

Немного о кодировках
Как известно, компьютер имеет возможность хранить только биты, поэтому для отображения текстовой информации возникла необходимость перевода нулей и единиц в читабельный алфавит. Так возникли первые кодировки текста – таблицы перевода числовых значений в буквы и символы.
На данный момент стандартом является кодировка Unicode из 1 114 112 позиций, разделенных на 17 блоков по 65 536 символов. Все они записываются в шестнадцатеричном представлении с приставкой «U+». Например, латинская буква «a» имеет код «U+0061», русская буква «я» записана как «U+044F».
Исходный код Go определяется как текст в кодировке UTF-8 (Unicode Transformation Format, 8-bit) – стандарт компактного хранения символов Unicode, обладающий обратной совместимостью с ASCII и переменной длиной. Это дает возможность закодировать определенные символы разным количеством байтов. К примеру, в UTF-8 латинский алфавит закодирован одним байтом, а кириллица – двумя. Данная особенность будет иметь значение при вычислении длины строк, что мы увидим в продолжение статьи.
Для более подробного ознакомления с кодировками рекомендуем прочитать статью «Как работают кодировки текста».
Строки
Байты и руны
Тип данных byte в Go представляет псевдоним для беззнакового 8-битного целочисленного типа uint8. Он принимает значения от 0 до 255, поэтому используются для представления ASCII-символов. Слайсы байт широко применяются в различных библиотеках за счет своей производительности и гибкости.
Тип данных rune определяется как псевдоним для типа int32. Руна соответствует коду символа в таблице Unicode. Так, тип символа µ есть руна со значением 0x00b5.
Строковые литералы
Прежде чем приступить к изучению строк, рассмотрим понятие строкового литерала.
Строковый литерал – это константа типа string, которая является результатом слияния последовательности символов. Литералы бывают двух типов – интерпретируемые и необработанные (или сырые).
Интерпретируемые литералы - это символы, заключенные в двойные кавычки вида "". Текст внутри кавычек представляет собой кодировку UTF-8 отдельных символов. Например, символ µ и его записи \xc2\xb5, \u00b5, \U000000B5 определяют два байта 0xc2 0xb5 символа U+00B5 (µ) в кодировке UTF-8:
symbol := "µ"
fmt.Println("\\xc2\\xb5") // µ
fmt.Println("\\u00b5") // µ
fmt.Println("\\U000000B5") // µ
fmt.Printf("%x", symbol) // c2b5
Необработанные (сырые) литералы – это символы, заключенные в двойные кавычки вида ``. Их значением является строка из неявно закодированных в UTF-8 символов. В необработанных строковых литералах, в отличие от интерпретируемых, перевод строки осуществляется явно с использованием enter, а символ \n не имеет специального значения.
Под строками в Go подразумевают интерпретируемые строковые литералы. В дальнейшем будем рассматривать именно их, так как они используются чаще необработанных.
Строки
Строки в Go представляют собой неизменяемую последовательность байтов. Содержимое строки есть не что иное, как слайс байтов ([]byte). Именно по этой причине обращение по индексу строки вернет не символ, а его юникод-значение в десятичной системе счисления:
rusText := "текст"
fmt.Println(rusText[0], rusText[1]) // 209 130
// 209 = D1 и 130 = 82 в 16-ричном представлении,
// D1 82 является кодом буквы "т" в UTF-8
Срез [i:j] возвращает новую строку, которая состоит из байтов исходной, начиная с индекса i и заканчивая индексом j, но исключая его:
str := "текст"
fmt.Println(str[0:2]) // т
fmt.Println(str[0:1]) // �
В последней строке вывода можно заметить странный символ. Дело в том, что функция fmt.Println пытается декодировать часть строки str[0:1], но получает один единственный байт 0xd1, который не соответствует ни единому символу в UTF-8. Поэтому в результате будет выведен специальный заменяющий символ с кодом 0xfffd.
