

В предыдущих статьях (начало, продолжение) мы постепенно погружались в мир llamaIndex, рассмотрев основные концепции фреймворка и научившись реализовывать ключевые функции чат-бота для работы с базой документов в формате PDF. Сегодня мы переходим к следующему этапу нашего путешествия — изучению ретриверов в llamaIndex и стратегий их использования.
В мире, где данные становятся новой нефтью, эффективные инструменты для их обработки и анализа становятся неотъемлемой частью успешного проекта. Ретриверы в этом контексте выступают не просто как инструмент поиска, но и как средство структурирования больших данных, позволяя быстро и точно находить нужные фрагменты среди обширных и неструктурированных массивов информации.
Ретривер в контексте llamaIndex — это инструмент, задачей которого является поиск наиболее релевантного контекста на основе пользовательского запроса.
В llamaIndex представлены различные типы ретриверов, каждый из которых имеет свои особенности и предназначен для решения конкретных задач.
VectorIndexRetriever
VectorIndexRetriever является основным ретривером для работы с векторными индексами. Он использует векторные представления для поиска наиболее релевантных документов в ответ на запрос пользователя.
from llama_index.retrievers import VectorIndexRetriever
# Создаем ретривер
retriever = VectorIndexRetriever(index) # хотя проще создать index.as_retriever()
# Задаем запрос и ищем релевантные ноды
query = 'С какой организацией заключил договор ТатарГеоCтрой?'
documents = retriever.retrieve(query)
print(f'Количество релевантных нод: {len(documents)}\n\n')
for doc in documents:
print(f'Оценка релевантности: {doc.score}\n')
print(f'Содержание ноды: {doc.node.get_content()[:200]}\n\n')

Если в предыдущих экспериментах мы получали финальный ответ на вопрос, то теперь мы просто ранжируем ноды согласно запросу и выводим наиболее важные (по умолчанию 2), если есть необходимость выводить больше, то можно это указать явно:
retriever = index.as_retriever()
retriever._similarity_top_k = 5
Чтобы отобрать ноды выше определенного скора, можно выполнить постпроцессинг:
from llama_index.indices.postprocessor import SimilarityPostprocessor
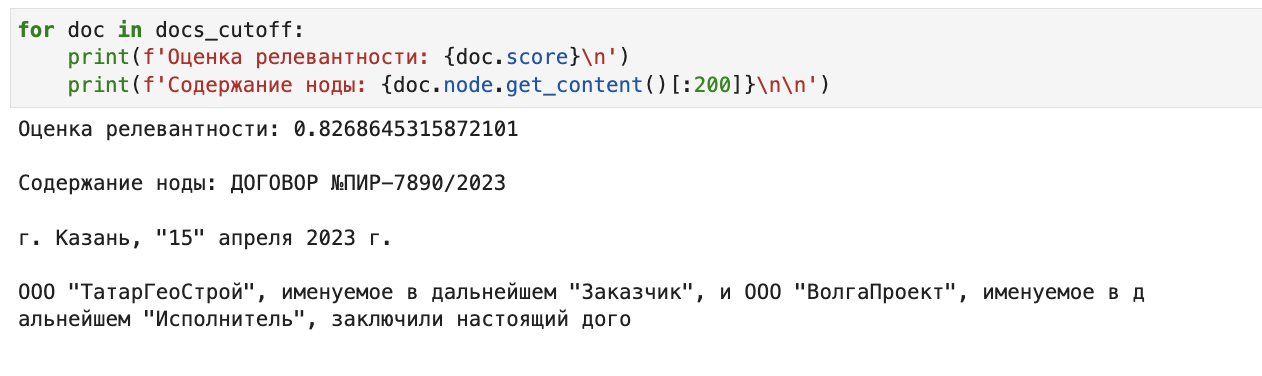
docs_cutoff = SimilarityPostprocessor(similarity_cutoff=0.82).postprocess_nodes(documents)
for doc in docs_cutoff:
print(f'Оценка релевантности: {doc.score}\n')
print(f'Содержание ноды: {doc.node.get_content()[:200]}\n\n')
Добавляем собственный векторайзер
Когда мы получаем оценку релевантности, то мы смотрим на косинусную близость вектора запроса и вектора ноды. По умолчанию используется модель векторизации от OpenAI (поэтому нам и нужен ключ от API). Но что если мы не хотим платить деньги за получение эмбеддингов? Мы можем обучить собственную модель векторизации, которая будет лучше соответствовать нашим задачам.
