

Веб-скрапинг – это процесс автоматического сбора информации из онлайн-источников. Для выбора нужных сведений из массива «сырых» данных, полученных в ходе скрапинга, нужна дальнейшая обработка – парсинг. В процессе парсинга выполняются синтаксический анализ, разбор и очистка данных. Результат парсинга – очищенные, упорядоченные, структурированные данные, представленные в формате, понятном конечному пользователю (или приложению).
Скрипты для скрапинга создают определенную нагрузку на сайт, с которого они собирают данные – могут, например, посылать чрезмерное количество GET запросов к серверу. Это одна из причин, по которой скрапинг относится к спорным видам деятельности. Чтобы не выходить за рамки сетевого этикета, необходимо всегда соблюдать главные правила сбора публичной информации:
- Если на сайте есть API, нужно запрашивать данные у него.
- Частота и количество GET запросов должны быть разумными.
- Следует передавать информацию о клиенте в
User-Agent. - Если на сайте есть личные данные пользователей, необходимо учитывать настройки приватности в robots.txt.
Необходимо отметить, что универсальных рецептов скрапинга и парсинга не существует. Это связано со следующими причинами:
- Некоторые сервисы активно блокируют скраперов. Динамическая смена прокси не всегда помогает решить эту проблему.
- Контент многих современных сайтов генерируется динамически – результат обычного GET запроса из приложения к таким сайтам вернется практически пустым. Эта проблема решается с помощью Selenium WebDriver либо MechanicalSoup, которые имитируют действия браузера и пользователя.
Для извлечения данных со страниц с четкой, стандартной структурой эффективнее использовать язык запросов XPath. И напротив, для получения нужной информации с нестандартных страниц с произвольным синтаксисом лучше использовать средства библиотеки BeautifulSoup. Ниже мы подробно рассмотрим оба подхода.
Примеры скрапинга и парсинга на Python
Экосистема Python располагает множеством инструментов для скрапинга и парсинга. Начнем с самого простого примера – получения веб-страницы и извлечения из ее кода ссылки.
Скрапинг содержимого страницы
Воспользуемся модулем urllib.request стандартной библиотеки urllib для получения исходного кода одностраничного сайта example.com:
from urllib.request import urlopen
url = 'http://example.com'
page = urlopen(url)
print(page.read().decode('utf-8'))
Результат:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
Точно такой же результат можно получить с помощью requests:
from bs4 import BeautifulSoup
import requests
url = 'http://example.com'
res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')
print(soup)
Этот результат – те самые сырые данные, которые нужно обработать (подвергнуть парсингу), чтобы извлечь из них нужную информацию, например, адрес указанной на странице ссылки:
Парсинг полученных данных