Строки поддерживают сравнение, которое производится по длине и по байтам:
str1 := "Букварь"
str2 := "Буква"
fmt.Println(str1 > str2) // true
str1 = "Кот"
str2 = "кот"
fmt.Println(str1 == str2) // false
str1 = "код"
str2 = "кот"
fmt.Println(str1 > str2) // false
fmt.Println([]byte(str1)) // [208 186 208 190 **208** 180]
fmt.Println([]byte(str2)) // [208 186 208 190 **209** 130]
Поддерживаются также основные операции со строками – конкатенация и интерполяция.
Конкатенация – это операция слияния нескольких объектов (чаще всего строк) в один.
Интерполяция – это операция замены заполнителей строки соответствующими значениями.
Как и во многих других языках программирования, конкатенация строк в Go реализуется с помощью оператора +:
// пример конкатенации строк в Go
str1 := "Привет, "
str2 := "мир!"
fmt.Println(str1 + str2) // Привет, мир!
Интерполяция в Go реализована немного иначе, чем в динамических языках. Она осуществляется с использованием функций пакета fmt:
// пример интерполяции строк в Go
hour := 12
minute := 35
second := 50
time := fmt.Sprintf("Время %d:%d:%d", hour, minute, second)
fmt.Printf("Дата %d-%d-%d\\n", 28, 12, 2023) // Дата 28-12-2023
fmt.Println(time) // Время 12:35:50
Итерация по рунам
Цикл for-range по строке на каждой итерации декодирует одну руну в UTF-8:
rusText := "текст"
for idx, char := range rusText {
fmt.Printf("Руна: %#U с индексом %d\\n", char, idx)
}
fmt.Println("Длина строки:", len(rusText))
На выходе получим Unicode представление каждого символа строки и его индекс:
Руна: U+0442 'т' с индексом 0
Руна: U+0435 'е' с индексом 2
Руна: U+043A 'к' с индексом 4
Руна: U+0441 'с' с индексом 6
Руна: U+0442 'т' с индексом 8
Длина строки: 10
Заметим, что каждая руна здесь занимает два байта, а так как функция len() возвращает количество байтов, занимаемых строкой, а не количество символов, то длина строки в два раза больше ожидаемой – 10 вместо 5. В начале статьи мы уже упоминали о том, что в UTF-8 кириллица занимает два байта, а так как язык Go использует эту кодировку, то на выходе получаем вполне обоснованный результат.
С латинскими символами всё немного иначе:
engText := "text"
for idx, char := range engText {
fmt.Printf("Руна %#U с индексом %d\\n", char, idx)
}
fmt.Println("Длина строки:", len(engText))
На выходе получим ожидаемые значения индексов и длины:
Руна U+0074 't' с индексом 0
Руна U+0065 'e' с индексом 1
Руна U+0078 'x' с индексом 2
Руна U+0074 't' с индексом 3
Длина строки: 4
В общем случае для получения корректной длины строки следует предварительно преобразовать её в слайс рун или же воспользоваться функцией utf8.RuneCountInString() из пакета unicode/utf8:
str := "текст"
ln := len(str) // 10
correctLen1 := utf8.RuneCountInString(str) // 5
correctLen2 := len([]rune(str)) // 5
Стоит учитывать, что преобразование строки в слайс рун требует немного больше операций и памяти, чем вызов функции utf8.RuneCountInString(). Поэтому с точки зрения производительности эффективнее использовать второй вариант.