Llamaindex позволяет добавлять собственные модели для получения эмбеддингов и генерации ответа. Для начала нужно будет поставить в окружение дополнительные пакеты:
pip install InstructorEmbedding torch transformers sentence-transformers
Теперь создаем собственный класс для получения векторов:
from typing import Any, List
from InstructorEmbedding import INSTRUCTOR
from llama_index.embeddings.base import BaseEmbedding
class CustomEmbeddings(BaseEmbedding):
def __init__(
self,
vector_model_name: str = 'distiluse-base-multilingual-cased-v2',
**kwargs: Any
) -> None:
self._model = INSTRUCTOR(vector_model_name)
super().__init__(**kwargs)
def _get_query_embedding(self, query: str) -> List[float]:
embedding = self._model.encode(query)
return embedding
def _get_text_embedding(self, text: str) -> List[float]:
embedding = self._model.encode(text)
return embedding
def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:
embeddings = self._model.encode(texts)
return embeddings
В классе я использовал модель из коробки от sentence-transformers - distiluse-base-multilingual-cased-v2
from llama_index import ServiceContext, GPTVectorStoreIndex
# Читаем наши документы
reader = SimpleDirectoryReader(input_dir='./pir_samples/')
# Настраиваем сервис подачи документов в индекс
service_context = ServiceContext.from_defaults(
embed_model=CustomEmbeddings(), chunk_size=512 # размер ноды должен соотвествовать длине контекста модели
)
# Создаем индекс
index = GPTVectorStoreIndex.from_documents(docs, service_context=service_context)
# Создаем ретривер
retriever = index.as_retriever()
retriever._similarity_top_k = 5
query = 'С какой организацией заключил договор ТатарГеоCтрой?'
documents = retriever.retrieve(query)
print(f'Количество релевантных нод: {len(documents)}\n\n')
for doc in documents:
print(f'Оценка релевантности: {doc.score}\n')
print(f'Содержание ноды: {doc.node.get_content()[:200]}\n\n')

Значение скоров существенно изменились, но тем не менее первая нода осталась той же (она же наиболее релевантная запросу).
Другие типы ретриверов
Llamaindex располагает множеством видов ретриверов, вот полный перечень:
[
"VectorIndexRetriever",
"VectorIndexAutoRetriever",
"SummaryIndexRetriever",
"SummaryIndexEmbeddingRetriever",
"SummaryIndexLLMRetriever",
"KGTableRetriever",
"KnowledgeGraphRAGRetriever",
"EmptyIndexRetriever",
"TreeAllLeafRetriever",
"TreeSelectLeafEmbeddingRetriever",
"TreeSelectLeafRetriever",
"TreeRootRetriever",
"TransformRetriever",
"KeywordTableSimpleRetriever",
"BaseRetriever",
"RecursiveRetriever",
"AutoMergingRetriever",
"RouterRetriever",
"BM25Retriever",
"VectaraRetriever",
# legacy
"ListIndexEmbeddingRetriever",
"ListIndexRetriever",
]
Также есть возможность реализовать собственный тип. Кратко про некоторые типы:
SummaryIndexRetrieverпредназначен для работы с индексами суммаризации, позволяя находить наиболее релевантные саммари для заданного запроса.TreeIndexRetrieverпредназначен для работы с древовидными индексами, обеспечивая эффективный поиск по структурированным данным.KeywordTableRetrieverспециализируется на работе с индексами, основанными на таблицах ключевых слов. Его задачей является извлечение и ранжирование документов на основе ключевых слов из запроса пользователя.