Извлечь адрес ссылки можно 4 разными способами – с помощью:
- Методов строк.
- Регулярного выражения.
- Запроса XPath.
- Обработки BeautifulSoup.
Рассмотрим все эти способы по порядку.
Методы строк
Это самый трудоемкий способ – для извлечения каждого элемента нужно определить 2 индекса – начало и конец вхождения. При этом к индексу вхождения надо добавить длину стартового фрагмента:
from urllib.request import urlopen
url = 'http://example.com/'
page = urlopen(url)
html_code = page.read().decode('utf-8')
start = html_code.find('href="') + 6
end = html_code.find('">More')
link = html_code[start:end]
print(link)
Результат:
https://www.iana.org/domains/example
Регулярное выражение
В предыдущей главе мы подробно рассматривали способы извлечения конкретных подстрок из текста. Точно так же регулярные выражения можно использовать для поиска данных в исходном коде страниц:
from urllib.request import urlopen
import re
url = 'http://example.com/'
page = urlopen(url)
html_code = page.read().decode('utf-8')
link = r'(https?://\S+)(?=")'
print(re.findall(link, html_code))
Результат:
https://www.iana.org/domains/example
Запрос XPath
Язык запросов XPath (XML Path Language) позволяет извлекать данные из определенных узлов XML-документа. Для работы с HTML кодом в Python используют модуль etree:
from urllib.request import urlopen
from lxml import etree
url = 'http://example.com/'
page = urlopen(url)
html_code = page.read().decode('utf-8')
tree = etree.HTML(html_code)
print(tree.xpath("/html/body/div/p[2]/a/@href")[0])
Результат:
https://www.iana.org/domains/example
Чтобы узнать путь к нужному элементу страницы, в браузерах Chrome и FireFox надо кликнуть правой кнопкой по элементу и выбрать «Просмотреть код», после чего откроется консоль. В консоли по интересующему элементу нужно еще раз кликнуть правой кнопкой, выбрать «Копировать», а затем – копировать путь XPath:
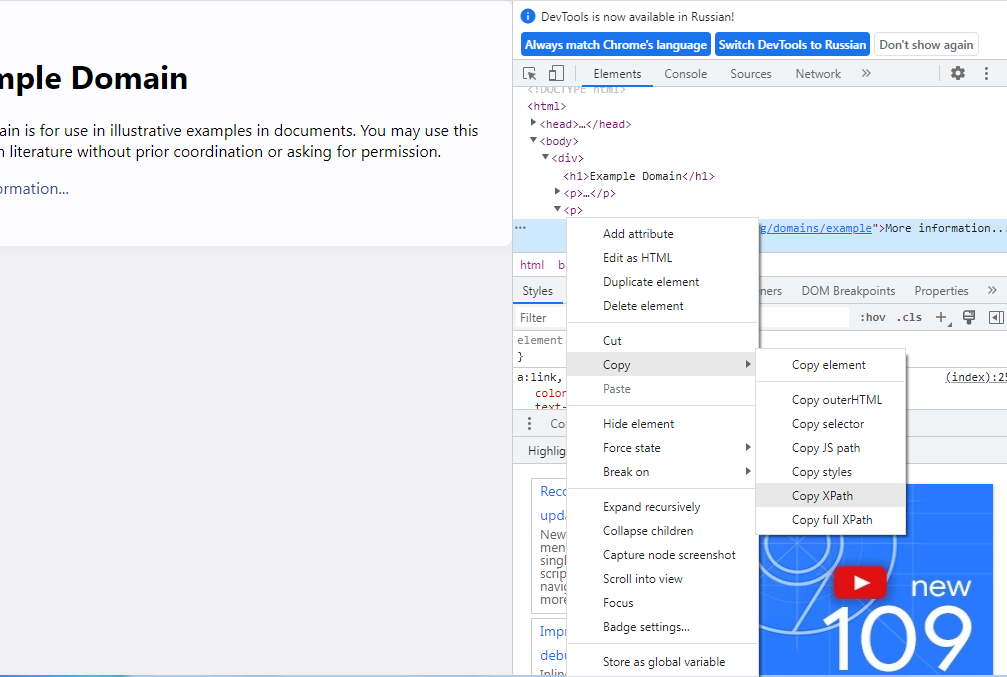
В приведенном выше примере для извлечения ссылки к пути
/html/body/div/p[2]/a/ мы добавили указание для получения значения ссылки @href,
и индекс [0], поскольку результат возвращается в виде списка. Если @href
заменить на text(), программа вернет текст ссылки, а не сам URL:
print(tree.xpath("/html/body/div/p[2]/a/text()")[0])
Результат:
More information...
Парсер BeautifulSoup
Регулярные выражения и XPath предоставляют огромные возможности для извлечения нужной информации из кода страниц, но у них есть свои недостатки: составлять Regex-шаблоны сложно, а запросы XPath хорошо работают только на страницах с безупречной, стандартной структурой. К примеру, страницы Википедии не отличаются идеальной структурой, и использование XPath для извлечения нужной информации из определенных элементов статей, таких как таблицы infobox, часто оказывается неэффективным. В этом случае оптимальным вариантом становится BeautifulSoup, специально разработанный для парсинга HTML-кода.