Итерация по байтам (индексам)
Как было рассмотрено ранее, обращение напрямую по индексам строки выдаст байтовое представление символов. Это поведение сохраняется при итерации:
rusText := "текст"
for i := 0; i < len(rusText); i++ {
fmt.Printf("%v ", rusText[i])
}
fmt.Println()
// цикл для перевода 10-ричных значений байтов в 16-ричные
for i := 0; i < len(rusText); i++ {
fmt.Printf("%x ", rusText[i])
}
В выводе на верхней строке показано десятичное представление нижних 16-ричных значений символов строки в UTF-8:
209 130 208 181 208 186 209 129 209 130
d1 82 d0 b5 d0 ba d1 81 d1 82
Чтобы вывести корректные символы строки, нужно воспользоваться функцией fmt.Printf и спецификатором %c:
str := "текст"
for _, sym := range str {
fmt.Printf("%c ", sym) // т е к с т
}
Пакет strings
Пакет string стандартной библиотеки содержит полезные функции для работы со строками. Давайте рассмотрим некоторые из них:
- Подсчет вхождений символа в строку –
strings.Count(s, substr string) int:
str := "привет, мир!"
strings.Count(str, "и") // 2
- Замена символов –
strings.Replace(s, old, new string, n int) string:
// последний аргумент - количество замен
// если он < 0, то лимита на количество замен нет
str := "привет, мир!!!"
a := strings.Replace(str, "!", "?", -1) // "привет, мир???"
b := strings.Replace(a, "?", "!", 2) // "привет, мир!!?"
- Разбиение символов по разделителю sep –
strings.Split(s, sep string) []string:
str := "привет, мир!!!"
a := strings.Split(str, ",") // [привет мир!!!]
fmt.Println(a[0]) // привет
- Слияние строк с разделителем sep –
strings.Join(elems []string, sep string) string:
str := []string{"01", "01", "2024"}
strings.Join(str, "-") // 01-01-2024
- Преобразование символов к нижнему или верхнему регистру –
strings.ToLower(s string)илиstrings.ToUpper(s string):
str := "Просто Строка"
strings.ToLower(str) // просто строка
strings.ToUpper(str) // ПРОСТО СТРОКА
Теперь поговорим немного о том, как пакет strings может увеличить производительность. Пусть нам необходимо написать программу для конкатенации большого количества строк. Делать это с помощью оператора + неэффективно, так как при каждой операции будет создаваться новая строка. В этой ситуации стоит воспользоваться структурой Builder из пакета strings:
// количество итераций может быть в разы больше
sb := strings.Builder{}
for i := 0; i < 8; i++ {
sb.WriteString("q")
}
sb.WriteString("end")
fmt.Println(sb.String()) // qqqqqqqqend
Хеш-таблица
После знакомства со строками, рунами и байтами изучим еще один способ хранения информации в программах, облегчающий её поиск.
Хеш-таблица – это структура данных, позволяющая хранить пары ключ-значение и реализующая интерфейс ассоциативного массива. Как правило, она выполняет три основные операции: добавление новой пары, удаление и поиск существующей по ключу.
Заполнение хеш-таблицы происходит с помощью применения специальной хеш-функции к каждому элементу, которая преобразует ключ в индекс ячейки для записи значений.
Доступ к элементу таблицы производится с помощью вычисления хеш-функции от его ключа. Это значение и будет индексом ячейки с искомым элементом.