Я не буду разбирать каждый из видов, но для моего типа документов будет полезно рассмотреть BM25Retriever
BM25Retriever
Как нетрудно догадаться, этот ретривер использует алгоритм BM25 для семантического поиска. BM25 — это метод ранжирования документов в поисковых системах, который учитывает важность отдельных слов (токенов) из запроса относительно конкретных документов в корпусе. В отличие от методов, использующих векторные представления для документов, BM25 анализирует и оценивает каждый токен запроса независимо и вычисляет специальный «релевантный» скор для каждого токена относительно каждого документа в корпусе.
Попробуем использовать этот алгоритм для поиска нод:
from llama_index.retrievers import BM25Retriever
from llama_index.response.notebook_utils import display_source_node # утилита для показа содержимого ноды
retriever = BM25Retriever.from_defaults(index, similarity_top_k=3)
query = 'С какой организацией заключил договор ТатарГеоCтрой?'
documents = retriever.retrieve(query)
for doc in documents:
display_source_node(doc)
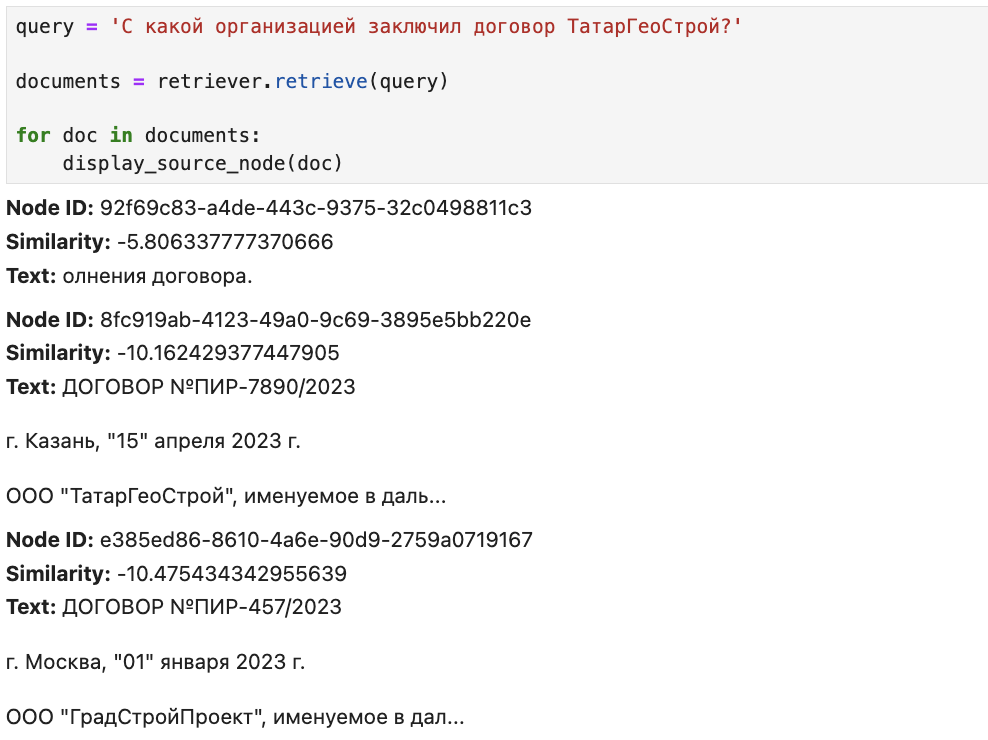
Поиск работает, но нужная нам нода оказалась на втором месте. Еще можно задаться вопросом, почему наши скоры получились отрицательными. Тут нужно вспомнить, что BM25 является вариацией старого доброго TFIDF, и IDF для него считается как log((N – n + 0,5) / (n + 0,5)), где N — это количество документов в корпусе, а n — количество документов, в которых встретился наш токен, т. е. если n > N/2, то логарифм будет отрицательным, соответственно, и весь скор тоже.