Библиотека BeautifulSoup не входит в стандартный набор Python, ее нужно установить самостоятельно:
pip install beautifulsoup4
В приведенном ниже примере мы будем извлекать из исходного кода страницы уникальные ссылки, за исключением внутренних:
from bs4 import BeautifulSoup
from urllib.request import urlopen
url = 'https://webscraper.io/test-sites/e-commerce/allinone/phones'
page = urlopen(url)
html = page.read().decode('utf-8')
soup = BeautifulSoup(html, 'html.parser')
links = set()
for link in soup.find_all('a'):
l = link.get('href')
if l != None and l.startswith('https'):
links.add(l)
for link in links:
print(link)
Результат:
https://twitter.com/webscraperio
https://www.facebook.com/webscraperio/
https://forum.webscraper.io/
https://webscraper.io/downloads/Web_Scraper_Media_Kit.zip
https://cloud.webscraper.io/
https://chrome.google.com/webstore/detail/web-scraper/jnhgnonknehpejjnehehllkliplmbmhn?hl=en
При использовании XPath точно такой же результат даст следующий скрипт:
from urllib.request import urlopen
from lxml import etree
url = 'https://webscraper.io/test-sites/e-commerce/allinone/phones'
page = urlopen(url)
html_code = page.read().decode('utf-8')
tree = etree.HTML(html_code)
sp = tree.xpath("//li/a/@href")
links = set()
for link in sp:
if link.startswith('http'):
links.add(link)
for link in links:
print(link)
Имитация действий пользователя в браузере
При скрапинге сайтов очень часто требуется авторизация, нажатие кнопок «Читать дальше», переход по ссылкам, отправка форм, прокручивание ленты и так далее. Отсюда возникает необходимость имитации действий пользователя. Как правило, для этих целей используют Selenium, однако есть и более легкое решение – библиотека MechanicalSoup:
pip install MechanicalSoup
По сути, MechanicalSoup исполняет роль браузера без графического интерфейса. Помимо имитации нужного взаимодействия с элементами страниц, MechanicalSoup также парсит HTML-код, используя для этого все функции BeautifulSoup.
Воспользуемся тестовым сайтом http://httpbin.org/, на котором есть возможность отправки формы заказа пиццы:
import mechanicalsoup
browser = mechanicalsoup.StatefulBrowser()
browser.open("http://httpbin.org/")
browser.follow_link("forms")
browser.select_form('form[action="/post"]')
print(browser.form.print_summary())
В приведенном выше примере браузер MechanicalSoup перешел по внутренней ссылке http://httpbin.org/forms/post и вернул описание полей ввода:
<input name="custname"/>
<input name="custtel" type="tel"/>
<input name="custemail" type="email"/>
<input name="size" type="radio" value="small"/>
<input name="size" type="radio" value="medium"/>
<input name="size" type="radio" value="large"/>
<input name="topping" type="checkbox" value="bacon"/>
<input name="topping" type="checkbox" value="cheese"/>
<input name="topping" type="checkbox" value="onion"/>
<input name="topping" type="checkbox" value="mushroom"/>
<input max="21:00" min="11:00" name="delivery" step="900" type="time"/>
<textarea name="comments"></textarea>
<button>Submit order</button>
Перейдем к имитации заполнения формы:
browser["custname"] = "Best Customer"
browser["custtel"] = "+7 916 123 45 67"
browser["custemail"] = "trex@example.com"
browser["size"] = "large"
browser["topping"] = ("cheese", "mushroom")
browser["comments"] = "Add more cheese, plz. More than the last time!"
Теперь форму можно отправить:
response = browser.submit_selected()
Результат можно вывести с помощью print(response.text):
{
"args": {},
"data": "",
"files": {},
"form": {
"comments": "Add more cheese, plz. More than the last time!",
"custemail": "trex@example.com",
"custname": "Best Customer",
"custtel": "+7 916 123 45 67",
"delivery": "",
"size": "large",
"topping": [
"cheese",
"mushroom"
]
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "191",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"Referer": "http://httpbin.org/forms/post",
"User-Agent": "python-requests/2.28.1 (MechanicalSoup/1.2.0)",
"X-Amzn-Trace-Id": "Root=1-6404d82d-2a9ae95225dddaec1968ccb8"
},
"json": null,
"origin": "86.55.39.89",
"url": "http://httpbin.org/post"
}
Отлично! Вы освоили все основные инструменты для скрапинга статичных сайтов.
Вы умеете скачивать HTML, парсить его с помощью BeautifulSoup и XPath, и даже автоматизировать заполнение веб-форм. Это мощная база для решения множества задач.
Но что делать, если контент на сайте подгружается динамически при прокрутке или нажатии на кнопки? В полной версии урока вы перейдёте на следующий уровень:
- Научитесь управлять реальным браузером с помощью Selenium для скрапинга самых сложных динамических сайтов.
- Напишете 10 полноценных скрапинг-проектов для своего портфолио, собирая данные с Wikipedia, Habr, IMDb и других реальных ресурсов.
Комментарии