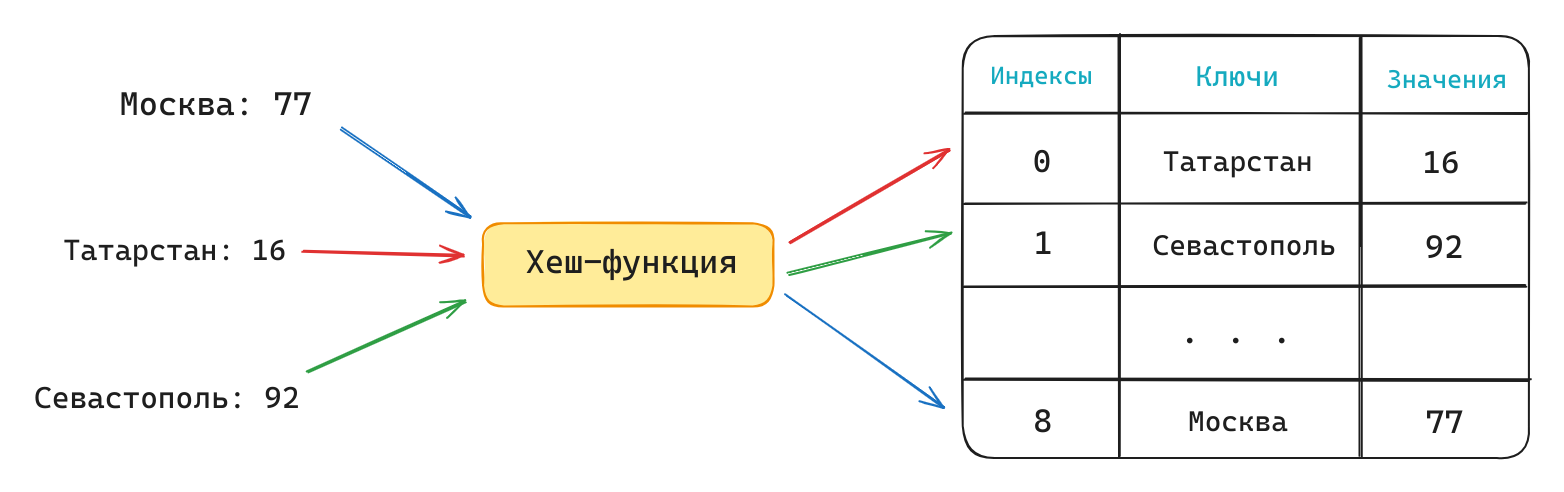
Ситуация, при которой хеш-функция от разных ключей выдает один и тот же индекс, называется коллизией. Чем лучше используемая хеш-функция, тем меньше вероятность возникновения и количество коллизий.
Существует два основных метода разрешения коллизий:
- Метод списков
Данный метод заключается в связывании конфликтующих значений в цепочку-список. В таком случае время поиска в худшем случае будет пропорционально длине списка. Наихудшей ситуацией является хеширование всех n ключей к одной ячейке.
- Метод открытой адресации
В этом подходе все конфликтующие элементы хранятся в самой хеш-таблице без использования списков. При возникновении коллизии производится поиск свободной ячейки для вставки необходимого элемента.
Хеш-таблица (map) в Go
В рамках данной статьи мы не будем углубляться в детали реализации хеш-таблиц в Go. Для полного погружения в тему рекомендуем прочитать следующие материалы: исходный код map, Effective Go: Maps, Мапы в Go: уровень Pro.
Хеш-таблица в Go (также её называют map, мапа, карта) определяется ключевым словом map и создается одним из следующих способов, где keys_type – тип данных ключей, values_type – тип данных значений:
- Предпочтительный способ – с использованием make:
mp := make(map[keys_type]values_type)
- С помощью ключевого слова
varсоздается nil-map:
var mp map[keys_type]values_type
С этим способом нужно быть предельно аккуратным. Если после такого создания мапы попробовать записать значение по ключу, то возникнет panic:
var mp map[string]int
mp["key"] = 1 // panic: assignment to entry in nil map
- С указанием элементов в скобках:
mp := map[keys_type]values_type{
key1: val1,
key2: val2,
}
При этом стоит помнить, что ключами могут быть только сравнимые (comparable) типы данных: числовые (int, float, complex), string, bool, указатель, интерфейс, канал и структуры или массивы, которые содержат значения только этих типов.
Научились создавать мапу, а теперь рассмотрим основные операции над ней:
- Вставка:
mp[key] = value - Удаление:
delete(mp, key) - Поиск:
value := mp[key]
Если в мапе не окажется искомого значения, то вернется нулевое значение типа:
mp := map[int]string{
1: "a",
}
value := mp[2]
fmt.Println(value) // ""
Но стоит помнить, что возвращаемое значение будет nil, если нулевое значение типа также является nil.
