него, не сможет прочесть. Тут на помощь приходят алгоритмы шифрования.
Кроме шифрования есть еще кодирование. Оно близко к шифрованию по сути, но отличается по цели. Кодирование используется для упрощения передачи информации, например, по линиям электросвязи. Ваше сообщение преобразуется в последовательность битов, доставляется получателю по проводу, а на том конце снова восстанавливается. Никакие ключи при этом не используются. Подобные коды не только решают проблему коммуникации, но и часто пытаются бороться с возможными помехами при передаче, то есть обладают способностью восстанавливать повреждения. Один из самых известных кодов – азбука Морзе.
Заключение
Разбираясь с хеш-таблицами, мы в очередной раз убедились, что практически все в программировании делается через… массивы. Вот и ассоциативные объекты под капотом тоже их используют, вычисляя индекс для каждого ключа с помощью хеш-функций.
В последней статье цикла мы разберем еще несколько полезных прикладных алгоритмов для веб-разработки.
Комментарии