Создаем композитный ретривер
Попробуем теперь соединить преимущества двух подходов в одном ретривере. Llamaindex позволяет создавать собственные типы на основе существующих.
from llama_index.retrievers import BaseRetriever, VectorIndexRetriever, BM25Retriever
from llama_index import QueryBundle
from llama_index.schema import NodeWithScore
from typing import List
class CompositeRetriever(BaseRetriever):
def __init__(
self,
vector_retriever: VectorIndexRetriever,
bm25_retriever: BM25Retriever,
mode: str = 'AND'
) -> None:
self._vector_retriever = vector_retriever
self._bm25_retriever = bm25_retriever
if mode not in ('AND', 'OR'):
raise ValueError('Invalid mode.')
self._mode = mode
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
vector_nodes = self._vector_retriever.retrieve(query_bundle)
bm25_nodes = self._bm25_retriever.retrieve(query_bundle)
vector_ids = {n.node.node_id for n in vector_nodes}
bm25_ids = {n.node.node_id for n in bm25_nodes}
combined_dict = {n.node.node_id: n for n in vector_nodes}
combined_dict.update({n.node.node_id: n for n in bm25_nodes})
if self._mode == 'AND':
retrieve_ids = vector_ids.intersection(bm25_ids)
else:
retrieve_ids = vector_ids.union(bm25_ids)
retrieve_nodes = [combined_dict[rid] for rid in retrieve_ids]
return retrieve_nodes
vector_retriever = VectorIndexRetriever(index, similarity_top_k=3)
bm25_retriever = BM25Retriever.from_defaults(index, similarity_top_k=3)
custom_retriever = CompositeRetriever(vector_retriever, bm25_retriever)
query = 'Какова сумма договора с ТатарГеоCтрой?'
documents = custom_retriever.retrieve(query)
for doc in documents:
display_source_node(doc)
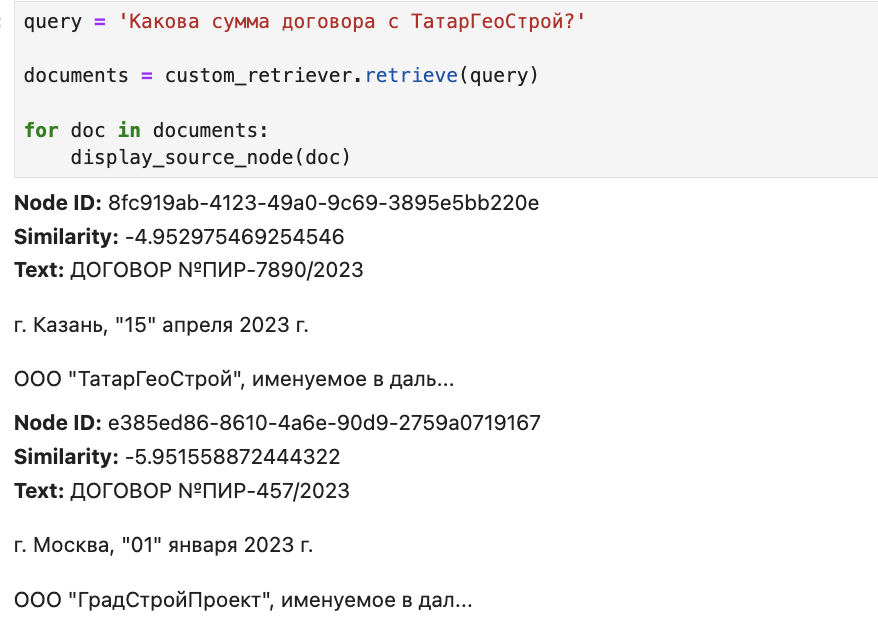
Теперь правильная нода на первом месте. Хотя в нашем примере мы не видим существенного прироста качества, но такой композитный ретривер позволяет дополнительно увеличивать значимость отдельных токенов ноды, которые могут «потеряться» в общем векторе.
На этом обзор ретриверов можно завершать, как, впрочем, и всю серию статей о фреймворке. Я надеюсь, что данная статья поможет вам лучше понять, как эффективно использовать ретриверы в своих проектах на базе llamaIndex. Спасибо за внимание!
Пишу про AI и NLP в телеграм.
Комментарии