Для корректной проверки наличия элемента в мапе используется множественное присваивание. В этом случае возвращается пара – само значение и булевая переменная. Если она равна true, это означает присутствие искомого элемента в мапе, иначе – его отсутствие:
mp := map[int]string{
1:"a",
}
if _, ok := mp[2]; !ok {
fmt.Println("Не найдено") // Не найдено
}
Мапа в Go является неупорядоченной структурой данных. Это значит, что при её обходе в цикле вывод будет разниться от запуска к запуску. Чтобы в этом убедиться, запустите следующий код несколько раз:
mp := map[int]string{
0: "a",
1: "b",
2: "c",
3: "d",
}
for i := range mp {
fmt.Println(mp[i])
}
Передача мапы в функцию
Давайте разберемся с тем, что происходит при передаче мапы в функцию.
Для примера создадим функцию changeMap, которая будет принимать в качестве параметра мапу и изменять в ней значение:
func changeMap(map2 map[int]string) {
map2[1] = "d"
}
func main() {
mp := map[int]string{
0: "a",
1: "b",
2: "c",
}
changeMap(mp)
fmt.Println(mp) // map[0:a 1:d 2:c]
}
В результате можем увидеть, что значение по ключу 1 изменило своё значение.
Не стоит думать, что мапа передалась по ссылке, так как в Go такое поведение отсутствует. Всё дело в том, что мапа в Go является указателем на структуру hmap:
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
Давайте немного изменим код, чтобы map2 в функции changeMap объявлялась с помощью make:
func changeMap(map2 map[int]string) {
map2 = make(map[int]string)
map2[1] = "d"
fmt.Println("Мапа map2 в changeMap:", map2)
}
func main() {
mp := map[int]string{
0: "a",
1: "b",
2: "c",
}
changeMap(mp)
fmt.Println("Мапа mp в main:", mp) // map[0:a 1:d 2:c]
}
В выводе можно заметить, что map2 в changeMap отличается от mp в main:
Мапа map2 в changeMap: map[1:d]
Мапа mp в main: map[0:a 1:b 2:c]
В этом случае мапа mp передается по значению в changeMap, поэтому не меняется. Все изменения коснутся её локальной копии map2, так как создание мапы с помощью make приводит к инициализации hmap.
Подведём итоги
В этой части самоучителя мы узнали о кодировках и их особенностях, на основе этих знаний довольно подробно изучили устройство строк в Go и пакет strings, а в блоке про хеш-таблицы познакомились с эффективным способом хранения пар ключ-значение и методами разрешения коллизий, рассмотрели структуру данных map в Go.
В следующей статье перейдем к изучению объектно-ориентированного программирования и его основных составляющих: структур, интерфейсов и указателей.
Содержание самоучителя
- Особенности и сфера применения Go, установка, настройка
- Ресурсы для изучения Go с нуля
- Организация кода. Пакеты, импорты, модули. Ввод-вывод текста.
- Переменные. Типы данных и их преобразования. Основные операторы
- Условные конструкции if-else и switch-case. Цикл for. Вложенные и бесконечные циклы
- Функции и аргументы. Области видимости. Рекурсия. Defer
- Массивы и слайсы. Append и сopy. Пакет slices
- Строки, руны, байты. Пакет strings. Хеш-таблица (map)
- Структуры и методы. Интерфейсы. Указатели. Основы ООП
- Наследование, абстракция, полиморфизм, инкапсуляция
- Обработка ошибок. Паника. Восстановление. Логирование
- Обобщенное программирование. Дженерики
- Работа с датой и временем. Пакет time
- Интерфейсы ввода-вывода. Буферизация. Работа с файлами. Пакеты io, bufio, os
- Конкурентность. Горутины. Каналы
- Тестирование кода и его виды. Table-driven подход. Параллельные тесты
- Основы сетевого программирования. Стек TCP/IP. Сокеты. Пакет net
- Протокол HTTP. Создание HTTP-сервера и клиента. Пакет net/http
Комментарии